二、HDFS 架构
源自:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.

namenode:存储系统的元数据(用于描述数据的数据,内存),例如 文件命名空间/block到datanode的映射.负责管理datanode
datanode:用于存储数据块的节点.负责响应客户端对块的读写请求,向namenode汇报自己块信息.
block:数据块,是对文件拆分的最小单位,表示一个切分尺度默认值128MB,每个数据块的默认副本因子是3通过
dfs.replication进行配置,用户可以通过dfs.blocksize设置块大小
rack机架,使用机架对存储节点做物理编排,用于优化存储和计算.查看机架
[root@CentOS ~]# hdfs dfsadmin -printTopology
Rack: /default-rack
192.168.169.139:50010 (CentOS)
为什么说HDFS不擅长存储小文件?
文件 namenode占用(内存) datanode占用磁盘
128MB 单个文件 1个block元数据信息 128MB * 副本因子
128MB 10000个文件 10000个block元数据信息 128MB * 副本因子
因为Namenode是使用单机的内存存储元数据,因此导致namenode内存紧张.
NameNode和Secondary Namenode的关系?
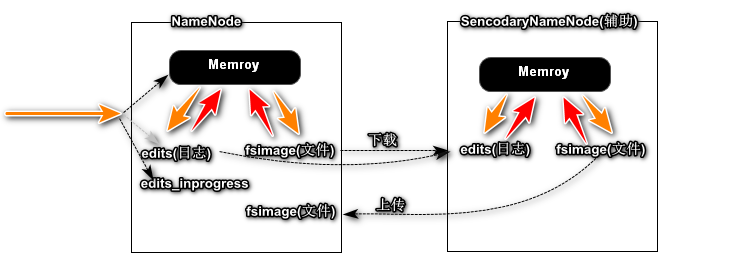
辅助NameNode整理Edits和Fsimage文件,加速NameNode启动过程.
HDFS Shell
[root@CentOS ~]# hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...] #
[-checksum <src> ...] #
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] #
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] #
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] #
[-cp [-f] [-p | -p[topax]] <src> ... <dst>] #
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] #
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]] #
[-mkdir [-p] <path> ...] #新建文件夹
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>] #
[-rm [-f] [-r|-R] [-skipTrash] <src> ...] #
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-tail [-f] <file>] #
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...] #
[-usage [cmd ...]]
hdfs dfs -ls / 这条执行会列出/目录下的文件和目录
hdfs dfs -ls -R /这条会列出/目录下的左右文件,由于有-R参数,会在文件夹和子文件夹下执行ls操作。
[root@CentOS sysconfig]# hdfs dfs -mkdir -p /tt/test #新建文件夹
[root@CentOS ~]# touch 123.txt
[root@CentOS ~]# vi 123.txt
[root@CentOS ~]# hdfs dfs -copyFromLocal ~/123.txt /tt #复制文件到hdfs
[root@CentOS ~]# hdfs dfs -cat /tt/test/123.txt #查看文件
雲想衣山花形容
[root@CentOS 123123]# hdfs dfs -copyToLocal /tt/test/123.txt /usr/local/222.txt #可以把hdfs中的文件copy到本地
[root@CentOS 123123]# cd ..
[root@CentOS local]# ls
123123 222.txt bin etc games include lib lib64 libexec sbin share src
[root@CentOS local]# hdfs dfs -put 123123 /tt #将本地文件或目录(eg:123123)上传到HDFS中的路径( /tt)
[root@CentOS local]# hdfs dfs -ls /tt/ #查看文件夹下的目录
Found 2 items
-rw-r--r-- 1 root supergroup 22 2019-01-03 04:18 /tt/123.txt
-rw-r--r-- 1 root supergroup 0 2019-01-03 04:28 /tt/777.txt
[root@CentOS local]# hdfs dfs -rm -f /tt/123.txt #删除文件
19/01/03 03:54:55 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /tt/123.txt
[root@CentOS local]# hdfs dfs -rm -r /tt/test #删除文件夹
19/01/03 03:55:58 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /tt/test
[root@CentOS ~]# hdfs dfs -checksum /tt #查看文件大小
checksum: `/tt': Is a directory
[root@CentOS ~]# hdfs dfs -checksum /tt/123.txt
/tt/123.txt MD5-of-0MD5-of-512CRC32C 000002000000000000000000790c2cd6e313015e7896c41d37dce4d5
[root@CentOS local]# hdfs dfs -cp /tt/123.txt / #拷贝一个文件到另一个文件
[root@CentOS local]# hdfs dfs -touchz /tt/777.txt #创建文件
[root@CentOS local]# hdfs dfs -tail /tt/123.txt #显示文件最后的1KB内容到标准输出。
雲想衣山花形容
[root@CentOS local]# hdfs dfs -get /tt/777.txt /usr/local #.将文件或目录从HDFS中的路径(/tt/777.txt)拷贝到本地文件路径(/usr/local)
[root@CentOS local]# ls
123123 222.txt 777.txt
[root@CentOS local]# hdfs dfs -ls -R /tt/ #递归地显示子目录下的内容。
-rw-r--r-- 1 root supergroup 22 2019-01-03 04:18 /tt/123.txt
-rw-r--r-- 1 root supergroup 0 2019-01-03 04:28 /tt/777.txt
drwxr-xr-x - root supergroup 0 2019-01-03 04:40 /tt/test
-rw-r--r-- 1 root supergroup 22 2019-01-03 04:40 /tt/test/222.txt
[root@CentOS local]# hdfs dfs -chmod -R 755 /tt/123.txt
[root@CentOS local]# hdfs dfs -ls -R /tt/
-rwxr-xr-x 1 root supergroup 22 2019-01-03 04:18 /tt/123.txt
二、HDFS 架构的更多相关文章
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
HDFS简单介绍 HDFS全称是Hadoop Distribute File System,是一个能运行在普通商用硬件上的分布式文件系统. 与其他分布式文件系统显著不同的特点是: HDFS是一个高容错 ...
- HDFS 架构简述
HDFS 架构简述 Hadoop分布式文件系统(HDFS)是一个分布式的文件系统,运行在廉价的硬件上.它与现有的分布式文件系统有很多相似之处.然而与其他的分布式文件系统的差异也是显着的.HDFS是高容 ...
- HDFS概述(1)————HDFS架构
概述 Hadoop分布式文件系统(HDFS)是一种分布式文件系统,用于在普通商用硬件上运行.它与现有的分布式文件系统有许多相似之处.然而,与其他分布式文件系统的区别很大.HDFS具有高度的容错能力,旨 ...
- 06_Hadoop分布式文件系统HDFS架构讲解
mr 计算框架 假如有三台机器 统领者master 01 02 03 每台机器都有过滤的应用程序 移动数据 01机== 300M >mr 移动计算 java程序传递给各个机器(mr) ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- hadoop之hdfs架构详解
本文主要从两个方面对hdfs进行阐述,第一就是hdfs的整个架构以及组成,第二就是hdfs文件的读写流程. 一.HDFS概述 标题中提到hdfs(Hadoop Distribute File Syst ...
- 小记---------Hadoop读、写文件步骤,HDFS架构理解
Hadoop 是一个开源框架,可编写和运行分布式应用处理大规模数据 Hadoop框架的核心是HDFS 和 MapReduce HDFS是分布式文件系统(存储) MapReduce是分布式数据处理模型和 ...
- HDFS 架构解析
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点. 架构目标 任何一种软件框架或服务都是为了解决特定问题而产生的.还记得我们在 <分布式存储 ...
- Hadoop HDFS 架构设计
HDFS 简介 Hadoop Distributed File System,简称HDFS,是一个分布式文件系统. HDFS是高容错性的,可以部署在低成本的硬件之上,HDFS提供高吞吐量地对应用程序数 ...
- Hadoop学习笔记一(HDFS架构)
介绍 Hadoop分布式文件系统(HDFS)设计的运行环境是商用的硬件系统.他和现存的其他分布式文件系统存在很多相似点.不过HDFS和其他分布式文件系统的区别才是他的最大亮点,HDFS具有高容错的特性 ...
随机推荐
- thinkphp更新数据库的时候where('')为字符串
if($user->where('phone='.$phone)->save($dataList)){} if($user->where(array('phone' =>$ph ...
- ThreadLocal 理解
主要方法 public void set(T value); public T get(); private T setInitialValue(); public void set(T value) ...
- C语言——栈的基本运算在顺序栈上的实现
头文件 Seqstack.h #define maxsize 6 //const int maxsize = 6; // 顺序栈 typedef struct seqstack { int data[ ...
- Flink Flow
1. Create environment for stream computing StreamExecutionEnvironment env = StreamExecutionEnvironme ...
- Genymotion模拟器拖入文件报An error occured while deploying the file的错误
今天需要用到资源文件,需要将资源文件拖拽到sd卡中,但老是出现这个问题: 资源文件拖不进去genymotion.查看了sd的DownLoad目录,确实没有成功拖拽进去. 遇到这种问题的,我按下面的思路 ...
- SQL Server ->> FIRST_VALUE和LAST_VALUE函数
两个都是SQL SERVER 2012引入的函数.用于返回在以分组和排序后取得最后一行的某个字段的值.很简单两个函数.ORDER BY字句是必须的,PARITION BY则是可选. 似乎没什么好说的. ...
- ipsec验证xl2tpd报错:handle_packet: bad control packet!
使用ipsec和xl2tpd搭建好vpn后,使用ipsec密钥方式不能连接,显示 “连接的时候被远程服务器中止” 使用xl2tpd -D查看连接情况,尝试连接了许多次,错误如下: 开始不确定问题所在, ...
- IE浏览器兼容问题(下)——IE6的常见问题
IE6常见兼容性问题 1.盒模型问题 (1)DTD问题 DTD:文档定义类型,规定了要遵循的书写规范. 如果不写DTD,高级浏览器还是可以正常加载,IE6会以怪异模式进行加载. 盒模型:正常应该是外扩 ...
- HTTP常用状态码大全
HTTP状态码对照表 HTTP response codes 当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求.当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码 ...
- Manifold Learning: ISOMAP
转:http://hi.baidu.com/chb_seaok/item/faa54786a3ddd1d7d1f8cd0b 在常见的降维方法中,PCA和LDA是最为常用的两种降维方法.PCA是一种无监 ...