spark-on-yarn 学习
1. hdfs存文件的时候会把文件切割成block,block分布在不同节点上,目前设置replicate=3,每个block会出现在3个节点上。
2. Spark以RDD概念为中心运行,RDD代表抽象数据集。以代码为例:
sc.textFile(“abc.log”)
textFile()函数会创建一个RDD对象,可以认为这个RDD对象代表”abc.log”文件数据,通过操作RDD对象完成对文件数据的操作。
3. RDD包含1个或多个partition分区,每个分区对应文件数据的一部分。在spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition。所以,RDD对应文件,而partition对应文件的block,partition的个数等于block的个数,这么做的目的是为了并行操作文件数据。
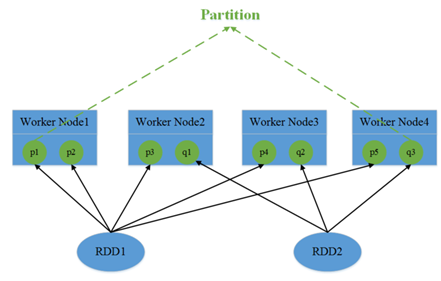
由于block是分布在不同节点上的,所以对partition的操作也是分散在不同节点。
4. RDD是只读的,不可变数据集,所以每次对RDD操作都会产生一个新的RDD对象。同样,partition也是只读的。
sc.textFile("abc.log").map()
代码中textFile()会构建出一个NewHadoopRDD,map()函数运行后会构建出一个MapPartitionsRDD。
这里的map()函数已经是一个分布式操作,因为NewHadoopRDD内的partition是分布在不同节点上的,map()函数会对每一个partition做一次map操作,形成新的partition,一会产生新的RDD(MapPartitionsRDD)。对每个partition执行map操作就是一个task,在图中就会有3个task,task和partition一一对应。

5. 最终每个task会和partition一一对应。但是在分配之前需要考虑task的执行顺序。就出现了job、stage、宽依赖和窄依赖的概念。
宽依赖和窄依赖是为了安排task的执行顺序。简单理解,窄依赖是指操作可以pipeline形式进行,比如map、filter,,不需要依赖所有partition的数据,可以并行地在不同节点计算。map和filter只需要一个分区的数据。
宽依赖,比如groupByKey,需要所有分区的数据才能进行计算,同时会引发节点间的数据传输。
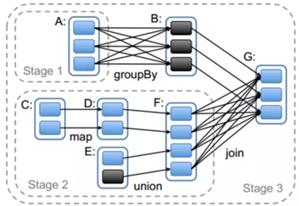
Spark会依据窄依赖和宽依赖划分stage,stage按顺序1,2,3依次执行。
图中stage2里的map和union是窄依赖。
stage3的join是宽依赖。Join操作会把所有partition的数据汇总起来,生产新的partition,这中间可能会发生大量的数据传输。同时会把新生产的RDD写回hdfs,在下次使用时重新读取,划分新的partition。
若干个stage组成一个job,job由真正执行数据的计算部分触发产生,如reduce、collect等操作,所以一个程序可能有多个job。RDD中所有的操作都是Lazy模式进行,运行在编译中不会立即计算最终结果,而是记住所有操作步骤和方法,只有显示的遇到启动命令才执行。
整体看:一个程序有多个job,一个job有多个stage,一个stage有多个task,每个task分配到executor内执行。
6. 分配task时,优先找已经在内存中的数据所在节点;如果没有,再找磁盘上的数据所在节点;都没有,就近节点分配。
7. executor
每个节点根据配置可以起一个或多个executor;每个executor由若干core组成,每个executor的每个core一次只能执行一个task。
task被执行的并行度 = max(executor数目*每个executor的核数,partition数目)。
8. 节点之间使用RPC完成通信(以前是akka,最新的使用netty)。
最后,目前看来,可能会对性能有影响的是有宽依赖的操作,像reduceByKey、sort、sum操作需要所有partition的数据,需要把数据都传输到一个节点上,比较耗时。
spark-on-yarn 学习的更多相关文章
- Spark on Yarn 学习(一)
最近看到明风的关于数据挖掘平台下实用Spark和Yarn来做推荐的PPT,感觉很赞,现在基于大数据和快速计算方面技术的发展很快,随着Apache基金会上发布的一个个项目,感觉真的新技术将会不断出现在大 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- YARN学习总结
YARN学习总结 前言 YARN(Yet Another Resource Manage,另一种资源协调者)是hadoop-0.23版本引入的的一个新的特性,可以说它是对原有Hadoop Mapred ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- Spark Standalone与Spark on YARN的几种提交方式
不多说,直接上干货! Spark Standalone的几种提交方式 别忘了先启动spark集群!!! spark-shell用于调试,spark-submit用于生产. 1.spark-shell ...
- Hadoop YARN学习之核心概念(2)
Hadoop YARN学习之核心概念(2) 1. Hadoop 2.X YARN引入的新服务 1.1 新的ResourceManager纯碎作为资源调度器,是集群资源的唯一仲裁者: 1.2 用户应用程 ...
- spark on yarn模式下内存资源管理(笔记1)
问题:1. spark中yarn集群资源管理器,container资源容器与集群各节点node,spark应用(application),spark作业(job),阶段(stage),任务(task) ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)(转)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark on yarn 安装笔记
yarn版本:hadoop2.7.0 spark版本:spark1.4.0 0.前期环境准备: jdk 1.8.0_45 hadoop2.7.0 Apache Maven 3.3.3 1.编译spar ...
随机推荐
- VMware厚置备延迟置零,厚置备置零,精简置备详解
1.厚置备延迟置零(zeroed thick) 以默认的厚格式创建虚拟磁盘.创建过程中为虚拟磁盘分配所需空间.创建时不会擦除物理设备上保留的任何数据,但是以后从虚拟机首次执行写操作时会按需要将其置零. ...
- centos7 nginx设置开启启动
添加系统服务 在 /usr/lib/systemd/system 目录中添加 nginx.service,根据实际情况进行修改,详细解析可查看下方参考资料中的文章.内容如下 ? [Unit] ...
- dstat命令详解
dstat 如果系统没有些工具 yum -y install dstat安装下即妥,此软件小巧玲珑,软件包大小只有144k,安装大小660k. 此工具默认情况下会动态显示CPU,disk,net,pa ...
- [六省联考2017]分手是祝愿——期望DP
原题戳这里 首先可以确定的是最优策略一定是从大到小开始,遇到亮的就关掉,因此我们可以\(O(nlogn)\)的预处理出初始局面需要的最小操作次数\(tot\). 然后容(hen)易(nan)发现即使加 ...
- BZOJ 3065 带插入区间K小值 (替罪羊树套线段树)
毒瘤题.参考抄自博客:hzwer 第一次写替罪羊树,完全是照着题解写的,发现这玩意儿好强啊,不用旋转每次都重构还能nlognnlognnlogn. 还有外面二分和里面线段树的值域一样,那么r = mi ...
- goproxy
go env -w GOPROXY=https://goproxy.cn,directgo env -w GO111MODULE=ongo env -w GOBIN=$HOME/bin (可选)go ...
- 添加Mybatis
- 洛谷 P4933 大师
题面 (实名推荐:本题的出题人小哥哥打球暴帅哦!(APIO/CTSC/WC的时候一起打过球w,而且大学在我隔壁喔) ) 没仔细看数据范围的时候真是摸不着头脑...还以为要 O(N^2) dp 爆锤.. ...
- node中的http内置模块
Node.js开发的目的就是为了用JavaScript编写Web服务器程序.因为JavaScript实际上已经统治了浏览器端的脚本,其优势就是有世界上数量最多的前端开发人员.如果已经掌握了JavaSc ...
- MySQL原理解析
逻辑架构 MySQL逻辑架构整体分为三层: 客户端层,连接处理.授权认证.安全等功能均在这一层处理. 核心服务层,包括查询解析.分析.优化.缓存.内置函数(比如:时间.数学.加密等函数).所有的跨存储 ...