Selenium 2自动化测试实战25(自动化测试模型)
一、自动化测试模型
自动化测试模型介绍:线性测试、模块化驱动测试、数据驱动测试和关键字驱动测试
线性测试:每个测试脚本相对独立,且不产生其他依赖与调用,只是单纯的来模拟用户完整的操作场景。
模块化驱动测试:把重复的操作独立成公共模块,当用例执行过程中需要用到这一模块操作时则被调用。
数据驱动测试:就是数据的参数化,因为输入数据的不同从而引起输出结果的不同。
不管我们读取的是定义的数组、字典,或者是外部文件(excel、csv、txt、xml等)都可以看做是数据驱动,它的目的就是实现数据与脚本的分离。
1. 参数化登录
#public.py
from selenium.webdriver.common.keys import Keys
from time import sleep class loginTest(): def login(self,driver,username,password):
driver.find_element_by_id("username").send_keys(username)
driver.find_element_by_name("j_password").send_keys(password)
sleep(2) driver.find_element_by_name("j_password").send_keys(Keys.ENTER) def quit(self,driver):
driver.quit()
#testlogin.py
#coding:utf-8
from selenium import webdriver
from time import sleep
from public import loginTest class testLogin(): driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get("http://xxxxxx/adminAuth/login") #admin登录
def login(self):
username='admin'
password='xxxxxxx'
loginTest().login(self.driver,username,password)
sleep(5)
loginTest().quit(self.driver) testLogin().login()
2. 读取TXT文件
python提供了以下几种读取txt文件的方式
read():读取整个文件
readline():读取一行数据
readlines():读取所有行的数据
txt文件内容如下图所示,用来存放用户名和密码数据,并通过该文件中的数据作为用例的测试数据。
#TXT文件内容
zhangsan,123
lisi,456
wangwu,789
首先,将用户名和密码按行写入txt文件中,这里把用户名和密码用逗号“,”隔开。
#user_info.py
#coding:utf-8
from selenium import webdriver
from time import sleep user_file=open('user_info.txt','r')
lines=user_file.readlines()
user_file.close() for line in lines:
username=line.split(',')[0]
password=line.split(',')[1]
print(username,password)
运行结果如下图所示:
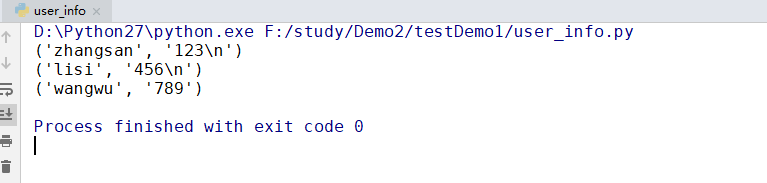
首先通过open()方法以读(“r”)的形式打开user_info.txt文件,使用readlines()方法按行读取txt文件,将获取到的每一行数据通过split()方法拆分出用户名和密码。split()可以将一个字符串通过某一个字符为分割点拆分成左右两部分,这里以逗号(,)为分割点。split()拆分出来的左右两部分以数组的形式存放。所以【0】可以去到左半部分的字符串,【1】可以取到右半部分的字符串。
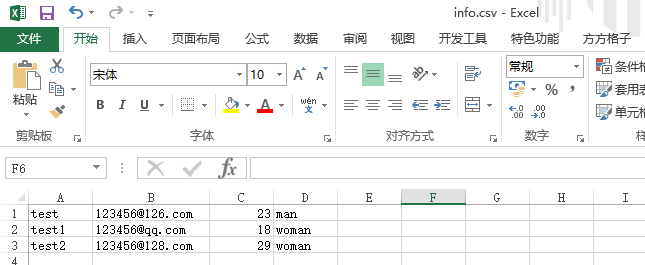
3.读取CSV文件
创建info.csv文件,如下图所示
下面为csv_read.py文件
#csv_read.py
#coding:utf-8
import csv #导入csv包 #读取本地csv文件
date=csv.reader(open('info.csv','r')) #循环输出每一行
for user in date:
print user
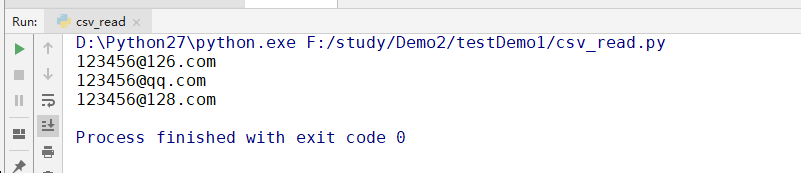
输出结果如下图所示:

首先导入csv模块,通过reader()方法读取csv文件,然后通过for循环遍历文件中的每一行数据。从打印结果看,读取的每一行数据均是以数组的形式存储的,取某一列,则只需指定数组下标即可。
#csv_read.py
#coding:utf-8
import csv #导入csv包 #读取本地csv文件
date=csv.reader(open('info.csv','r')) #循环输出每一行
for user in date:
print user[1]
假如现在需要所有用户的邮箱地址,那么只需指定邮箱地址所在列的下标即可。数组下标是以0开始的,邮箱位于数组的第二列,所以指用户邮箱的下标为[1]。
4. 读取xml文件
有时,需要一个配置文件来配置当前自动化测试脚本的URL,浏览器、登录的用户名和密码等,这时候就可以选择使用XML文件来存放这些信息。
#Info.xml
<?xml version="1.0" encoding="utf-8"?>
<info>
<base>
<platform>Windows</platform>
<browser>Chrome</browser>
<url>http://www.baidu.com</url>
<login username="admin" password="123456"/>
<login username="guest" password="654321"/>
</base>
<test>
<province>北京</province>
<province>广东</province>
<city>深圳</city>
</test>
</info>
#read_xml.py
#coding:utf-8
from xml.dom import minidom #打开xml文档
dom=minidom.parse('info.xml') #得到文档元素对象
root=dom.documentElement print(root.nodeName)
print (root.nodeValue)
print (root.nodeType)
print (root.ELEMENT_NODE)

首先导入xml的minidom模块,用来处理XML文件,parse()用于打开一个XML文件,documentElement用于得到XML文件的唯一根元素。
每一个节点都有它的nodeName、nodeValue、nodeType等属性。nodeName为节点名称;nodeValue为节点的值,只对文本节点有效;nodeType为节点的类型。
5.获得任意标签名
#coding:utf-8
#获得任意标签名
from xml.dom import minidom #打开xml文档
dom=minidom.parse('info.xml') #获得文档元素对象
root=dom.documentElement tagname=root.getElementsByTagName('browser')
print (tagname[0].tagName) tagname=root.getElementsByTagName('login')
print (tagname[0].tagName) tagname=root.getElementsByTagName('province')
print (tagname[0].tagName)
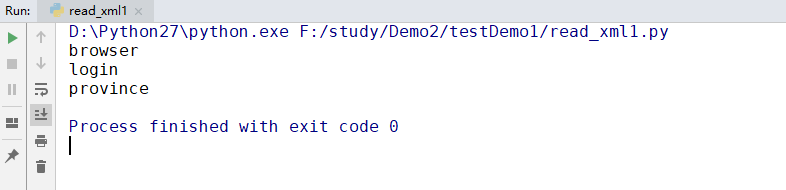
getElementsByTagName()可以通过标签名获取标签,它所获取的对象是以数组形式存放。可以通过指定数组的下标的方式获取某个具体标签。
1.getElementsByTagName('province')获得的是标签名为“peovince”的一组标签;
2.getElementsByTagName('province').tagname[0]表示一组标签中的第一个;
3.getElementsByTagName('province').tagname[2]表示一组标签中的第三个;
6.获得标签的属性值
#coding:utf-8
#获得任意标签名
from xml.dom import minidom #打开xml文档
dom=minidom.parse('info.xml') #获得文档元素对象
root=dom.documentElement logins=root.getElementsByTagName('login') #获得login标签的username属性值
username=logins[0].getAttribute("username")
print username
username=logins[1].getAttribute("username")
print username

getAttribute()方法用于获取元素的属性值,他和WebDriver中所提供的get_attribute()方法相似。
7.获得标签对之间的数据
#coding:utf-8
#获得任意标签名
from xml.dom import minidom #打开xml文档
dom=minidom.parse('info.xml') #获得文档元素对象
root=dom.documentElement province=root.getElementsByTagName('province')
city=root.getElementsByTagName('city') #获得第一个province标签对的值
p1=province[1].firstChild.data
print p1 c1=city[0].firstChild.data
print c1
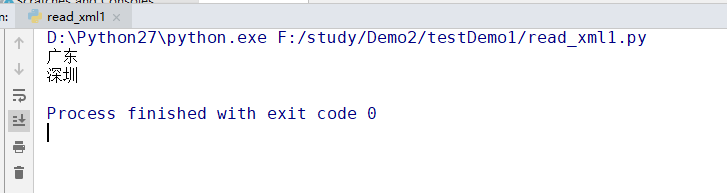
firstChild属性返回被选节点的第一个子节点。data表示获取该节点的数据,它和webdriver中提供的text方法类似。
Selenium 2自动化测试实战25(自动化测试模型)的更多相关文章
- Selenium 与自动化测试 —— 《Selenium 2 自动化测试实战》读书笔记
背景 最近在弄 appium,然后顺便发现了 Selenium 框架和这本书,恰好这本书也介绍了一些软件测试&自动化测试的理论知识,遂拿过来学习学习.所以本文几乎没有实践内容,大多都是概念和工 ...
- Selenium 2自动化测试实战
Selenium 2自动化测试实战 百度网盘 链接:https://pan.baidu.com/s/1aiP3d8Y1QlcHD3fAlEj4sg 提取码:jp8e 复制这段内容后打开百度网盘手机Ap ...
- 《selenium2 python 自动化测试实战》(20)——Selenium工具介绍
(一)Selenium IDE Firefox的一个插件,有助于我们理解测试框架.在附加组件里搜索下载,一般搜的结果里前几个都不是,得点那个查看更多才行,找到这个: 安装以后浏览器工具栏会有: 安装好 ...
- 《selenium2 python 自动化测试实战》(11)——selenium安装版本
先和大家说一下selenium环境的问题,大家可以在cmd里先看一下自己的selenium版本: 回车,就可以安装了. 本来想和大家说如何跳过验证码进行登录的,结果好多朋友加我问我环境配置的问题,所以 ...
- Selenium 2自动化测试实战3(函数、类和方法)
一.函数.类和方法1.函数在python中通过def关键字来定义函数 创建一个add()函数,此函数接收两个参数a,b,通过print()打印a+b的结果.调用add()函数,并且上传两个参数3,5给 ...
- 《Selenium 2自动化测试实战 基于Python语言》中发送最新邮件无内容问题的解决方法
虫师的<Selenium 2自动化测试实战 基于Python语言>是我自动化测试的启蒙书 也是我推荐的自动化测试入门必备书,但是书中有一处明显的错误,会误导很多读者,这处错误就是第8章自动 ...
- 《selenium2 python 自动化测试实战》(18)——自动化测试模型(一)
线性测试 已经被淘汰了:线性测试就是一个脚本完成一个场景,代码基本没有复用,每一个脚本都要从头开始写——这哪行. 模块化与类库 这个就是分模块:有点类似面系那个对象,把功能(比如登录)单独拿出来,当下 ...
- selenium2 Webdriver + Java 自动化测试实战和完全教程
selenium2 Webdriver + Java 自动化测试实战和完全教程一.快速开始 博客分类: Selenium-webdriverselenium webdriver 学习selenium ...
- Selenium2+Python自动化测试实战
本人在网上查找了很多做自动化的教程和实例,偶然的一个机会接触到了selenium,觉得非常好用.后来就在网上查阅各种selenium的教程,但是网上的东西真的是太多了,以至于很多东西参考完后无法系统的 ...
随机推荐
- IPC之msg.c源码解读
// SPDX-License-Identifier: GPL-2.0 /* * linux/ipc/msg.c * Copyright (C) 1992 Krishna Balasubramania ...
- $q defer
实际应该是这样更好理解 把,asyncGreet换成实际的http请求SyncRequest. 如果我们多个请求那么 就是多个 promise我们要么就是链式then,要么就是$q.all 可以根据需 ...
- Python 等分切分数据及规则命名
将一份一亿多条数据的csv文件等分为10份,代码如下所示: import pandas as pd data = pd.read_csv('C:\\Users\\PycharmProjects\\Sp ...
- golang高并发
golang 为什么能做到高并发 goroutine是go并行的关键,goroutine说到底就是携程,但是他比线程更小,几十个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这 ...
- 06-char,varchar和nvarchar三者的区别
总结: 1.首先先知道一下SQLServer中数据存储的基本单位是页.每页的大小是8KB: 2.char(n),里面的n用于定义字符串长度,以字节为单位: 3.三者的区别 * char: 是定长的,比 ...
- php类点滴---访问修饰符public protected private
public可以被继承,可以外部访问(也就是实例化对象可以直接访问) protected受保护的,可以被子类继承,无法外部访问 private继承,外部访问都别想 <?phpclass coac ...
- Hadoop-No.16之Kafka
Apache Kafka 是一種发布-订阅消息的分布式系统.能够将消息归类为不同主题.应用程序能在Kafka上发布信息,或订阅主题进而接受特定主题下发布的消息.Producer发布消息,而Consum ...
- 题解 比赛 match
比赛 match Description 有 N 支队伍打比赛.已知有如下条件: • 每支队伍恰好打了 4 场比赛 • 对于一场比赛,如果是平局,双方各得 1 分:否则胜者得 3 分,负者不得分 给定 ...
- java 项目 文件关系 扫描 注释注入(3)
@RequestParam和@PathVariable用法小结 https://www.cnblogs.com/helloworld-hyyx/p/5295514.html(copy) @Reque ...
- 51 Nod 1101 换零钱(动态规划好题)
1101 换零钱 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 关注 N元钱换为零钱,有多少不同的换法?币值包括1 2 5分,1 2 5角,1 2 5 ...