Python实现的数据结构与算法之基本搜索详解
一、顺序搜索
顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败)。
根据列表中的项是否按顺序排列,可以将列表分为 无序列表 和 有序列表。对于 无序列表,超出搜索范围 是指越过列表的末尾;对于 有序列表,超过搜索范围 是指进入列表中大于目标项的区域(发生在目标项小于列表末尾项时)或者指越过列表的末尾(发生在目标项大于列表末尾项时)。
1、无序列表
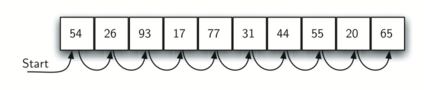
在无序列表中进行顺序搜索的情况如图所示:
def sequentialSearch(items, target):
for item in items:
if item == target:
return True
return False
2、有序列表
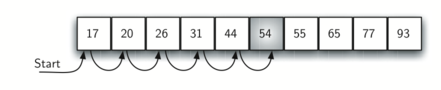
在有序列表中进行顺序搜索的情况如图所示:
def orderedSequentialSearch(items, target):
for item in items:
if item == target:
return True
elif item > target:
break
return False
二、二分搜索
实际上,上述orderedSequentialSearch算法并没有很好地利用有序列表的特点。
二分搜索 充分利用了有序列表的优势,该算法的思路非常巧妙:在原列表中,将目标项(target)与列表中间项(middle)进行对比,如果target等于middle,则搜索成功;如果target小于middle,则在middle的左半列表中继续搜索;如果target大于middle,则在middle的右半列表中继续搜索。
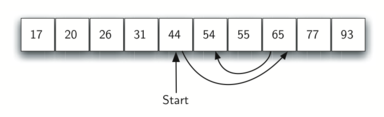
在有序列表中进行二分搜索的情况如图所示:
根据实现方式的不同,二分搜索算法可以分为迭代版本和递归版本两种:
1、迭代版本
def iterativeBinarySearch(items, target):
first = 0
last = len(items) - 1
while first <= last:
middle = (first + last) // 2
if target == items[middle]:
return True
elif target < items[middle]:
last = middle - 1
else:
first = middle + 1
return False
2、递归版本
def recursiveBinarySearch(items, target):
if len(items) == 0:
return False
else:
middle = len(items) // 2
if target == items[middle]:
return True
elif target < items[middle]:
return recursiveBinarySearch(items[:middle], target)
else:
return recursiveBinarySearch(items[middle+1:], target)
三、性能比较
上述搜索算法的时间复杂度如下所示:
搜索算法 时间复杂度
-----------------------------------
sequentialSearch O(n)
-----------------------------------
orderedSequentialSearch O(n)
-----------------------------------
iterativeBinarySearch O(log n)
-----------------------------------
recursiveBinarySearch O(log n)
-----------------------------------
in O(n)
可以看出,二分搜索 的性能要优于 顺序搜索。
值得注意的是,Python的成员操作符 in 的时间复杂度是O(n),不难猜出,操作符 in 实际采用的是 顺序搜索 算法。
四、算法测试
# -*- coding: utf-8 -*-
def test_print(algorithm, listname, target):
print(' %d is%s in %s' % (target, '' if algorithm(eval(listname), target) else ' not', listname))
if __name__ == '__main__':
testlist = [1, 2, 32, 8, 17, 19, 42, 13, 0]
orderedlist = sorted(testlist)
print('sequentialSearch:')
test_print(sequentialSearch, 'testlist', 3)
test_print(sequentialSearch, 'testlist', 13)
print('orderedSequentialSearch:')
test_print(orderedSequentialSearch, 'orderedlist', 3)
test_print(orderedSequentialSearch, 'orderedlist', 13)
print('iterativeBinarySearch:')
test_print(iterativeBinarySearch, 'orderedlist', 3)
test_print(iterativeBinarySearch, 'orderedlist', 13)
print('recursiveBinarySearch:')
test_print(recursiveBinarySearch, 'orderedlist', 3)
test_print(recursiveBinarySearch, 'orderedlist', 13)
运行结果:
$ python testbasicsearch.py
sequentialSearch:
3 is not in testlist
13 is in testlist
orderedSequentialSearch:
3 is not in orderedlist
13 is in orderedlist
iterativeBinarySearch:
3 is not in orderedlist
13 is in orderedlist
recursiveBinarySearch:
3 is not in orderedlist
13 is in orderedlist
Python实现的数据结构与算法之基本搜索详解的更多相关文章
- 用Python实现的数据结构与算法:基本搜索
一.顺序搜索 顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败). 根据列表中的项是否按顺序排列,可以将列表分 ...
- 用Python实现的数据结构与算法:开篇
一.概述 用Python实现的数据结构与算法 涵盖了常用的数据结构与算法(全部由Python语言实现),是 Problem Solving with Algorithms and Data Struc ...
- Python实现的数据结构与算法之队列详解
本文实例讲述了Python实现的数据结构与算法之队列.分享给大家供大家参考.具体分析如下: 一.概述 队列(Queue)是一种先进先出(FIFO)的线性数据结构,插入操作在队尾(rear)进行,删除操 ...
- python 排序算法总结及实例详解
python 排序算法总结及实例详解 这篇文章主要介绍了python排序算法总结及实例详解的相关资料,需要的朋友可以参考下 总结了一下常见集中排序的算法 排序算法总结及实例详解"> 归 ...
- python中日志logging模块的性能及多进程详解
python中日志logging模块的性能及多进程详解 使用Python来写后台任务时,时常需要使用输出日志来记录程序运行的状态,并在发生错误时将错误的详细信息保存下来,以别调试和分析.Python的 ...
- 数据结构图文解析之:队列详解与C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- Python操作redis系列以 哈希(Hash)命令详解(四)
# -*- coding: utf-8 -*- import redis #这个redis不能用,请根据自己的需要修改 r =redis.Redis(host=") 1. Hset 命令用于 ...
- SSD算法及Caffe代码详解(最详细版本)
SSD(single shot multibox detector)算法及Caffe代码详解 https://blog.csdn.net/u014380165/article/details/7282 ...
- Python中第三方库Requests库的高级用法详解
Python中第三方库Requests库的高级用法详解 虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人实在感觉不好.它已经不适合现在的时代, ...
随机推荐
- android开发 app闪退后fragment重叠bug解决方法,推荐使用第二种方法,完美解决问题
解决方案为以下两种: 方法1:在fragmentActivity里oncreate方法判断savedInstanceState==null才生成新Fragment,否则不做处理. 方法2:在fragm ...
- Timeline Event
https://forum.unity.com/threads/timeline-events.479400/
- KUDU 学习笔记
Kudu 现存系统针对结构化数据存储与查询的一些痛点问题,结构化数据的存储,通常包含如下两种方式: 静态数据通常以Parquet/Carbon/Avro形式直接存放在HDFS中,吞吐能力大,适合离线分 ...
- vant ui TabBar封装
TabBar.vue基本上是放在App.vue里面,都存在 <template> <div id="app"> <home-tab-bar :tar- ...
- Codeforces Round #668 (Div. 2)A-C题解
A. Permutation Forgery 题目:http://codeforces.com/contest/1405/problem/A 题解:这道题初看有点吓人,一开始居然想到要用全排序,没错我 ...
- Selenium文件上传问题
- Repeater每行绑定事件代码
if (e.Item.ItemType == ListItemType.Item || e.Item.ItemType == ListItemType.AlternatingItem) { Repea ...
- nginx系列(七)静态文件合并combo
根据雅虎性能优化准则,可以将大量的小型JS文件进行合并,用来提高WEB服务器的性能.下面就是笔者的一个实践. 目前必须安装在1.4.+才可以 官方:http://wiki.nginx.org/Http ...
- 一篇文章教你快速上手接口管理工具swagger
一.关于swagger 1.什么是swagger? swagger是spring fox的一套产品,可以作为后端开发者测试接口的工具,也可以作为前端取数据的接口文档. 2.为什么使用? 相比于传统的接 ...
- 关于如何设置IDEA中的servlet的模板
关于如何设置IDEA中的servlet的模板 点击左上角的File: Setting --> Editor --> File and Code Templates --> Other ...