HADOOP HA 报错 - 所有 namenode 都是standby --集群报错: Operation category READ is not supported in state standby
报错:

经过查看集群的jps如下:
==================== hadoop01 jps ===================
FsShell
ResourceManager
NameNode
Jps
==================== hadoop02 jps ===================
NodeManager
DataNode
JournalNode
QuorumPeerMain
Jps
==================== hadoop03 jps ===================
NodeManager
DataNode
JournalNode
QuorumPeerMain
Jps
==================== hadoop04 jps ===================
JournalNode
QuorumPeerMain
Jps
NodeManager
DataNode
==================== hadoop05 jps ===================
Jps
NameNode
查看日志:
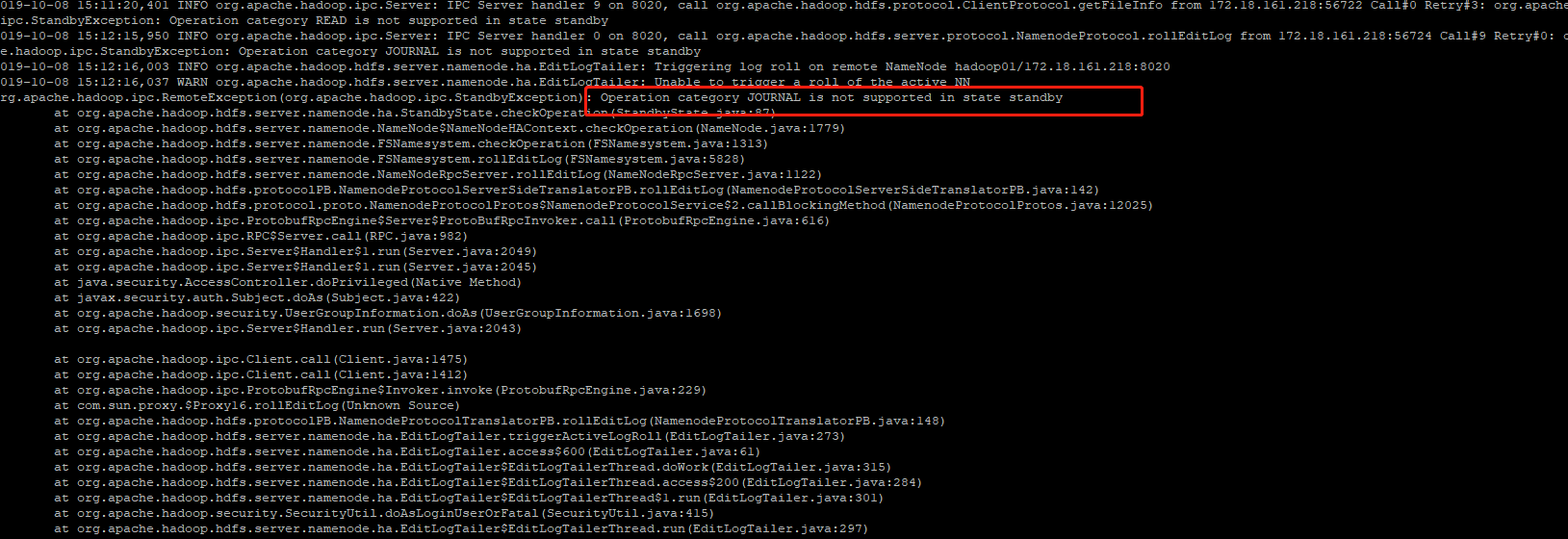
状况:
所有namenode都是standby,即ZK服务未生效
尝试一:手动强制转化某个namenode为active
操作:在某台namenode上,执行 hdfs haadmin -transitionToActive --forcemanual nn1 (nn1是你的某台nameservice-id)
结果:nn1被成功转为active。但是在stop-dfs.sh后再一次start-dfs.sh后,所有namenode仍然都是standby
结论:果然因该是ZK的问题
尝试二:初始化ZK
操作:在某台namenode上,执行 hdfs zkfc -formatZK

结果:重新 start-dfs.sh后,一切正常
NOTE: Zk初始化必须要启动ZK,否则报错

HADOOP HA 报错 - 所有 namenode 都是standby --集群报错: Operation category READ is not supported in state standby的更多相关文章
- Namenode启动报错Operation category JOURNAL is not supported in state standby
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category JO ...
- hadoop错误Operation category READ is not supported in state standby
报如下错误 解决方法: 方法一:(结果不起作用) 通过Shell命令方式,hadoop/bin/hdfs haadmin -failover --forceactive hadoop2 hadoop1 ...
- HADOOP HA 踩坑 - 所有 namenode 都是standby
报错: 无明显报错 状况: 所有namenode都是standby,即ZK服务未生效 尝试一:手动强制转化某个namenode为active 操作:在某台namenode上,执行 hdfs haadm ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- dfs.datanode.max.xcievers参数导致hbase集群报错
2013/08/09 转发自http://bkeep.blog.163.com/blog/static/123414290201272644422987/ [案例]dfs.datanode.max.x ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- quartz集群报错but has failed to stop it. This is very likely to create a memory leak.
quartz集群报错but has failed to stop it. This is very likely to create a memory leak. 在一台配置1核2G内存的阿里云服务器 ...
- redis集群报错
写入redis集群报错:(error) MOVED 6918 解决方法:redis-cli -c -p 7001 -h 10.0.0.104
- nginx集群报错“upstream”directive is not allow here 错误
nginx集群报错“upstream”directive is not allow here 错误 搭建了一个服务器, 采用的是nginx + apache(多个) + php + mysql(两个) ...
随机推荐
- C语言Ⅰ博客作业10
这个作业属于那个课程 C语言程序设计II 这个作业要求在哪里 https://edu.cnblogs.com/campus/zswxy/CST2019-3/homework/10097 我在这个课程的 ...
- ESXi 制作模板并优化 Centos
1.修改网络配置 vi /etc/sysconfig/network-scripts/ifcfg-eth0 #编辑network配置文件修改以下两项 (eth1同理) ONBOOT=yes BOOTP ...
- Windows 下部署 hadoop spark环境
一.先在本地安装jdk 我这里安装的jdk1.8,具体的安装过程这里不作赘述 二.部署安装maven 下载maven安装包,并解压 设置环境变量,MAVEN_HOME=D:\SoftWare\Mave ...
- DAO语句如何定义属性类型
字体设置:代码 14px 文字 幼圆 15px public interface IAddressDAO { //添加地址 public boolean doCreate(Address addres ...
- Intellj Idea 快捷键入门
Intellj IDEA快捷键入门 时间: 2019/11/29 系统: Win10系统 版本 :Intellj Idea 2018.3 背景: 入手Intellj idea 两个月了,总结一下一些常 ...
- python+pycharm+PyQt5 图形化界面安装教程
python图形化界面安装教程 配置环境变量 主目录 pip所在目录,及script目录 更新pip(可选) python -m pip install --upgrade pip ps:更新出错一般 ...
- 第十三章 字符串 (四)之Scanner类
一.Scanner简述 Scanner扫描器类本质上是由正则表达式实现的,可以接受任何能产生数据的数据源对象,默认以空白符进行分词(包括\n等),使用各种next方法进行扫描匹配,获取匹配的数据. 二 ...
- import xxx和from xxx import xx中修改被导入模块里面的变量的坑
现在有如下几个模块: A.py 功能:定义全局变量,供其他模块使用 name = "张三" lists = [1, 2, 3, 4, 5] B.py 功能:打印A.py中的变量 f ...
- 【hash+二分】Antisymmetry
[题目链接] https://loj.ac/problem/2452 [参考博客] https://blog.csdn.net/xgc_woker/article/details/82904631 [ ...
- RHEL8配置本地yum源
在RHEL8中把软件源分成了两部分一个是BaseOS,一个是AppStream. 在Red Hat Enterprise Linux 8.0中,统一的ISO自动加载BaseOS和AppStream安装 ...