spark浅谈(1):RDD
一、弹性分布式数据集
1.弹性分布式数据集(RDD)是spark数据结构的基础。它是一个不可变的分布式对象的集合,RDD中的每个数据集都被划分为一个个逻辑分区,每个分区可以在集群上的不同节点上进行计算。RDDs可以包含任何类型的Python,Java或者Scala对象,包括用户自定义的类。
2.正常情况下,一个RDD是一个只读的记录分区集合。RDDs可以通过对稳定存储数据或其他RDDs进行确定性操作来创建。RDD是一个可以在并行操作期间自动容错的元素的集合。发生错误之后可以进行重复的计算
3.创建RDD的方式:(1)在驱动程序中并行化现有的集合;(2)引用外部存储系统中的数据集。例如文件共享系统、HDFS、HBase、或者可以提供Hadoop输入格式的数据源
二、MapReduce的数据共享
1.MapReduce广泛应用于集群上使用分布式的并行算法来处理和生成大型数据集。允许用户使用高级运算符编写代码进行并行计算。而不需要担心工作分布和容错。
2.不幸的是,在最近使用的大多数框架中,在计算资源之间重用数据的唯一方式是将其写入到外部的稳定的存储系统中,,比如HDFS。
3.迭代式开发和交互式应用在并行作业中需要更快的数据共享。数据共享在MapReduce中是比较慢的,主要是因为其副本、串行化和磁盘IO。尽管有存储系统存在,但是大多数的Hadoop应用会划分超过90%的时间来做HDFS的读写操作
三、MapReduce的迭代式操作
1.交互过程
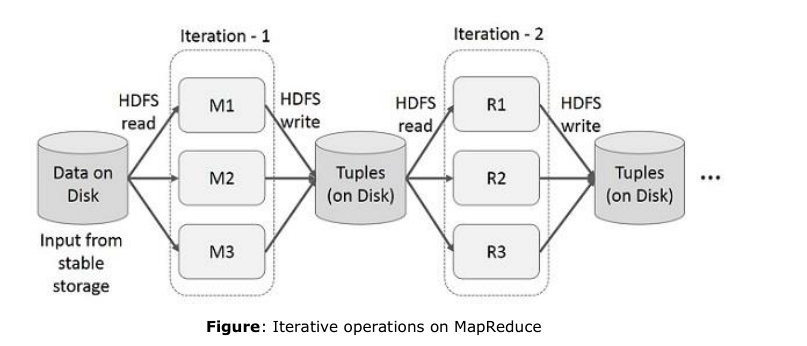
HDFS从稳定的输入流中读取数据,分成3个副本,在Iteration-1过程之后将其写入磁盘,多级MR是hadoop慢的主要原因。
2.使用sparkRDD进行数据共享
在MapReduce上数据共享慢的原因是因为副本,串行化以及磁盘IO。对于大多数Hadoop应用而言,它们花费超过90%的时间在左HDFS读写操作。认识到这个问题之后。研究人员们研发出来一个特殊的框架称之为Apache Spark。spark的核心思想是弹性分布式数据集(Resilient Distributed Datasets 简称RDD)。它支持在内存中进行计算的处理。这意味着它存储内存的状态作为对象,可以在作业之间跨作业和共享的对象。作业共享在内存中要比磁盘块10倍到100倍
3.在Spark RDD上的迭代式操作
下面的简图展示了在Spark RDD上的迭代式操作,它会存储中间结果在分布式内存而不是稳定的存储设备(比如磁盘)来使得系统更快。注意:如果分布式内存不足以存储中间结果(JOB的工作状态)

4.在Spark RDD上的交互操作
如果不同的查询运行在同一个数据集上,这个特殊的数据可以保存在内存上等待更好的执行时间
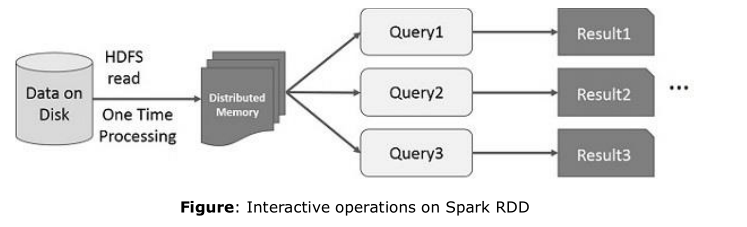
默认情况下,每一个变换的RDD在你运行一个Action的时候可以进行重复计算,你也可以在内存中持久化运算的结果,在这种情况下,Spark会继续在集群上保持元素以得到下次访问更快的处理,也支持在磁盘中持久化数据,或者通过众多的节点来进行复制
spark浅谈(1):RDD的更多相关文章
- spark浅谈(3):
一.shuffle操作 1.spark中特定的操作会触发我们都知道的shuffle事件,shuffle是spark进行数据重新分布的机制,这通常涉及跨执行程序和机器来赋值数据,使得混洗称为复杂而且昂贵 ...
- spark浅谈(2):SPARK核心编程
一.SPARK-CORE 1.spark核心模块是整个项目的基础.提供了分布式的任务分发,调度以及基本的IO功能,Spark使用基础的数据结构,叫做RDD(弹性分布式数据集),是一个逻辑的数据分区的集 ...
- 浅谈Spark应用程序的性能调优
浅谈Spark应用程序的性能调优 :http://geek.csdn.net/news/detail/51819 下面列出的这些API会导致Shuffle操作,是数据倾斜可能发生的关键点所在 1. g ...
- 浅谈压缩感知(二十):OMP与压缩感知
主要内容: OMP在稀疏分解与压缩感知中的异同 压缩感知通过OMP重构信号的唯一性 一.OMP在稀疏分解与压缩感知中的异同 .稀疏分解要解决的问题是在冗余字典(超完备字典)A中选出k列,用这k列的线性 ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 浅谈WebService的版本兼容性设计
在现在大型的项目或者软件开发中,一般都会有很多种终端, PC端比如Winform.WebForm,移动端,比如各种Native客户端(iOS, Android, WP),Html5等,我们要满足以上所 ...
随机推荐
- 【leetcode】1138. Alphabet Board Path
题目如下: On an alphabet board, we start at position (0, 0), corresponding to character board[0][0]. Her ...
- 【leetcode】1108. Defanging an IP Address
题目如下: Given a valid (IPv4) IP address, return a defanged version of that IP address. A defanged IP a ...
- LTM_本地流量管理(一)
基本元素及概念 Node:节点,即服务器的IP地址. Member:成员,即一个服务,用IP+端口表示. Pool:池:一个或多个Member的逻辑分组,一个Pool表示一个应用,每个Pool都有自己 ...
- 密码技术之密钥、随机数、PGP、SSL/TLS
第三部分:密码技术之密钥.随机数.PGP.SSL/TLS 密码的本质就是将较长的消息变成较短的秘密消息——密钥. 一.密钥 什么是密钥? (1)密钥就是一个巨大的数字,然而密钥数字本身的大小不重要,重 ...
- 虚拟机安装Windows系统,再安装orcale
本文出自:http://www.cnblogs.com/2186009311CFF/p/8724441.html 1.创建新虚拟机 2.选择自定义 3.选择workstation 5.x(据安装的系统 ...
- jquery +点击按钮,切换div内容,按钮加高亮
html: <div class="dw4"> <span class="dw">单位(次)</span> <div ...
- Codecombat 游戏攻略(计算机科学三)
第二关 赋值运算符-=字符串拼串循环语句while // 你可以把字符串连起来,或者把数字连接到字符串. // 一起唱歌,使用字符串连接: // X potions of health on the ...
- react native之封装离线缓存框架
请求数据=>本地有无缓存+缓存数据是否过期 =>可用 =>不可用 将代码封装成一个DataStore.js文件, 这里面主要提供:从本地获取数据,从网络获取数据,创建本地时间戳,请求 ...
- SQL的一对多,多对一,一对一,多对多什么意思?
1.一对多:比如说一个班级有很多学生,可是这个班级只有一个班主任.在这个班级中随便找一个人,就会知道他们的班主任是谁:知道了这个班主任就会知道有哪几个学生.这里班主任和学生的关系就是一对多. 2.多对 ...
- 如何为我们的程序编写开发文档——Java文档注释
Java文档注释是用于生成Java API文档的注释,通过在程序中的类.属性.方法部分加上注释,就可以用javadoc命令生成漂亮的API文档,是程序员进阶的必备技能. 注意,文档注释只说明紧跟其后的 ...