高性能可扩展mysql 笔记(四)项目分区表演示
个人博客网:https://wushaopei.github.io/ (你想要这里多有)
登录日志的分区
如何为Customer_login_log表分区?
从以下两个业务场景入手:
- 用户每次登陆都会记录customer_login_log入职
- 用户登录日志保存一年,一年后可以删除
1、登录日志表的分区类型及分区键确定:
分区类型: 使用RANGE分区
以login_time作为分区键
2、创建分区表:
CREATE TABLE `crn`.`customer_login_log`(
customer_id INT UNSIGNED not null,
login_time datetime not null,
login_ip int UNSIGNED NOT NULL,
login_type TINYINT NOT NULL
)ENGINE = INNODB
PARTITION BY RANGE(YEAR(login_time))(
PARTITION p0 values less than(2015),
PARTITION p2 VALUES less than(2016),
PARTITION p3 VALUES less than(2017));
结果截图:

插入分区数据:
INSERT INTO customer_login_log(customer_id,login_time,login_ip,login_type)
VALUES(1001,'2015-01-25',0,1),(1001,'2015-07-1',0,1),(1001,'2015-10-1',0,1),(1001,'2016-3-1',0,1),(1001,'2016-9-1',0,1);

默认匹配规则说明:
创建2条2020年的数据,
INSERT INTO customer_login_log(customer_id,login_time,login_ip,login_type)
VALUES(1001,'2020-01-25',0,1),(1001,'2020-07-1',0,1);
创建分区范围分别为2019及2021年的分区:
ALTER TABLE customer_login_log add PARTITION(PARTITION p5 values less than(2019));
ALTER TABLE customer_login_log add PARTITION(PARTITION p6 values less than(2021));
最终匹配结果:

新创建的2020年的数据都被匹配到了2021年的分区区间,这是由于在没有创建相应分区的情况下,其会默认匹配到最近的规则的分区区域。有鉴于此,当创建的时间信息超出当前已定义的范围时,需根据规则及时创建新的分区,已规范数据的管理。
3、删除分区--同步删除分区内数据:
ALTER TABLE customer_login_log drop PARTITION p6;
分区表被删除:


在这里对过期数据的删除不需要通过在数据库进行查询等操作,提高了对数据的处理效率,减少了不必要的运算操作
3、分区数据迁移
创建新分区表:arch_customer_login_log
CREATE TABLE arch_customer_login_log(
customer_id INT UNSIGNED not null,
login_time datetime not null,
login_ip int UNSIGNED NOT NULL,
login_type TINYINT NOT NULL
)ENGINE = INNODB
当前customer_login_log 分区表中的数据:

这里将p3的数据迁移到新表中:
ALTER table customer_login_log exchange PARTITION p3 WITH TABLE arch_customer_login_log;
迁移后的原表 customer_login_log

迁移后的新表arch_customer_login_log

新表arch_customer_login_log的分区信息:
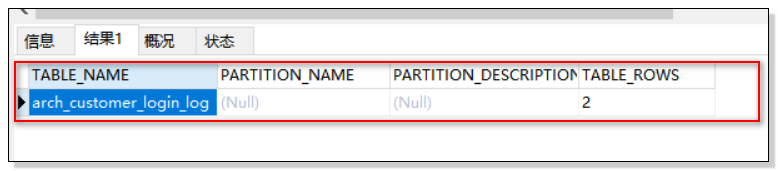
由截图可知,分区表表名为空、归档规则为空;数据量为2条
实现分区迁移的两个条件:
①mysql版本要大于5.7;
②归档的分区日志表要属于非分区表,归档的分区表和迁移的分区表数据结构必须相同,并且不能有外键约束;
满足以上两个条件的多个分区之间就可以进行分区数据的迁移了.
归档分区表到相应的存储引擎:
ALTER TABLE arch_customer_login_log ENGINE=archive
使用分区表的注意事项:
- 结合业务场景选择分区键,避免跨分区查询;
- 对分区表进行查询最好在WHERE从句中包含分区键;
- 具有主键或唯一索引的键,主键或唯一索引必须是分区键的一部分。
高性能可扩展mysql 笔记(四)项目分区表演示的更多相关文章
- 高性能可扩展mysql 笔记(三)Hash分区、RANGE分区、LIST分区
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.MySQL分区表操作 1.定义:数据库表分区是数据库基本设计规范之一,分区表在物理上表现为多个文件, ...
- 高性能可扩展mysql 笔记(一)数据库表、索引、SQL语句设计规范
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 项目说明:该笔记的背景为电商平台项目,电商项目由于其高并发.多线程.高耗能等特性,在众多的项目类型中涉及 ...
- 高性能可扩展mysql 笔记(六) SQL执行计划及分页查询优化、分区键统计
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 常见业务处理 一.使用数据库处理常见业务: 案例: 如何对评论进行分页展示 使用 EXPLAIN 获得s ...
- 高性能可扩展mysql 笔记(五)商品实体、订单实体、DB规划
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.商品模块 商品实体信息所存储的表包括: 品牌信息表: create table `brand_i ...
- 高性能可扩展mysql 笔记(二)用户模型设计、用户实体表结构设计、设计范式
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.用户模型设计 电商羡慕中用户模型的设计涉及以下几个部分: 以电商平台京东的登录.注册页面作为例: ...
- 高性能可扩展MySQL数据库设计及架构优化 电商项目(慕课)第3章 MySQL执行计划(explain)分析
ID:相同就从上而下,不同数字越大越优先
- mysql列属性auto(mysql笔记四)
常见的的是一个字段不为null存在默认值 没值得时候才去找默认值,可以插入一个null到 可以为null的行里 主键:可以唯一标识某条记录的字段或者字段的集合 主键设置 主键不可为null,声明时自动 ...
- C#可扩展编程之MEF学习笔记(四):见证奇迹的时刻
前面三篇讲了MEF的基础和基本到导入导出方法,下面就是见证MEF真正魅力所在的时刻.如果没有看过前面的文章,请到我的博客首页查看. 前面我们都是在一个项目中写了一个类来测试的,但实际开发中,我们往往要 ...
- MySql学习笔记四
MySql学习笔记四 5.3.数据类型 数值型 整型 小数 定点数 浮点数 字符型 较短的文本:char, varchar 较长的文本:text, blob(较长的二进制数据) 日期型 原则:所选择类 ...
随机推荐
- gulp基本使用
一.gulp是什么 gulp强调的是前端开发的工作流程,我们可以通过定义task事件定义事件的执行顺序,gulp去执行这些事件,构建整个前端开发的工作流程 gulp常见定义事件,例如: 变更静态资源 ...
- vue-双向响应数据底层原理分析
总所周知,vue的一个大特色就是实现了双向数据响应,数据改变,视图中引用该数据的部分也会自动更新 一.双向数据绑定基本思路 “数据改变,视图中引用该数据的部分也会自动更新“,从这句话,我们可以分析出以 ...
- 用最基本的遍历来实现判断字符串 a 是否被包含在字符串 b 中,并返回第一次出现的位置(找不到返回 -1)
用最基本的遍历来实现判断字符串 a 是否被包含在字符串 b 中,并返回第一次出现的位置(找不到返回 -1) 例子: a='12';b='1234567'; // 返回 0 a='47';b='1234 ...
- 王颖奇 20171010129《面向对象程序设计(java)》第十一周学习总结
实验十一 集合 实验时间 2018-11-8 1.实验目的与要求 (1) 掌握Vetor.Stack.Hashtable三个类的用途及常用API: (2) 了解java集合框架体系组成: (3) ...
- 在windows环境里,用Docker搭建Redis开发环境(新书第一个章节)
大家都知道高并发分布式组件的重要性,而且如果要进大厂,这些技术不可或缺.但这些技术的学习难点在于,大多数项目里的分布式组件,都是搭建在Linux系统上,在自己的windows机器上很难搭建开发环境,如 ...
- 数据结构——ArrayList的源码分析(你所有的疑问,都会被解答)
一.首先来看一下ArrayList的类图: 1,实现了RandomAccess接口,可以达到随机访问的效果. 2,实现了Serializable接口,可以用来序列化或者反序列化. 3,实现了List接 ...
- gather函数
gather(input, dim, index):根据 index,在 dim 维度上选取数据,输出的 size 与 index 一致 # input (Tensor) – 源张量 # ...
- 「雕爷学编程」Arduino动手做(40)——旋转编码器模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里 ...
- Django组件content-type使用方法详解
前言 参考博客:https://www.zhangshengrong.com/p/zD1yQJwp1r/ 一个表和多个表进行关联,但具体随着业务的加深,表不断的增加,关联的数量不断的增加,怎么通过一开 ...
- GeoServer2.17与Jetty9在Windows上的最佳安装实践
1 JDK的选择 我使用了adopted openjdk8.0.252,安装简便,只需添加2个环境变量(JAVA_HOME,JRE_HOME)即可. 我的安装路径: C:\SDKs\adoptopen ...