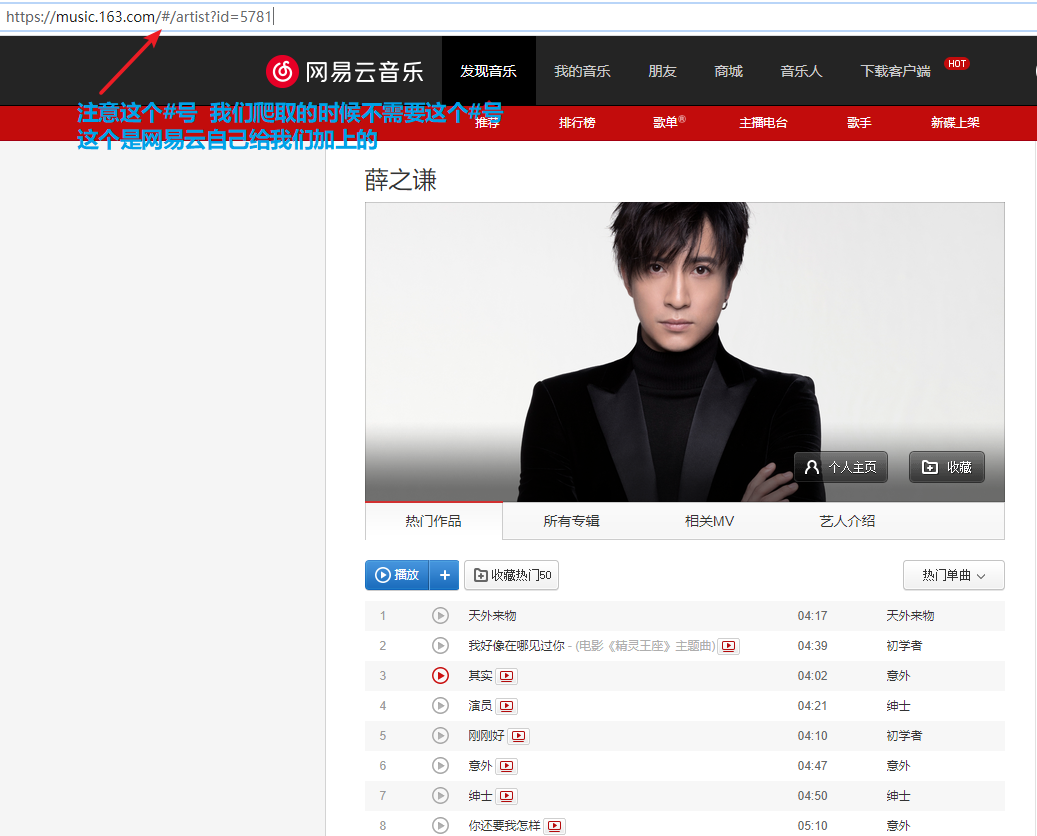
Python 爬取网易云歌手的50首热门作品
使用 requests 爬取网易云音乐
Python 代码:


import json
import os
import time from bs4 import BeautifulSoup
import requests class Music:
"""
下载网易云歌手排行前50的歌曲
""" def __init__(self, init_url, download):
self.init_url = init_url
self.download = download def mkdir(self, path):
"""
创建文件夹
:param path:
:return:
"""
path = path.strip()
if not os.path.exists(path): # 判断此文件夹存不存在
print('创建 ', path, '文件夹')
os.makedirs(path)
return True
else:
print(path, '文件夹已存在,无需创建')
return False def download_video(self, video_url, name):
"""
下载
:param video_url: 音乐的链接
:param name: 歌曲名称
:return:
"""
path = self.download + "\\" + name + '.mp3' # 拼接保存后的文件路径
# print(path)
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36",
}
header = {
"Origin": "http://music.163.com/",
"Referer": video_url, # 请求头必须添加referer
}
headers.update(header) # 更新头部信息
size = 0
start = time.time()
try:
result = requests.get(video_url, headers=headers, stream=True, verify=False)
# print('result', result)
with open(path, "wb") as f:
for chunk in result.iter_content(1024):
f.write(chunk)
f.flush() # 清空缓存
size = size + len(chunk)
print("已下载:%0.2f Mb" % (size / (1024 * 1024)))
except Exception as e:
print("url下载错误:%s" % video_url)
print(e)
stop = time.time()
print("下载完成,耗时:%0.2f秒" % (stop - start)) def spider(self):
r = requests.get(self.init_url).text
soupObj = BeautifulSoup(r, 'lxml')
song_ids = soupObj.find('textarea').text
# print(song_ids)
jobj = json.loads(song_ids)
list01 = []
for item in jobj:
dict01 = {}
# print(item['id']) # 歌曲id
# print(item['name']) # 歌曲名称
dict01['name'] = item['name']
dict01['id'] = item['id']
list01.append(dict01) print(list01)
len_list = len(list01)
print("一共", len_list, "首歌曲")
self.mkdir(self.download)
print('开始切换文件夹')
os.chdir(self.download)
for i in list01:
name = i['name']
id = i['id']
song_url = "http://music.163.com/song/media/outer/url?id=" + str(id) + ".mp3"
print(song_url) # 最终下载的音乐链接
self.download_video(song_url, name) # 下载
len_list = len_list - 1
print("还剩", len_list, "首歌曲需要下载") if __name__ == '__main__':
# init_url = 'https://music.163.com/artist?id=5781' # 薛之谦
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xzq' # 保存地址
# init_url = 'https://music.163.com/artist?id=12429072' # 隔壁老樊
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\gblf' # 保存地址
# init_url = 'https://music.163.com/artist?id=861777' # 华晨宇
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\hcy' # 保存地址
# init_url = 'https://music.163.com/artist?id=6452' # 周杰伦
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\zjl' # 保存地址
# init_url = 'https://music.163.com/artist?id=2116' # 陈奕迅
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\cyx' # 保存地址
# init_url = 'https://music.163.com/artist?id=3684' # 林俊杰
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\ljj' # 保存地址 # init_url = 'https://music.163.com/artist?id=12138269' # 毛不易
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\mby' # 保存地址 # init_url = 'https://music.163.com/artist?id=4292' # 李荣浩
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\lrh' # 保存地址
# init_url = 'https://music.163.com/artist?id=30116848' # 阿冗
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\ar' # 保存地址
# init_url = 'https://music.163.com/artist?id=5771' # 许嵩
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xs' # 保存地址
# init_url = 'https://music.163.com/artist?id=6472' # 张杰
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\zj' # 保存地址
# init_url = 'https://music.163.com/artist?id=5538' # 汪苏泷
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\wsl' # 保存地址
# init_url = 'https://music.163.com/artist?id=1197168' # 徐秉龙
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xbl' # 保存地址
init_url = 'https://music.163.com/artist?id=30284835' # 枯木逢春
download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\kmfc' # 保存地址 s = Music(init_url, download)
s.spider()
"http://music.163.com/song/media/outer/url?id=417859631.mp3" 打开这个链接就可以直接播放音乐 后面的id代表的是歌曲在网易云里面的id
由于网易云有的音乐链接已经弃用,所以有的音乐会下载失败
网易云的许多post请求都是被加密的,如果你们破解不了可以点击这个链接去看看大佬是怎么破解的:https://blog.csdn.net/xiaoming_xiaoli/article/details/88019016
关于网易云api的其他接口可以进去这里面查看:http://www.goodpm.net/postreply/python/1010000008139311/关于网易云音乐爬虫的api接口.html
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
每天一个表情包,给生活加个油

Python 爬取网易云歌手的50首热门作品的更多相关文章
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云歌单
目录 1. 关键点 2. 效果图 3. 源代码 1. 关键点 使用单线程爬取,未登录,爬取网易云歌单主要有三个关键点: url为https://music.163.com/discover/playl ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- python爬取网易云周杰伦所有专辑,歌曲,评论,并完成可视化分析
---恢复内容开始--- 去年在网络上有一篇文章特别有名:我分析42万字的歌词,为搞清楚民谣歌手们在唱些什么.这篇文章的作者是我大学的室友,随后网络上出现了各种以为爬取了XXX,发现了XXX为名的文章 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- python学习之爬虫(一) ——————爬取网易云歌词
接触python也有一段时间了,一提到python,可能大部分pythoner都会想到爬虫,没错,今天我们的话题就是爬虫!作为一个小学生,关于爬虫其实本人也只是略懂,怀着"Done is b ...
随机推荐
- 12 . Kubernetes之Statefulset 和 Operator
Statefulset简介 k8s权威指南这样介绍的 "在Kubernetes系统中,Pod的管理对象RC.Deployment.DaemonSet和Job都面向无状态的服务.但现实中有很多 ...
- 《The Design of a Practical System for Fault-Tolerant Virtual Machines》论文研读
VM-FT 论文研读 说明:本文为论文 <The Design of a Practical System for Fault-Tolerant Virtual Machines> 的个人 ...
- SQLserver-MySQL的区别和用法
对于程序开发人员而言,目前使用最流行的两种后台数据库即为MySQL and SQL Server.这两者最基本的相似之处在于数据存储和属于查询系统.你可以使用SQL来访问这两种数据库的数据,因为它们都 ...
- pandas | 使用pandas进行数据处理——DataFrame篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第二篇文章,我们一起来聊聊pandas当中最重要的数据结构--DataFrame. 上一篇文章当中我们介绍了 ...
- day58 作业
目录 一.做一个图书管理系统页面 二.做一个主页模版 三.点赞 一.做一个图书管理系统页面 <!DOCTYPE html> <html lang="en"> ...
- Set 和 Map
1. 数组去重 <script type="text/javascript"> [...new Set(array)] </script> 2. 条件语句的 ...
- Maven 专题(三):为什么要用Maven
1 真的需要吗? Maven 是干什么用的?这是很多同学在刚开始接触 Maven 时最大的问题.之所以会提出这个问题, 是因为即使不使用 Maven 我们仍然可以进行 B/S 结构项目的开发.从表述层 ...
- flask 源码专题(六):session处理机制
前言 flask_session是flask框架实现session功能的一个插件,用来替代flask自带的session实现机制,flask默认的session信息保存在cookie中,不够安全和灵活 ...
- java 面向对象(十六):Object类的使用
1.java.lang.Object类的说明: * 1.Object类是所Java类的根父类 * 2.如果在类的声明中未使用extends关键字指明其父类,则默认父类为java.lang.Object ...
- 分布式任务调度平台XXL-JOB快速搭建教程
1. XXL-JOB简介 XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速.学习简单.轻量级.易扩展.现已开放源代码并接入多家公司线上产品线,开箱即用.它的有两个核心模块,一个模块叫做 ...