pandas的用法
1.a = pandas.read_csv(filepath):读取.csv格式的文件到列表a中,文件在路径filepath中
pandas.core.frame.DataFrame是pandas的核心结构
b = a.head(n):b中存有文件前n行,默认为5行
b = a.tail(n):b中存有文件后n行,默认为5行
import pandas as pd
food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv")
print(type(food_info))
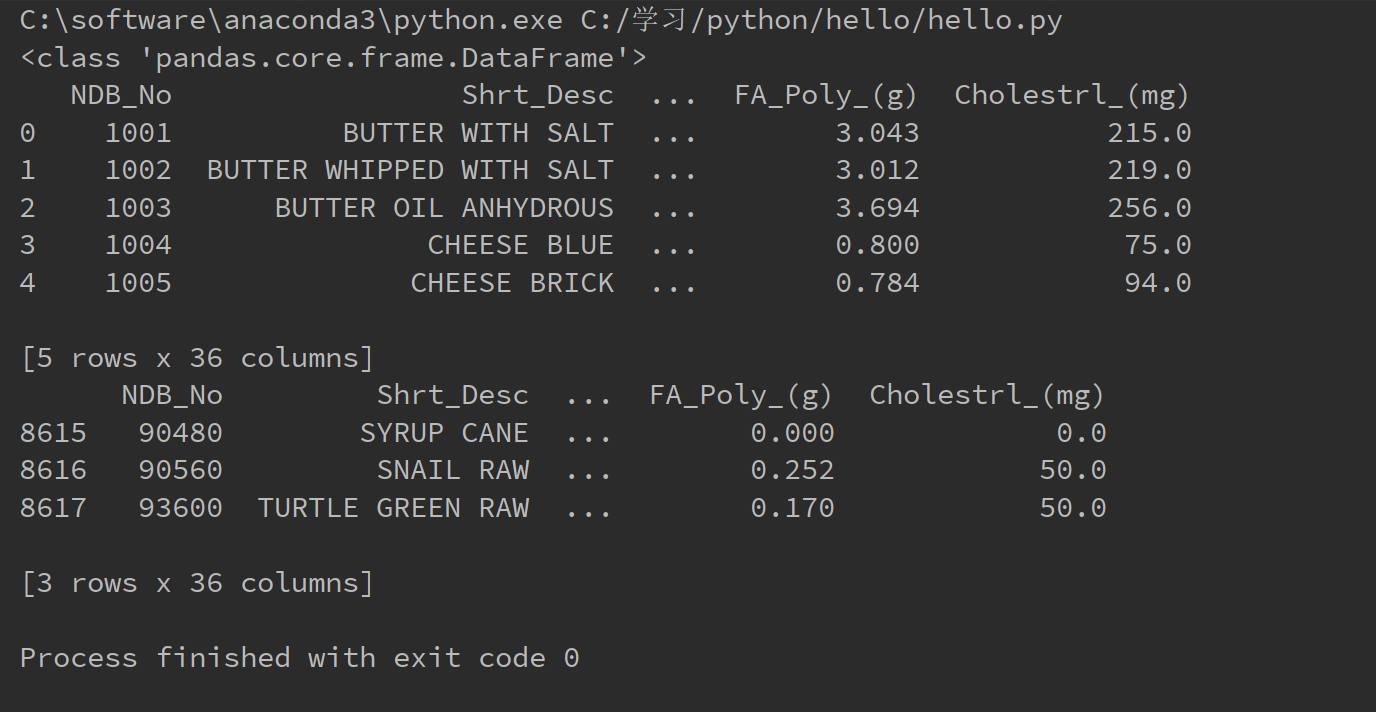
a = food_info.head()
b = food_info.tail(3)
print(a)
print(b)
2.pandas索引与计算。
设a为DataFram类型。
- a.loc[n]表示提取a的第 n行;a.loc[n:m]表示提取a的n到m行,当然,还可以用列表作为索引。
- a['name']表示提取列名为"name"的列。
- 加减乘除和numpy的向量一样。
- a.columns.tolist()将所有的列名存储在一个向量中
- a['name'].max()可以取出该列的最大值。
import pandas as pd
food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv")
print(food_info.loc[3:5])
print(food_info["NDB_No"].head(3))
print(food_info["Water_(g)"].max())
运行结果如下
下面的代码是将所有的单位是g的列找出来,并转化为mg,然后求和并加入a中。
import pandas as pd
food_info = pd.read_csv("C:/Users/娄斌/Desktop/.ipynb_checkpoints/food_info.csv")
columns = food_info.columns.tolist()
gram_c = []
for c in columns:
if c.endswith("(g)"):
gram_c.append(c)
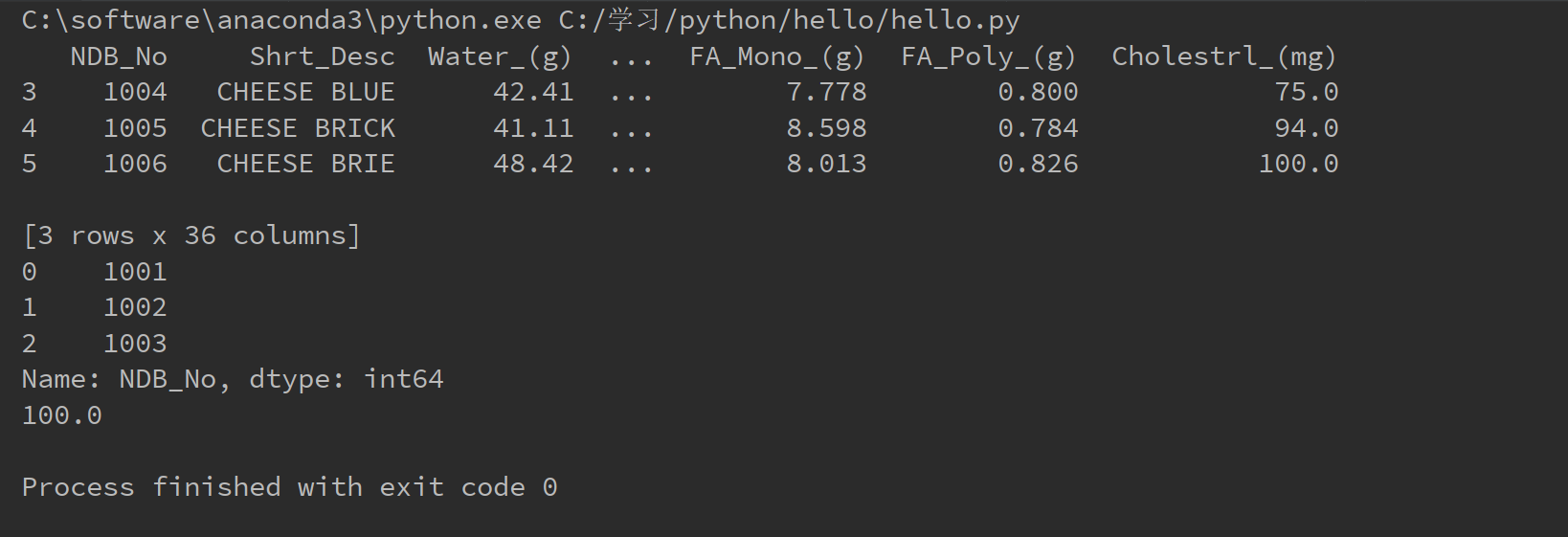
print(food_info[gram_c].head(3))
food_info[gram_c] = food_info[gram_c]/1000
print(food_info[gram_c].head(3))
food_info["sum(mg)"] = 0
for c in gram_c:
food_info["sum(mg)"] += food_info[c]
print(food_info.head(3))

3.pandas排序和titanic数据集
sor_value()函数进行排序,当参数inplace = false时,原数据集不变,当inplace = true时,原数据集变成排序后的结果。
下面的代码是读取titanic_train.csv的数据并按照标签“fare"进行排序,然后读取所有年龄为空的记录,并统计该记录集的长度。
import pandas as pd
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv")
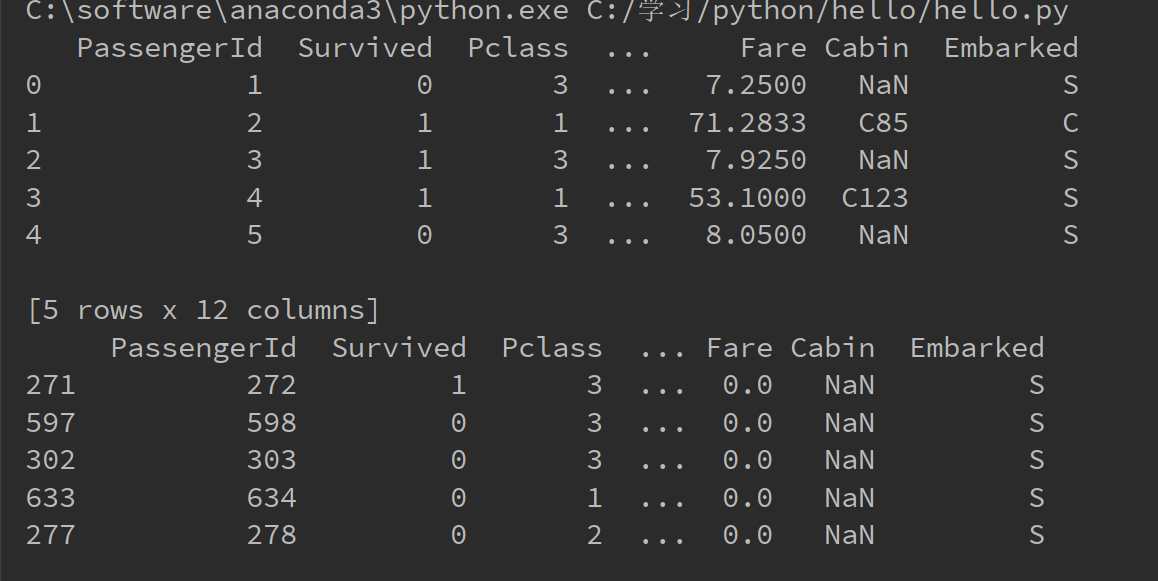
print(titanic.head(5))
titanic.sort_values("Fare", inplace=True)
print(titanic.head(5))
#将所有年龄为空的记录显示出来并统计个数
age = titanic['Age']
age_is_null_judge = pd.isnull(age)
age_is_null = age[age_is_null_judge]
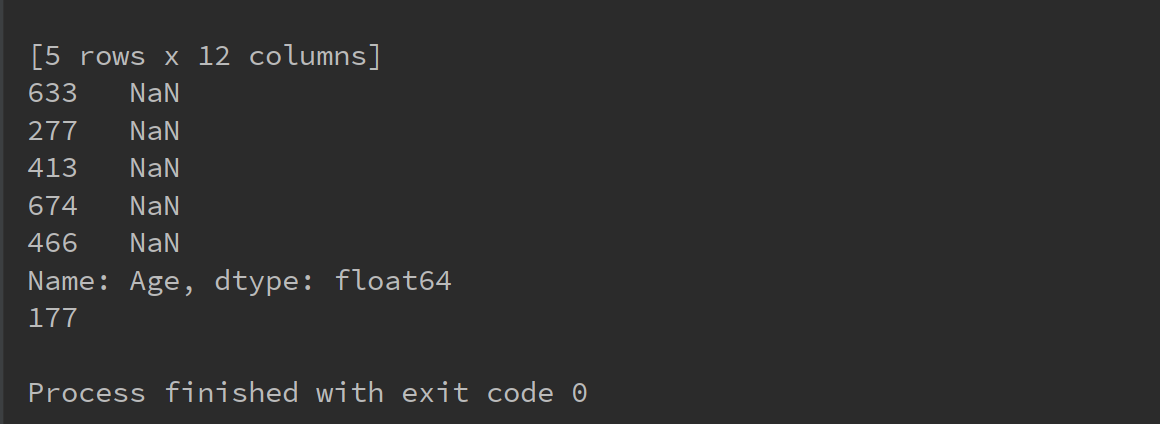
print(age_is_null)
print(len(age_is_null))
4.数据预处理方法
计算某一个属性的平均值,下面代码是计算数据集中age属性平均值
import pandas as pd
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv")
age = titanic['Age']
age_is_null_judge = pd.isnull(age) #isnull函数判断函数的age是否为NaN,如果是则为true,否则为false
new_age = titanic['Age'][age_is_null_judge == False] #注意俩个中括号,一个是属性,一个是判断
mean = sum(new_age) / len(new_age) #sun函数和len函数
print(mean)
还可以用dropna函数去掉属性为空的记录
import pandas as pd
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv")
age = titanic['Age']
new_titanic = titanic.dropna(axis=0, subset=['Age']) #subset是一个列表,可以有多个属性
new_age = new_titanic['Age']
print(sum(new_age)/len(new_age))
以上两段代码的运行结果都是
29.69911764705882
下面这几行代码可以访问DataFram中的某行某列的元素
titanic = pd.reavd_csv("C:/学习/python/hello/titanic_train.csv")
print(titanic.loc[24, 'Age'])
可以用pivot_table(index='Pclass', values='Age', aggfunc=np.mean)对数据进行分类统计,例如这里的参数index说明该函数先将所有的记录按照Pclass的不同进行分类,
参数value = ‘Age'说明对于每一类的记录,统计其属性Age, aggfunc = np.mean参数说明对Age属性求平均值。
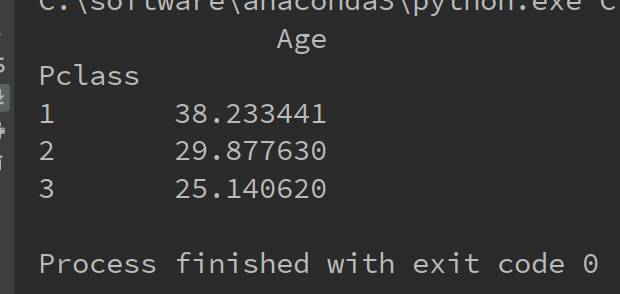
下面的代码就是分别统计1,2,3等舱的乘客的平均年龄
import pandas as pd
import numpy as np
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv")
mean_age = titanic.pivot_table(index='Pclass', values='Age', aggfunc=np.mean)
print(mean_age)
运行结果如下
利用panddas的sort_value函数可以实现排序,但是排序好的记录的索引值还是原来的索引,即样本不再是从第0行到第n行了,如下图所示

现在要把索引变成从0到1,只需要利用reset_index()函数
import pandas as pd
import numpy as np
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv")
new_titanic = titanic.sort_values('Age')
new_titanic1 = new_titanic.reset_index()
print(new_titanic.head())
print(new_titanic1.head())
运行结果如下

可以用apply(func, axis)函数实现自定义函数,其中第一个参数func是自定义的函数,第二个参数axis=0表示func函数逐列处理数据,axis=1表示逐行处理函数
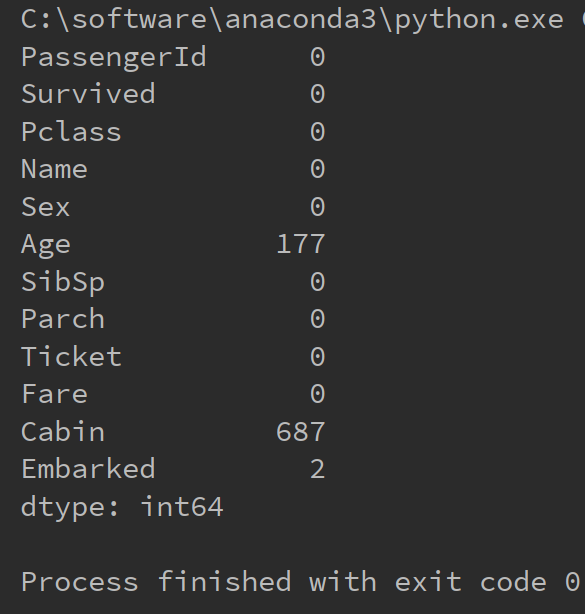
如下代码统计每一列的空值个数
import pandas as pd
import numpy as np #统计每个属性的空值个数
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") def nul_count(column):
is_null_judge = pd.isnull(column)
is_null = column[is_null_judge]
return len(is_null) column_null_count = titanic.apply(nul_count, axis=)
print(column_null_count)
运行结果如下
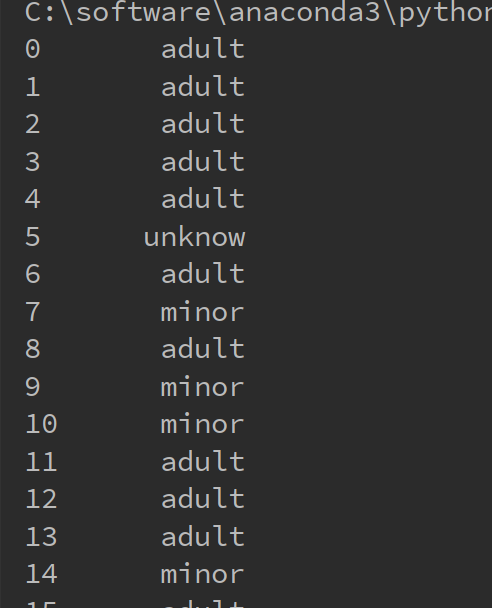
以下的代码将年龄离散化成成年人和未成年人
import pandas as pd
import numpy as np #统计每个属性的空值个数
titanic = pd.read_csv("C:/学习/python/hello/titanic_train.csv") def generate_age_label(row):
age = row['Age']
if pd.isnull(age):
return "unknow"
elif age < :
return "minor"
else:
return "adult" age_labels = titanic.apply(generate_age_label, axis=)
print(age_labels)
运行结果如下
5.series结构
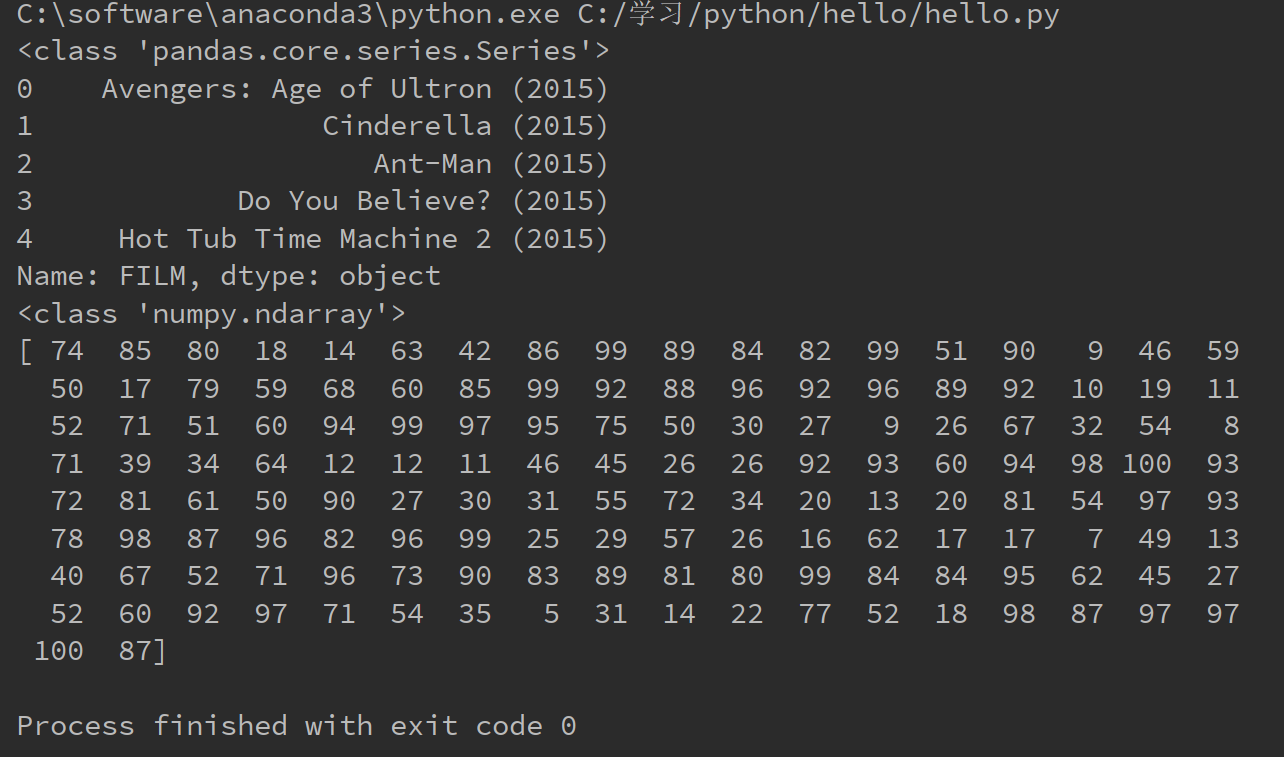
设a是DataFram结构,b为a的某一行或者某一列,那么b为Series结构。 c = b.values,那么c为numpy的ndarray结构。如下代码所示
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
series_film = fandango["FILM"]
series_rt = fandango["RottenTomatoes"]
print(type(series_film))
print(series_film.head())
film_name = series_film.values
rt_scores = series_rt.values
print(type(rt_scores))
print(rt_scores)
下面是运行结果
通过pandas.Series(value, index)函数可以将两个ndarray类型的值组合成一个Series类型,这里index是索引,value是值,如下代码 所示,将电影名和其RontenTomatoes的评分对应起来
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
series_film = fandango["FILM"]
series_rt = fandango["RottenTomatoes"] film_name = series_film.values
rt_scores = series_rt.values series_custom = pd.Series(rt_scores, index=film_name)
print(type(series_custom))
print(series_custom)
运行结果如下

可以用Series结构按索引排序构造新的Series。如下代码所示
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
series_film = fandango["FILM"]
series_rt = fandango["RottenTomatoes"] film_name = series_film.values
rt_scores = series_rt.values series_custom = pd.Series(rt_scores, index=film_name) #对电影名进行排序
origial_index = series_custom.index.tolist() #origial_index是list类型
sorted_index = sorted(origial_index)
new_series_custom = series_custom.reindex(sorted_index)
print(new_series_custom)
运行结果如下

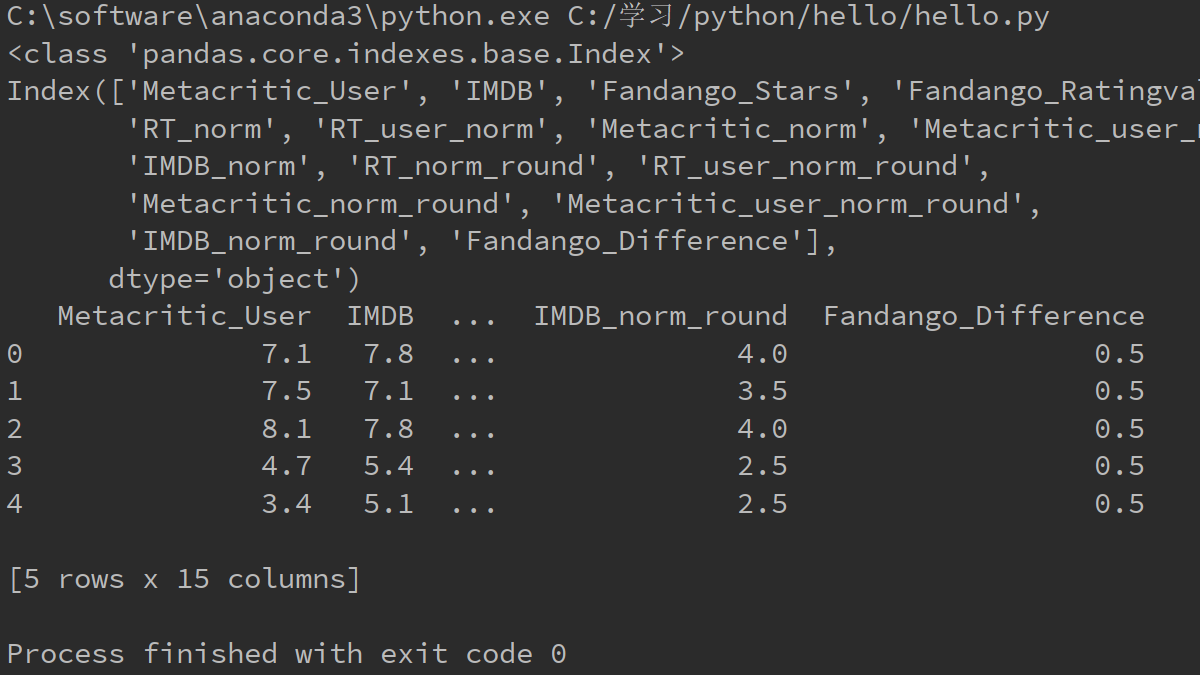
以下代码实现将数据表fandango中类型为float64的列保留下来构成新表
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
types = fandango.dtypes #Series结构,索引是列名,值是该列的数据类型 float_column = types[types.values == 'float64'].index #将类型为float64的列名找出来
print(type(float_column))
print(float_column)
float_df = fandango[float_column]
print(float_df.head())
运行结果如下
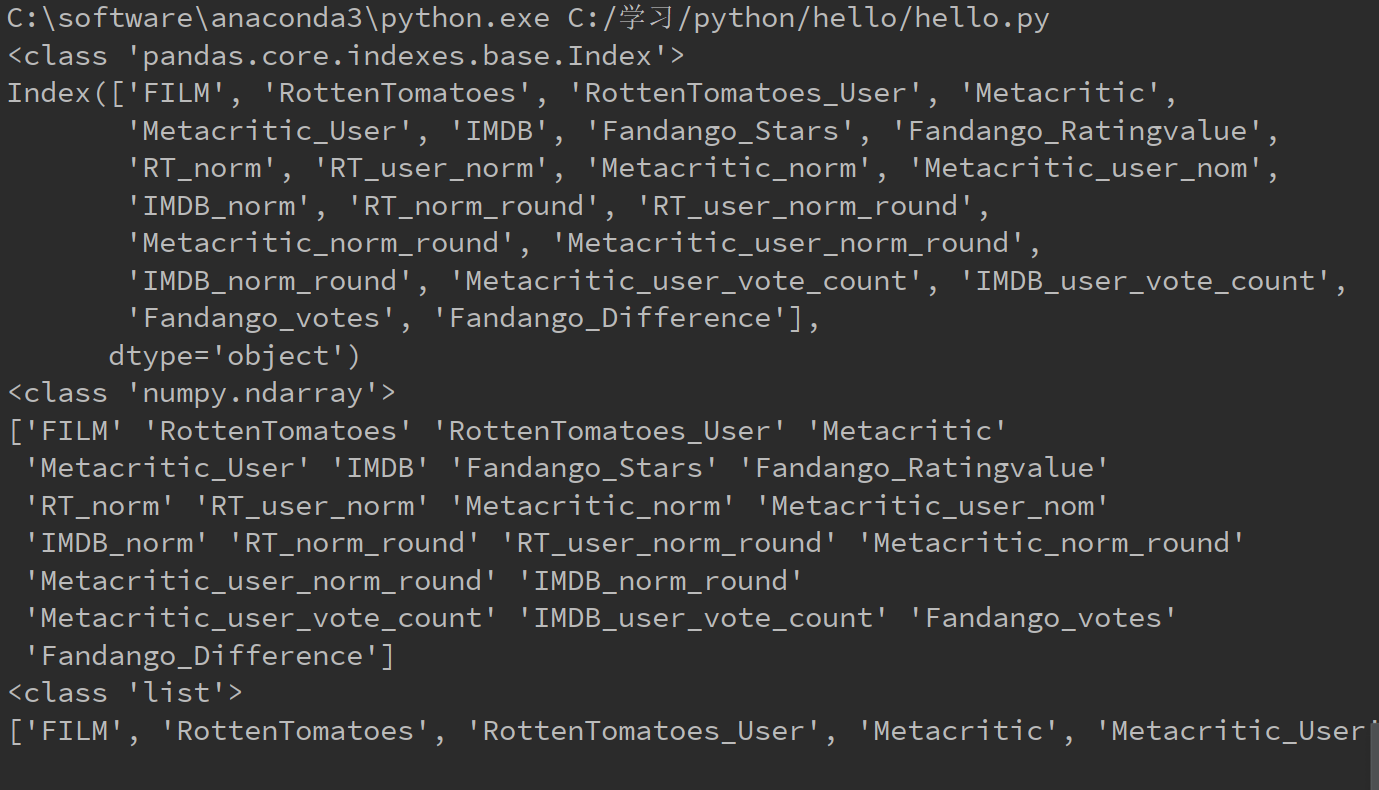
设fandango是Datafram结构,则fandango.columns的数据类型是index,fandango.columns.values的数据类型是ndarray,fandango.columns.values.tolist()的数据类型是list。这个数据类型
关系很重要。还有Datafram的某一行或者某一列为Series结构,Series的values属性是ndarray类型,ndarray结构调用tolist()成为list类型
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
columns = fandango.columns
columns_values = columns.values
columns_value_list = columns_values.tolist()
print(type(columns))
print(columns)
print(type(columns_values))
print(columns_values)
print(type(columns_value_list))
print(columns_value_list)
运行结果如下
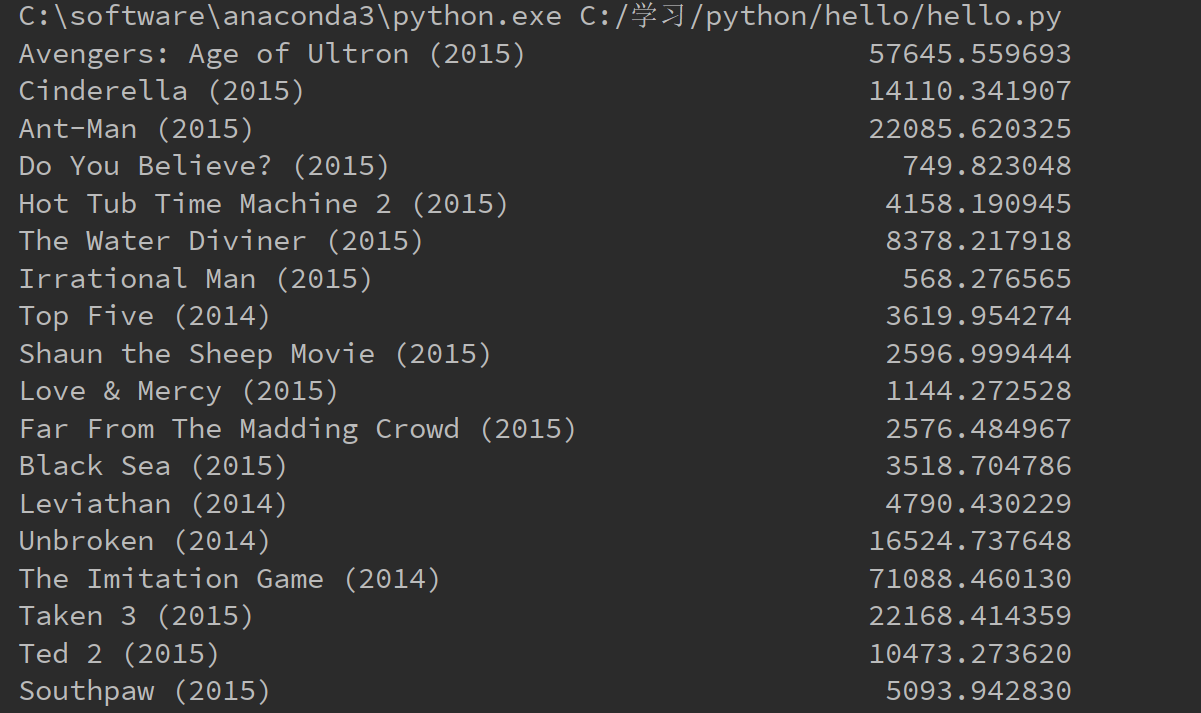
以下代码实现对每个电影的所有评价求方差,并打印出来
import pandas as pd
import numpy as np fandango = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
columns = fandango.columns #所有的属性名,index类型
columns_values = columns.values #所有的属性名,ndarray类型
new_fandango = fandango[columns_values[columns_values != 'FILM']] #去掉电影名这一列才能对剩下的列求方差
result = new_fandango.apply(lambda x: np.std(x), axis=) #自定义函数求方差,axis=1表示按行处理,这里的x是Series类型
film_name = fandango['FILM'] #Series类型的电影名
result_std = pd.Series(data=result.values, index=film_name.values)
print(result_std)
运行结果如下,记住numpy的std函数是可以传入Series类型的参数的,不过要求值全部为数值类型。
6.values属性将表格矩阵化
设a是datafram类型的数据集,则b = a.values执行后,b是一个矩阵,ndrray类型。
pandas的用法的更多相关文章
- pandas基础用法——索引
# -*- coding: utf-8 -*- # Time : 2016/11/28 15:14 # Author : XiaoDeng # version : python3.5 # Softwa ...
- pandas基础用法
首先生成一维数组 data = pd.Series([1,2,3,4,5,6,7,8,9])data运行结果 data.head()#默认取前五条,当然也可以加参数 data.tail()#默认取前五 ...
- pandas.read_csv用法(转)
的数据结构DataFrame,几乎可以对数据进行任何你想要的操作. 由于现实世界中数据源的格式非常多,pandas也支持了不同数据格式的导入方法,本文介绍pandas如何从csv文件中导入数据. 从上 ...
- pandas 基础用法
pandas 是一个基于 Numpy 构建, 强大的数据分析工具包 主要功能 独特的数据结构 DataFrame, Series 集成时间序列功能 提供丰富的数学运算操作 灵活处理缺失数据 Serie ...
- Pandas基础用法-数据处理【全】-转
完整资料:[数据挖掘入门介绍] (https://github.com/YouChouNoBB/data-mining-introduction) # coding=utf-8 # @author: ...
- 【转】Pandas常见用法总结
关键缩写和包导入 在这个速查手册中,我们使用如下缩写: df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象 raw:行标签 col:列标签 引入响应模块: im ...
- 数据分析——Pandas的用法(Series,DataFrame)
我们先要了解,pandas是基于Numpy构建的,pandas中很多的用法和numpy一致.pandas中又有series和DataFrame,Series是DataFrame的基础. pandas的 ...
- python模块之numpy,pandas基本用法
numpy: 是 Python 的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库简单来说:就是支持一维数组和多维数组的创建和操作,并有丰富的函数库. 直接看例子 ...
- Pandas核心用法
目录 Numpy和Pandas Numpy科学计算 Pandas数据分析 安装jupyter notebook Numpy语法 创建和基本使用 切片索引 布尔索引 对位运算 矩阵的乘除 其他方法 Pa ...
随机推荐
- Unrecognized SSL message, plaintext connection? 将https 换为http 即可
请求链接:https://59********* 升级后的项目地址有https换为了http ,出现这个错误,改为http请求即可
- webuploader+上传文件夹
在web项目中上传文件夹现在已经成为了一个主流的需求.在OA,或者企业ERP系统中都有类似的需求.上传文件夹并且保留层级结构能够对用户行成很好的引导,用户使用起来也更方便.能够提供更高级的应用支撑. ...
- Chef and Problems(from Code-Chef FNCS) ( 回 滚 )
题目: 题意:给定序列,求[l,r]区间内数字相同的数的最远距离. 链接:https://www.codechef.com/problems/QCHEF #include<bits/stdc++ ...
- 第二章 Python数据导入
数据导入 数据存储的两个地方: 文件 CSV.Excel.TXT(学习层面) 数据库(公司实战层面) Mysql.Access.SQL Server 导入CSV文件 CSV文件第一行是列名,第二行到最 ...
- MIME协议(一) -- RFC822邮件格式
MIME协议(一) -- RFC822邮件格式 . 如同其他各种电子文档一样,电子邮件内容也必须遵循一定的格式要求,各种邮件处理程序才能从中分析和提取出发件人.收件人.主题和附件等信息.邮件内容的 ...
- HTML语义化是什么?为什么要语义化?
HTML语义化HTML的语义化总结为: 用最恰当的标签来标记内容. 该如何理解呢?比如需要加入一个标题,这个标题的字体比正文的要大写,还要加粗.能够实现这种效果的方法有很多,比如用CSS样式进行渲染. ...
- HearthBuddy 日志模块
// Triton.Common.LogUtilities.CustomLogger // Token: 0x04000BD8 RID: 3032 private Level level_0 = Le ...
- HearthBuddy中_settings.txt的更详细参数解释
https://tieba.baidu.com/p/5275382967 默认的配置不是很合理,花了点时间读了下silverfish(也就是兄弟用的AI)的代码后也尝试修改了些参数,有没有效果仁者见仁 ...
- mysql 创建++删除 数据库
创建RUNOOB数据库,并设定编码集为utf8 CREATE DATABASE IF NOT EXISTS RUNOOB DEFAULT CHARSET utf8 COLLATE utf8_gener ...
- k8s部署03-----常用运维命令
kubectl常用命令 kubectl get nodes #查看集群中有多少个node kubectl describe node <node_name> #查看某个node的详细信息 ...