Hadoop(十):本地IDEA链接远程Hadoop
本文使用的Hadoop为2.7.7,版本如果不同要下载相应版本的文件
配置本地的Hadoop库(不需完整安装,但是要有环境支持)
下载文件
https://github.com/speedAngel/hadoop2.7.7
解压到任意路径,没有中文字符和空格

把解压包的bin替换到解压路径
把bin中的Hadoop.dll复制到C:\Windows\System32
配置环境变量
HADOOP_HOME D:\Environment\hadoop-2.7.7
HADOOP_CONF_DIR D:\Environment\hadoop-2.7.7\etc\hadoop
YARN_CONF_DIR %HADOOP_CONF_DIR%
PATH %HADOOP_HOME%\bin
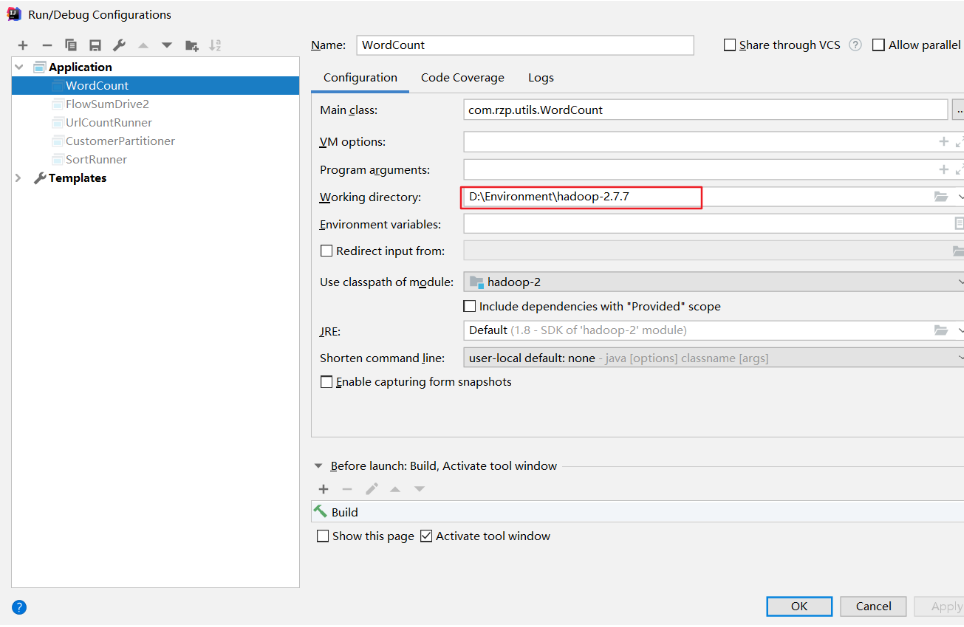
IDEA设置本地Hadoop路径
导入依赖(注意版本一致)
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
<!--工具类,可以复制对象-->
<!-- https://mvnrepository.com/artifact/commons-beanutils/commons-beanutils -->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.4</version>
</dependency>
</dependencies>
把集群的core-site.xml和hdfs-site.xml文件放到项目resource路径下。修改对应IP地址
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.98.129:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hop/hadoop-2.7.7/data/hopdata</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.98.130:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
运行的Main方法里首行添加
System.setProperty("HADOOP_USER_NAME","root");
System.setProperty("HADOOP_USER_PASSWORD","PASSWORD");
Hadoop(十):本地IDEA链接远程Hadoop的更多相关文章
- 码云git本地仓库链接远程仓库
原文链接: 点我 git提交时,仓库是空的,本地有源码 应该打开cmd 归到项目路径 然后输入git push -u origin master -f 是把本地的项目强制推送到空的仓库 git ...
- Hadoop将本地文件复制到Hadoop文件系统
代码: package com.hadoop; import java.io.BufferedInputStream; import java.io.FileInputStream; import j ...
- eclipse 远程链接访问hadoop 集群日志信息没有输出的问题l
Eclipse插件Run on Hadoop没有用到hadoop集群节点的问题参考来源 http://f.dataguru.cn/thread-250980-1-1.html http://f.dat ...
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...
- cdh5 hadoop redhat 本地仓库配置
cdh5 hadoop redhat 本地仓库配置 cdh5 在网站上的站点位置: http://archive-primary.cloudera.com/cdh5/redhat/6/x86_64/c ...
- 【征文】Hadoop十周年特别策划——我与Hadoop不得不说的故事
2016年是Hadoop的十周年生日,在今年,CSDN将以技术和实战为主题与大家共同为Hadoop庆生.其主要内容包含Hadoop专业词典.系列视频技术解析.Hadoop行业实践.线上问答.线下沙龙. ...
- Hadoop十年解读与发展预测
编者按:Hadoop于2006年1月28日诞生,至今已有10年,它改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,形成了自己的极其火爆的技术生态圈,并受到非常广泛的应用.在2016年Ha ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- eclipse连接远程hadoop集群开发时权限不足问题解决方案
转自:http://blog.csdn.net/shan9liang/article/details/9734693 eclipse连接远程hadoop集群开发时报错 Exception in t ...
随机推荐
- MySQL 整体架构一览
MySQL 在整体架构上分为 Server 层和存储引擎层.其中 Server 层,包括连接器.查询缓存.分析器.优化器.执行器等,存储过程.触发器.视图和内置函数都在这层实现.数据引擎层负责数据的存 ...
- 利用Python爬取OPGG上英雄联盟英雄胜率及选取率信息
一.分析网站内容 本次爬取网站为opgg,网址为:” http://www.op.gg/champion/statistics” 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53 ...
- Matplotlib数据可视化(7):图片展示与保存
In [1]: import os import matplotlib.image as mpimg from PIL import Image import matplotlib.pyplot as ...
- SQL逗号合并一列多行的值
select stuff((select ','+行名 from 表名 for xml path('')),1,1,'')
- C++ 别踩白块小游戏练习
#include <iostream> #include <stdio.h> #include <stdlib.h> #include <easyx.h> ...
- Python习题集(三)
每天一习题,提升Python不是问题!!有更简洁的写法请评论告知我! https://www.cnblogs.com/poloyy/category/1676599.html 题目 写一个小程序:控制 ...
- docker系列详解<一>之docker安装
1.Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker . 通过 uname -r 命令查看你当前的内核版本 $ ...
- 3. webdriver的常用方法
WebDriver常用方法: clear(): 清除文本. send_keys (value): 模拟按键输入. click(): 单击元素. submit():用于提交表单 from seleniu ...
- 手写简单IOC
ReflectUtils.java (反射工具类) package top.icss.ioc; import java.io.File; import java.io.FileFilter; impo ...
- 浏览器与DNS解析过程
浏览器解析 1.地址栏输入地址后,浏览器检查自身DNS缓存 地址栏输入chrome://net-internals/#dns 查看. 2.浏览器缓存中未找到,那么Chrome会搜索操作系统自身的DNS ...