hive之基本架构
什么是Hive
hive是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员是用他们最为熟悉的SQL语言就可以进行海量的数据的处理、分析和统计工作,而不是必须掌握JAVA等变成语言和具备开发MapReduce程序的能力。Hive SQL实际上是先被SQL解析器进行解析然后被Hive框架解析成一个MapReduce可执行的计划,并且按照该计划生成MapReduce任务后交给Hadoop集群处理。
由于Hive SQL 是翻译为MapReduce任务后在Hadoop集群执行的,而Hadoop是一个批处理系统,所以Hive SQL是高延迟的,不但翻译成的MapReduce任务执行延迟高,而且任务的提交和处理过程也是非常的耗时。因此,Hive即使处理的数据量非常的小,在执行的过程中也会有一定的延迟现象。同时,Hive不能提供数据排序和查询缓存功能,也不提供在线事务处理,更不提供实时查询和记录的更新,因为HIVE本身被定义为处理大规模的离线数据集。如果需要实现实时查询或记录的更新,HBASE是一个不错的选择。
HIVE的基本架构
作为Hadoop的主要数据仓库解决方案,底层存储依赖于HDFS,而Hive SQL是主要交互接口,而真正的计算和执行则由MapReduce完成,它们之间的桥梁是Hive引擎。接下来,具体看下HIVE的引擎架构:
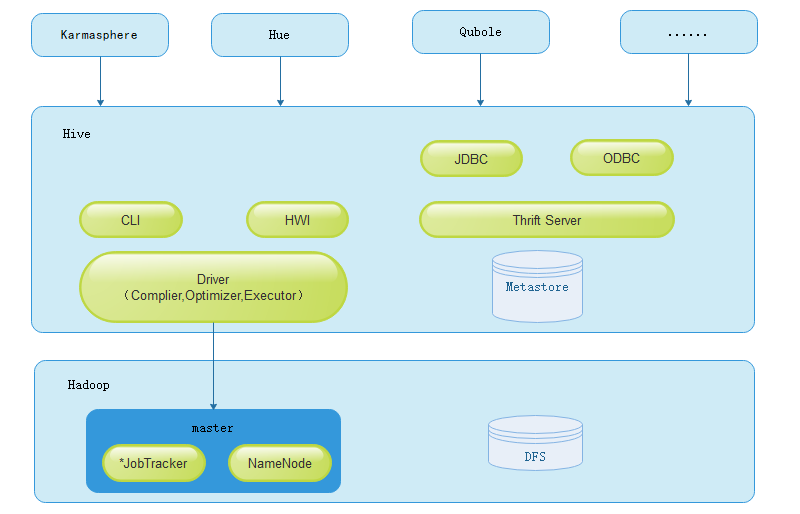
Hive的主要组件包括UI组件、Driver组件(Complier、Optimizer和Executor)、Metastore组件、CLI(Command Line Interface,命令行接口)、JDBC/ODBC、Thrift Server和Hive Web Interface(HWI)等。,接下来分别对这几个组件进行介绍。
- Drvier组件
该组件是Hive的核心组件,该组件包括Complier(编译器)、Optimizer(优化器)和Executor(执行器),它们的作用是对Hive SQL语句进行解析、编译优化、生成执行计划,然后调用底层MR计算框架。
- MetaStore组件
该组件是Hive用来负责管理元数据的组件。Hive的元数据存储在关系型数据库中,其支持的关系型数据库有Derby和mysql,其中Derby是Hive默认情况下使用的数据库,它内嵌在Hive中,但是该数据库只支持单会话,也就是说只允许一个会话链接,所以在生产中并不适用,其实其实在平时我们的测试环境中也很少使用。在我们日常的团队开发中,需要支持多会话,所以需要一个独立的元数据库,用的最多的也就是Mysql,而且Hive内部对Mysql提供了很好的支持。
- CLI
Hive的命令行接口
- Thrift Server
该组件提供JDBC和ODBC接入的能力,用来进行可扩展且跨语言的服务开发。Hive集成了该服务,能让不同的编程语言调用Hive的接口
- Hive Web Interface
该组件是Hive客户端提供的一种通过网页方式访问Hive所提供的服务。这个接口对应Hive的HWI组件
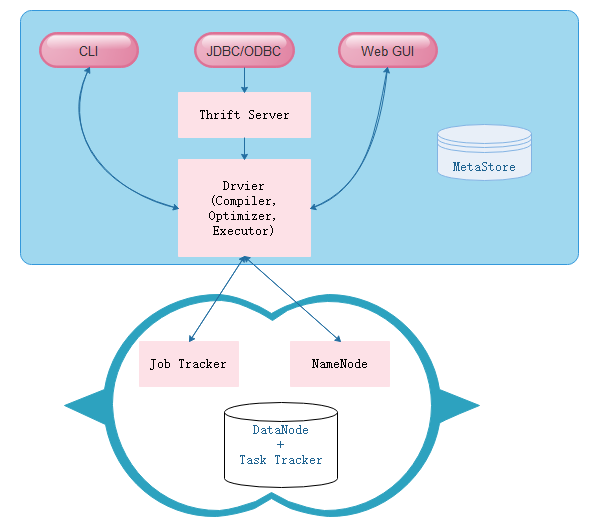
Hive通过CLI,JDBC/ODBC或HWI接受相关的Hive SQL查询,并通过Driver组件进行编译,分析优化,最后编程可执行的MapReduce任务,但是具体里面是怎么执行的,看图:
hive之基本架构的更多相关文章
- hive的体系架构及安装
1,什么是Hive? Hive是能够用类SQL的方式操作HDFS里面数据一个数据仓库的框架,这个类SQL我们称之为HQL(Hive Query Language) 2,什么是数据仓库? 存放数据的地方 ...
- hive介绍及架构设计
hive介绍及架构设计 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道MapReduce和Spark它们提供了高度抽象的编程接口便于用户编写分布式程序,它们具有极好的扩展性 ...
- Hive的配置| 架构原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hi ...
- hive基础及系统架构
1.hive是什么 hive是建立在hadoop上的数据仓库,提供数据的提取.转化和加载. 2.hive的数据存储 1]hive的数据存储基于hdfs 2]存储结构主要包括:数据库.文件.表.索引.视 ...
- 【hive】——Hive初始了解
1.没有接触,不知道这个事物是什么,所以不会产生任何问题.2.接触了,但是不知道他是什么,反正我每天都在用.3.有一定的了解,不够透彻.那么hive,1.我们对它了解多少?2.它到底是什么?3.hiv ...
- hive 搭建
Hive hive是简历再hadoop上的数据库仓库基础架构,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储,查询和分析存储再hadoop种的大规模数据机制,hive定 ...
- 基于hadoop的数据仓库工具:Hive概述
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学习成本低,可以通过类 ...
- Hive技术文档
Hive是什么? Hive是蜂房的意思,为什么hadoop上的这层数据仓库叫Hive? 因为生物学上蜂房是一个结构相当精良的建筑,取名Hive足见则个数据仓库在数据存储上也是堪称精良的.Hive是Fa ...
- 大数据时代的技术hive:hive介绍
我最近研究了hive的相关技术,有点心得,这里和大家分享下. 首先我们要知道hive到底是做什么的.下面这几段文字很好的描述了hive的特性: 1.hive是基于Hadoop的一个数据仓库工具,可以将 ...
随机推荐
- oracle死锁查询
select sess.sid ||','|| sess.serial#, lo.oracle_username, lo.os_user_name, ao.object_name, lo.locked ...
- JavaSE---环境配置
1.概述 1.1 PATH环境变量 a,Java程序 编译.运行时 需要用到java.javac命令,虽然计算机中已经安装了JDK,但是计算机不知道去哪里找这个命令: b,计算机如何查找命令呢 ...
- BeanUtils.copyProperties()拷贝属性时,忽略空值
把source的属性值复制给target的相同属性上,注意:双方需要复制的属性要有get.set方法 BeanUtils.copyProperties(source, target, PublicUt ...
- 【leetcode】979. Distribute Coins in Binary Tree
题目如下: Given the root of a binary tree with N nodes, each node in the tree has node.val coins, and th ...
- Tomcat负载均衡图片显示不正常解决方法
在部署一个Tomcat玩玩的时候,发现在做nginx负载均衡时,网站显示不正常,图片会变得很大.测试了半天都没成功,最后查找资料,才发现Tomcat负载均衡时Session处理有问题,Session是 ...
- RzPageControl(pagecontrol)
实现多标签的动态添加,切换,关闭 使用RzPageControl来实现多标签页使用菜单来打开标签页,通过标签页的caption来判断将标签页是否已经被打开过了.1.创建标签页,并判断是否是已经打开过的 ...
- K-th Closest Distance
题目链接 题意:n个数,q次查询,查询[l , r] 内, | a[i] - p | 第k大的数 思路:主席树维护下权值大小,二分答案,查询区间[p - mid, p + mid] 的个数 #incl ...
- [CSP-S模拟测试41]题解
中间咕的几次考试就先咕着吧…… A.夜莺与玫瑰 枚举斜率.只考虑斜率为正且不平行于坐标轴的直线,最后把$ans\times 2$再$+1$即可. 首先肯定需要用$gcd(i,j)==1$确保斜率的唯一 ...
- selenium IDE 安装环境配置
- springboot-redis相关配置整理
1.pom.xml引入对应数据文件 <dependency> <groupId>org.springframework.boot</groupId> <art ...