Centos7安装elasticsearch6.3及ik分词器,设置开机自启
参考Elasticsearch 在CentOs7 环境中开机启动
建议虚拟机的内存大小为4G
1. 新建一个用户john
出于安全考虑,elasticsearch默认不允许以root账号运行。
创建用户:
useradd john
设置密码:
passwd john
切换用户:
su - john
2. 上传安装包,并解压
我们将安装包上传到:/home/john目录

tar zxf elasticsearch-6.3.0.tar.gz
mv elasticsearch-6.3.0 elasticsearch
3. 修改配置
cd elasticsearch/config/
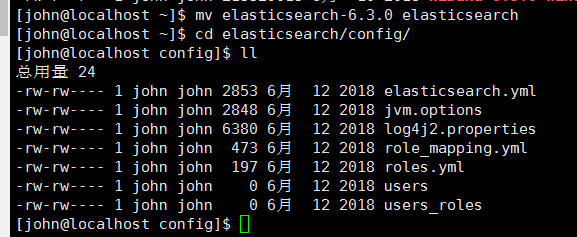
# 编辑jvm.options:
vim jvm.options
默认配置如下:
-Xms1g
-Xmx1g
内存占用太多了,我们调小一些:
-Xms512m
-Xmx512m

- elasticsearch.yml
vim elasticsearch.yml
- 修改数据和日志目录:
path.data: /home/john/elasticsearch/data # 数据目录位置
path.logs: /home/john/elasticsearch/logs # 日志目录位置
# 默认只允许本机访问,修改为0.0.0.0后则可以远程访问
network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问

我们把data和logs目录修改指向了elasticsearch的安装目录。但是这两个目录并不存在,因此我们需要创建出来。
进入elasticsearch的根目录,然后创建:
mkdir data
mkdir logs
设置 max_map_count
- 切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
- 添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
目前我们是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。
elasticsearch.yml的其它可配置信息:
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
4. 运行
su john
cd /home/john/elasticsearch/bin
./elasticsearch

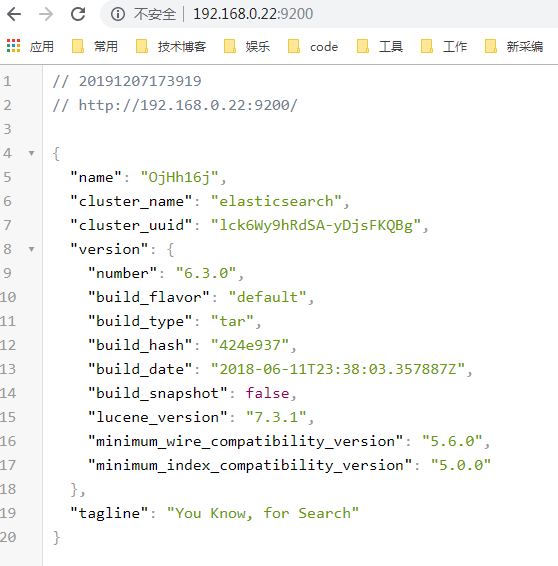
表明elasticserarch初步启动成功
# 设置后台启动
./elasticsearch -d
5. 设置开机自启
一:先查看当前的开机启动服务;
chkconfig --list

二:创建es 的系统启动服务文件,进入到 cd /etc/init.d 目录;
cd /etc/init.d 【进入到目录】
vi elasticsearch 【创建es系统启动服务文件】
三:编写启动脚本;
#!/bin/bash
#chkconfig: 345 63 37
#description: elasticsearch
#processname: elasticsearch-5.4.0
export ES_HOME=/home/john/elasticsearch/ 【这个目录是你Es所在文件夹的目录】
case $1 in
start)
su john<<! 【es 这个是启动es的账户,如果你的不是这个记得调整】
cd $ES_HOME
./bin/elasticsearch -d -p pid
exit
!
echo "elasticsearch is started"
;;
stop)
pid=`cat $ES_HOME/pid`
kill -9 $pid
echo "elasticsearch is stopped"
;;
restart)
pid=`cat $ES_HOME/pid`
kill -9 $pid
echo "elasticsearch is stopped"
sleep 1
su john<<! 【es 这个是启动es的账户,如果你的不是这个记得调整】
cd $ES_HOME
./bin/elasticsearch -d -p pid
exit
!
echo "elasticsearch is started"
;;
*)
echo "start|stop|restart"
;;
esac
exit 0
记得 删除笔者的[中文提示]
保存退出
四:修改文件权限;
chmod 777 elasticsearch
五:添加和删除服务并设置启动方式;
chkconfig --add elasticsearch #【添加系统服务】
chkconfig --del elasticsearch #【删除系统服务】
六:关闭和启动服务;
service elasticsearch start #【启动】
service elasticsearch stop #【停止】
service elasticsearch restart #【重启】
七:设置服务是否开机启动;
chkconfig elasticsearch on #【开启】
chkconfig elasticsearch off #【关闭】
验证是否已启动命令:
ps -ef | grep elasticsearch #【查看是否有es的进程】
结束进程命令用kill -9 进程ID;
6. 安装ik分词器
cd /home/john/
unzip elasticsearch-analysis-ik-6.3.0.zip -d ik-analyzer
mv ik-analyzer/ elasticsearch/plugins/
service elasticsearch restart
测试分词器是否安装成功
在kibana中输入如下
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
常见错误
错误1:内核过低
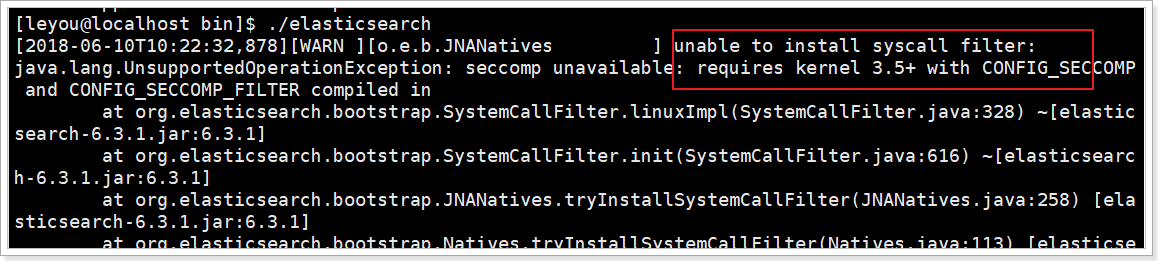
使用的是centos6,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。不过没关系,我们禁用这个插件即可。
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
然后重启
错误2:文件权限不足
再次启动,又出错了:
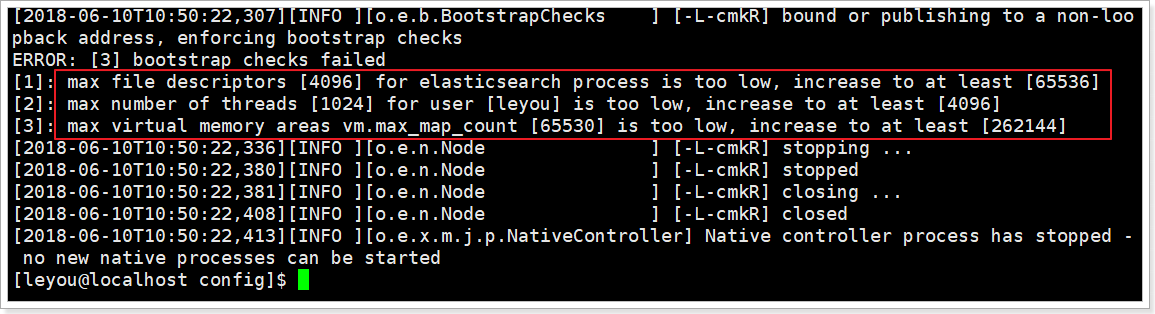
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
我们用的是leyou用户,而不是root,所以文件权限不足。
首先用root用户登录。
然后修改配置文件:
vim /etc/security/limits.conf
添加下面的内容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 4096
* hard nproc 4096
错误3:线程数不够
刚才报错中,还有一行:
[1]: max number of threads [1024] for user [leyou] is too low, increase to at least [4096]
这是线程数不够。
继续修改配置:
vim /etc/security/limits.d/90-nproc.conf
修改下面的内容:
* soft nproc 1024
改为:
* soft nproc 4096
错误4:进程虚拟内存
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
vm.max_map_count:限制一个进程可以拥有的VMA(虚拟内存区域)的数量,继续修改配置文件, :
vim /etc/sysctl.conf
添加下面内容:
vm.max_map_count=655360
然后执行命令:
sysctl -p
5.重启终端窗口
所有错误修改完毕,一定要重启你的 Xshell终端,否则配置无效。
Centos7安装elasticsearch6.3及ik分词器,设置开机自启的更多相关文章
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- linux(centos 7)下安装elasticsearch 5 的 IK 分词器
(一)到IK 下载 对应的版本(直接下载release版本,避免mvn打包),下载后是一个zip压缩包 (二)将压缩包上传至elasticsearch 的安装目录下的plugins下,进行解压,运行如 ...
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- ElasticSearch6.5.0 【安装IK分词器】
不得不夸奖一下ES的周边资源,比如这个IK分词器,紧跟ES的版本,卢本伟牛逼!另外ES更新太快了吧,几乎不到半个月一个小版本就发布了!!目前已经发了6.5.2,估计我还没怎么玩就到7.0了. 下载 分 ...
- Windows下安装Elasticsearch6.4.1和Head,IK分词器
所需运行环境 1.安装jdk1.8(步骤略) 2.安装git(步骤略)3.安装nodejs(步骤略) 一.ElasticSearch的安装 下载elasticsearch6.4.1,将下载后的es解压 ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0 查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasti ...
- Elastic Stack 笔记(二)Elasticsearch5.6 安装 IK 分词器和 Head 插件
博客地址:http://www.moonxy.com 一.前言 Elasticsearch 作为开源搜索引擎服务器,其核心功能在于索引和搜索数据.索引是把文档写入 Elasticsearch 的过程, ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
随机推荐
- Editplus注册码生成代码
function generate_editplus_regcode(username) { var list = [0,49345,49537,320,49921,960,640,49729,506 ...
- win7,win10 系统上搭建testlink1.9.18环境实操步骤
Windows7,10系统上安装TestLink1.9.18(基于xampp) 写于:2018.11.28 二次排版微调:2019.01.01 如遇本文资料缺失,可点击百度网盘查看原始资料. 链接:h ...
- python 学习之路(1)
1变量的使用以及原理 先定义一个变量 变量的类型 变量的命名 01变量的命名 变量名 = 值 左边是变量名 右边是值 又叫做赋值 上面是ipython的交互模式的 那我们看看在pycharm里面如何输 ...
- 使用R进行方差分析
eff=c(58.2,52.6,56.2,41.2,65.3,60.8,49.1,42.8,54.1,50.5,51.6,48.4,60.1,58.3,70.9,73.2,39.2,40.7,75.8 ...
- 错误“Object reference not set to an instance of an object”的解决方法
在进行unity游戏制作的C#代码编写时,会遇到“NullReferenceException: Object reference not set to an instance of an objec ...
- java 判断Map集合中包含指定的键名,则返回true,否则返回false。
public static void main(String[] args) { Map map = new HashMap(); //定义Map对象 map.put("apple" ...
- Struts1与Struts2区别?
(1)Struts1执行过程: <1>Web容器启动的时候ActionServlet被初始化,加载struts-config.xml配置文件. <2>浏览器发送请求到Actio ...
- xpath元素定位方法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集.这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似.XPath 含有超过 100 个内建的函数.这些函数用于字符串值.数值 ...
- C++入门经典-例5.13-内存安全,被销毁的内存
1:当指针所指向的内存被销毁时,该区域不可复用.若有指针指向该区域,则需要将该指针置为空值(NULL)或者指向未被销毁的内存. 内存销毁实质上是系统判定该内存不是变成人员正常使用的空间,系统也回将它们 ...
- 【JVM】jstack 查询占用最大资源线程|排查死循环等
jstack 应用 首先通过:ps -ef|grep java 得到java pid 查看哪个线程占用最多资源: 找出该进程内最耗费CPU的线程,可以使用ps -Lfp pid或者ps -mp pid ...