【HBase】带你了解一哈HBase的各种预分区
简单了解
概述
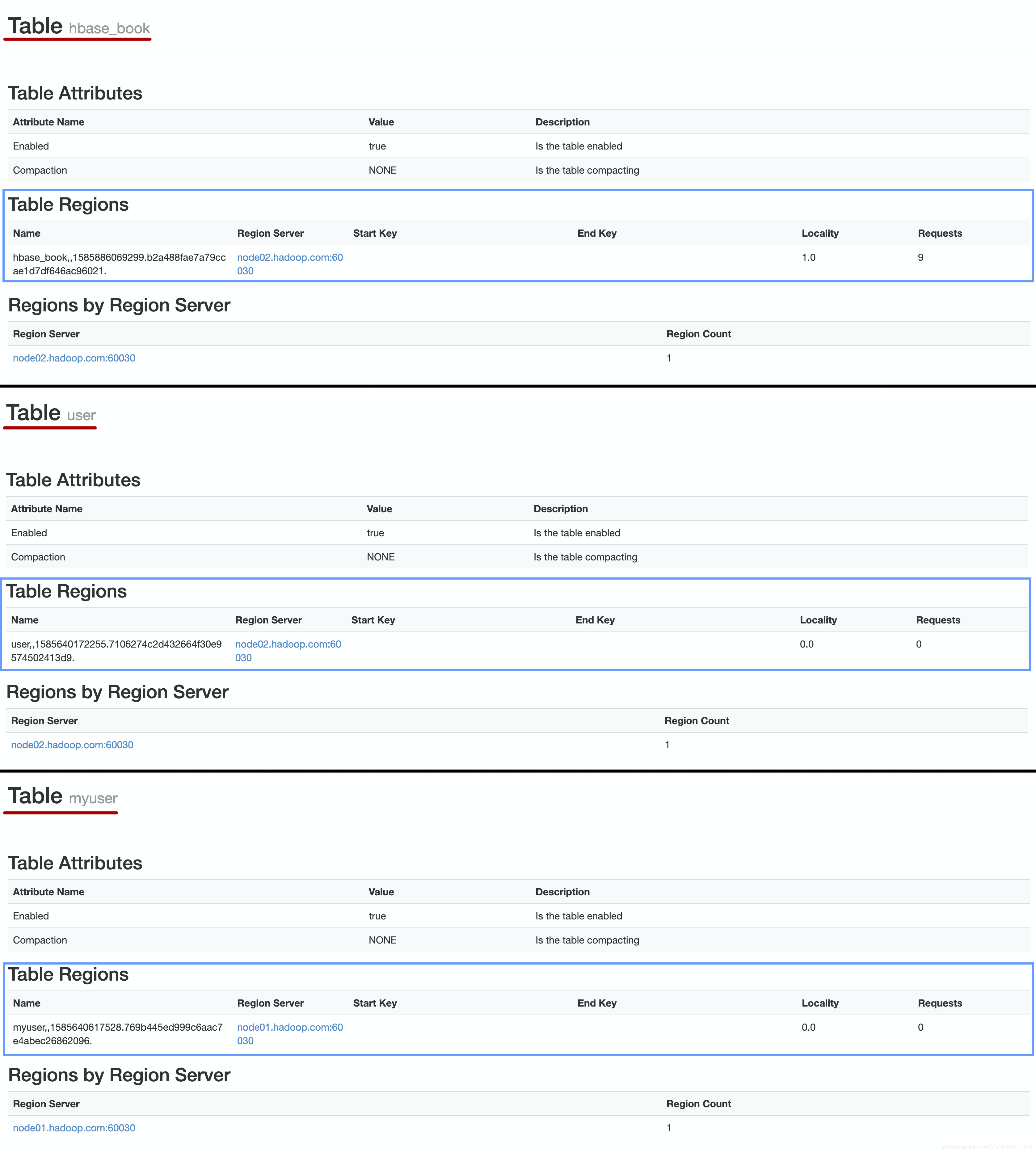
由上图可以看出,每一个表都有属于自己的一个Region,但Region内的数据达到10GB时,会进行分割,但仍会在同一个RegionServer上,而预分区的作用主要是增加数据读写效率、负载均衡、防止数据倾斜、方便集群容灾调度Region和优化Map数量
设置预分区
在设置预分区前要先明白一个概念,每一个Region都维护着从StartKey到EndKey的数据,如果加入的数据符合某个Region的rowKey范围,就把数据交给这个Region维护
比如说,现在有三个分区,它们的StartKey和EndKey分别是1-1000,1001-2000,2001-3000,现在如果有一条rowKey为1888的数据,那么他就会被分配到第二个Region中
预分区的设置方法一共有四种:
一、手动指定预分区
进入hbase shell输入一下命令
create 'staff','info','partition1',SPLITS => ['1000','2000','3000','4000']
二、使用16进制算法生成预分区
进入hbase shell输入一下命令
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
三、将分区规则写在文本文件中
首先在/export/servers目录下创建splits.txt文本文件,并输入一下内容
aaaa
bbbb
cccc
dddd
然后在hbase shell中执行以下命令
create 'staff3','partition2',SPLITS_FILE => '/export/servers/splits.txt'
四、使用JavaAPI进行预分区
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.testng.annotations.Test;
import java.io.IOException;
public class HbasePartition {
/**
* 通过javaAPI进行HBase的表的创建以及预分区操作
*/
@Test
public void hbaseSplit() throws IOException {
//获取连接
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
//自定义算法,产生一系列Hash散列值存储在二维数组中
byte[][] splitKeys = {{1,2,3,4,5},{'a','b','c','d','e'}};
//通过HTableDescriptor来实现我们表的参数设置,包括表名,列族等等
HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("stuff4"));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor("f1"));
//添加列族
hTableDescriptor.addFamily(new HColumnDescriptor("f2"));
admin.createTable(hTableDescriptor,splitKeys);
admin.close();
}
}

注意
在实际工作当中,创建表时一般都需要提前做预分区处理,一般来说每台服务器上面设置两个到五个的预分区,这么做可以更好地减少Split的过程,在设置预分区时,rowKey的设计尤为重要
关于rowKey的设计可以查看文章:【HBase】快速了解上手rowKey的设计技巧
【HBase】带你了解一哈HBase的各种预分区的更多相关文章
- 一文带你读懂 Hbase 的架构组成
hi,大家好,我是大D.今天咱们继续深挖一下 HBase 的架构组成. Hbase 作为 NoSQL 数据库的代表,属于三驾马车之一 BigTable 的对应实现,HBase 的出现很好地弥补了大数据 ...
- Hbase总结(一)-hbase命令,hbase安装,与Hive的区别,与传统数据库的区别,Hbase数据模型
Hbase总结(一)-hbase命令 下面我们看看HBase Shell的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下: 名称 命令表达式 创建表 create '表名称', ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
- 一脸懵逼学习HBase的搭建(注意HBase的版本)
1:Hdfs分布式文件系统存的文件,文件存储. 2:Hbase是存储的数据,海量数据存储,作用是缓存的数据,将缓存的数据满后写入到Hdfs中. 3:hbase集群中的角色: ().一个或者多个主节点, ...
- Hbase总结(五)-hbase常识及habse适合什么场景
当我们对于数据结构字段不够确定或杂乱无章非常难按一个概念去进行抽取的数据适合用使用什么数据库?答案是什么,假设我们使用的传统数据库,肯定留有多余的字段.10个不行,20个,可是这个严重影响了质量. 而 ...
- linux 下通过过 hbase 的Java api 操作hbase
hbase版本:0.98.5 hadoop版本:1.2.1 使用自带的zk 本文的内容是在集群中创建java项目调用api来操作hbase,主要涉及对hbase的创建表格,删除表格,插入数据,删除数据 ...
- hbase学习(二)hbase单机和高可用完全分布式安装部署
hbase版本 2.0.4 与hadoop兼容表http://hbase.apache.org/book.html#hadoop 我的 hadoop版本是3.1 1.单机版hbase 1.1解 ...
- 一条数据的HBase之旅,简明HBase入门教程-开篇
常见的HBase新手问题: 什么样的数据适合用HBase来存储? 既然HBase也是一个数据库,能否用它将现有系统中昂贵的Oracle替换掉? 存放于HBase中的数据记录,为何不直接存放于HDFS之 ...
- 一条数据的HBase之旅,简明HBase入门教程1:开篇
[摘要] 这是HBase入门系列的第1篇文章,主要介绍HBase当前的项目活跃度以及搜索引擎热度信息,以及一些概况信息,内容基于HBase 2.0 beta2版本.本系列文章既适用于HBase新手,也 ...
随机推荐
- Python-selenium-自动化测试模型
1.线性测试 优势:每一个脚本都是完整独立的,每一个脚本对应一个测试用例 缺点:开发成本高,会有重复操作重复脚本:维护成本也高,修改重复操作的脚本时,要逐一进行修改. 2.模块化驱动测试 把重复的操作 ...
- Jmeter命令行执行并生成HTML报告
前提:准备好jmeter脚本,找到jmeter配置文件查看生成的日志格式是否为csv,如果不是请改为csv 注意:使用命令执行jmeter脚本必须使用jmeter 3.0及以上版本1.使用命令行执行脚 ...
- L22 Data Augmentation数据增强
数据 img2083 链接:https://pan.baidu.com/s/1LIrSH51bUgS-TcgGuCcniw 提取码:m4vq 数据cifar102021 链接:https://pan. ...
- 4.加密与token(node+express)
一. 敏感数据加密1.安装并引入中间件 npm install utility const utils = require('utility')2.加密方法 function ...
- C++写日志方法调试
调试方法有很多 介绍一种奇怪的?调试方法哈哈 通过WriteLog记录返回值查看返回结果. string str_log;stringstream ssteam;ssteam << &qu ...
- JavaScript之预编译
javascript是一种解释性弱类型语言,在浏览器中执行时,浏览器会先预览某段代码进行语法分析,检查语法的正确与否,然后再进行预编译,到最后才会从上往下一句一句开始执行这段代码,简单得来说可以表示为 ...
- tensorflow1.0 数据队列FIFOQueue的使用
import tensorflow as tf #模拟一下同步先处理数据,然后才能取数据训练 #tensorflow当中,运行操作有依赖性 #1.首先定义队列 Q = tf.FIFOQueue(3,t ...
- C#线程学习笔记
本笔记摘抄自:https://www.cnblogs.com/zhili/archive/2012/07/18/Thread.html,记录一下学习,方便后面资料查找 一.线程的介绍 进程(Proce ...
- str_pad 和 filter_var
这两个函数都是php内置函数,filter_var可直接过滤,比如邮箱,ip等,str_pad可补充字符串eg: 1 => 001
- 2019-2020-1 20199328《Linux内核原理与分析》第二周作业
冯诺依曼体系结构的核心是: 冯诺依曼体系结构五大部分:控制器,运算器,存储器,输入输出设备. 常用的寄存器 AX.BX.CX.DX一般存放一些一般的数据,被称为通用寄存器,分别拥有高8位和低8位. 段 ...