Selenium结合BeautifulSoup4编写简单爬虫
在学会了抓包,接口请求(如requests库)和Selenium的一些操作方法后,基本上就可以编写爬虫,爬取绝大多数网站的内容。
在爬虫领域,Selenium永远是最后一道防线。从本质上来说,访问网页实际上就是一个接口请求。请求url后,返回的是网页的源代码。
我们只需要解析html或者通过正则匹配提取出我们需要的数据即可。
有些网站我们可以使用requests.get(url),得到的响应文本中获取到所有的数据。而有些网页数据是通过JS动态加载到页面中的。使用requests获取不到或者只能获取到一部分数据。
此时我们就可以使用selenium打开页面来,使用driver.page_source来获取JS执行完后的完整源代码。
例如,我们要爬取,diro官网女包的名称,价格,url,图片等数据,可以使用requests先获取到网页源代码:
访问网页,打开开发者工具,我们可以看到所有的商品都在一个
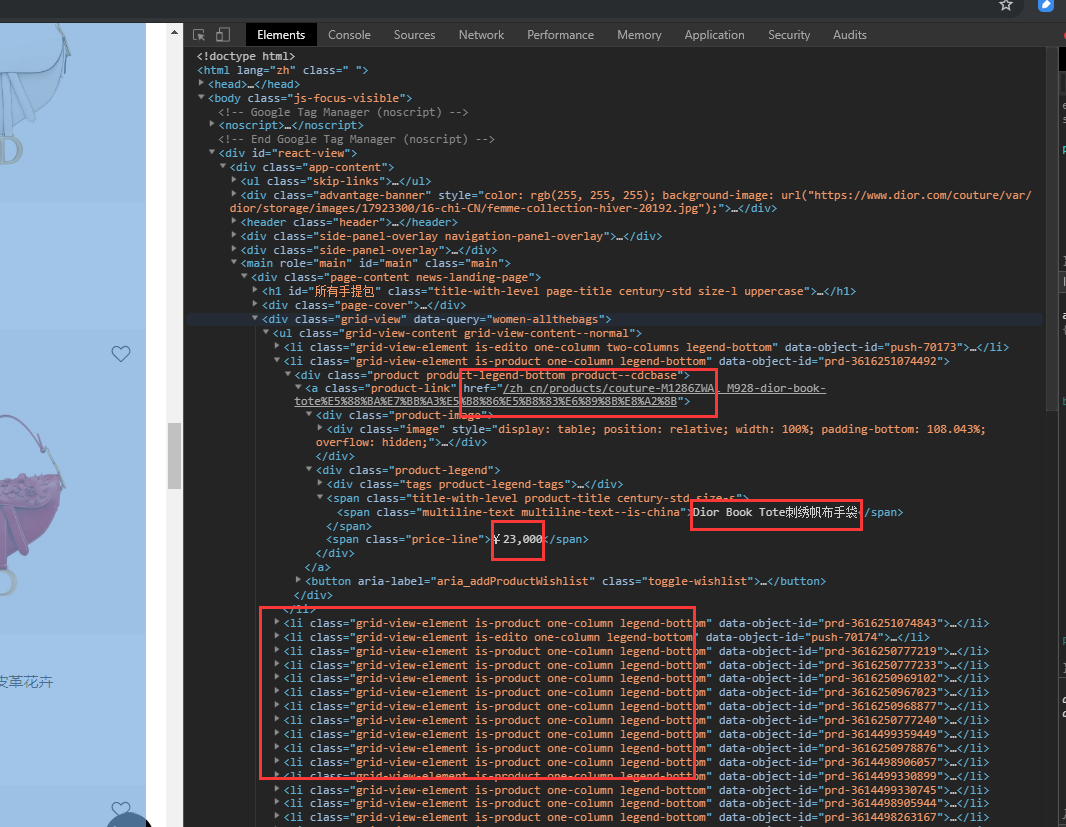
从html格式的源码中提取数据,有多种选择,可以使用xml.etree等等方式,bs4是一个比较方便易用的html解析库,配合lxml解析速度比较快。
bs4的使用方法为
from bs4 import BeautifulSoup
soup = BeautifulSoup(网页源代码字符串,'lxml')
soup.find(...).find(...)
soup.findall()
soup.select('css selector语法')
soup.find()可以通过节点属性进行查找,如,soup.find('div', id='节点id')或soup.find('li', class_='某个类名')或soup.find('标签名', 属性=属性值),当找到一个节点后,还可以使用这个节点继续在其子节点中查找。
soup.find_all()是查找多个,同样属性的节点,返回一个列表。
soup.select()是使用css selector语法查找,返回一个列表。
以下为示例代码:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://www.dior.cn/zh_cn/女士精品/皮具系列/所有手提包')
soup = BeautifulSoup(driver.page_source, 'lxml')
products = soup.select('li.is-product')
for product in products:
name = product.find('span', class_='product-title').text.strip()
price = product.find('span', class_='price-line').text.replace('¥', '').replace(',','')
url = 'https://www.dior.cn' + product.find('a', class_='product-link').attrs['href']
img = product.find('img').attrs['src']
sku = img.split('/')[-1]
print(name, sku, price)
driver.quit()
运行结果,如下图:
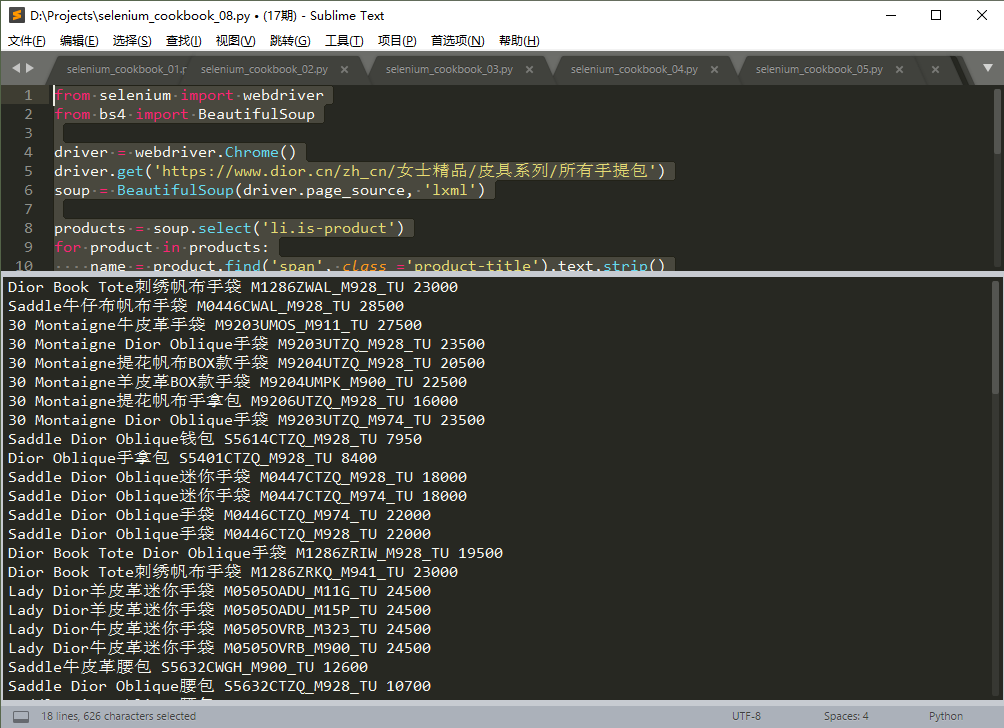
注:本例中,也可以使用requests.get()获取网页源代码,格式和使用selenium加载的稍有不同。
一般简单爬虫编写的步骤为:
- 进入列表页,打开开发者工具,刷新页面及向下滚动,查看新产品加载,是否能抓到XHR数据接口(直接返回JSON格式所有产品数据的接口)
- 如果有这种接口,尝试修改参数中的分页值,和请求总数值,看看是否能从一个接口返回所有的商品数据
- 如果只有Doc类型的接口返回页面,尝试使用requests.get()请求页面,分析响应文本,是否包含所有商品数据
- 如果requests获取不到商品数据或数据不全可以使用selenium加载页面,然后使用bs4解析提取,如果有多个页面,循环逐个操作即可。
Selenium结合BeautifulSoup4编写简单爬虫的更多相关文章
- 用python编写简单爬虫
需求:抓取百度百科python词条相关词条网页的标题和简介,并将数据输出在一个html表格中 入口页:python的百度词条页 https://baike.baidu.com/item/Python/ ...
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- 在python3中使用urllib.request编写简单的网络爬虫
转自:http://www.cnblogs.com/ArsenalfanInECNU/p/4780883.html Python官方提供了用于编写网络爬虫的包 urllib.request, 我们主要 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- python3实现简单爬虫功能
本文参考虫师python2实现简单爬虫功能,并增加自己的感悟. #coding=utf-8 import re import urllib.request def getHtml(url): page ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python开发简单爬虫(一)
一 .简单爬虫架构: 爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况 URL管理器:对将要爬取的和已经爬取过的URL进行管理:可取出带爬取的URL,将其传送给“网页下载器” 网页下载器:将URL指定 ...
- 用python语言编写网络爬虫
本文主要用到python3自带的urllib模块编写轻量级的简单爬虫.至于怎么定位一个网页中具体元素的url可自行百度火狐浏览器的firebug插件或者谷歌浏览器的自带方法. 1.访问一个网址 re= ...
随机推荐
- 数据仓库之抽取数据:通过openrowset执行存储过程
原文:数据仓库之抽取数据:通过openrowset执行存储过程 在做数据仓库时,最重要的就是ETL的开发,而在ETL开发中的第一步,就是要从原OLTP系统中抽取数据到过渡区中,再对这个过渡区中的数据进 ...
- leetcode-55. Jump Game · Array
题面 这个题面挺简单的,不难理解.给定非负数组,每一个元素都可以看作是一个格子.其中每一个元素值都代表当前可跳跃的格子数,判断是否可以到达最后的格子. 样例 Input: [2,3,1,1,4] Ou ...
- vue v-cloak 指令 处理页面显示源码
有时候页面会先出现源码,再显示解析的内容.可以通过v-cloak解决 v-cloak 这个指令会作为元素的一个属性一直保持到vue实例编译结束,即解析后移除此指令. /* 含有v-cloak的html ...
- tomcat压缩配置
问题描述:HPS打开登录页面(也就是用户输入用户名和密码的页面),要加载数据和程序,大概2M大小,在网络不好的情况下,要10几秒甚至几十秒,公司内网测试需要:3秒多 解决方法: 1. 打开登录页面,用 ...
- C# Parellel.For 和 Parallel.ForEach
简介:任务并行库(Task Parellel Library)是BCL的一个类库,极大的简化了并行编程. 使用任务并行库执行循环C#当中我们一般使用for和foreach执行循环,有时候我们呢的循环结 ...
- python excel基本操作
#coding=utf-8 ''' excel基本操作 ''' from openpyxl import Workbook wb=Workbook() ws1=wb.create_sheet('sh1 ...
- 【python】使用xlrd,xlwt来操作已存在的excel表
import xlrd import xlwt from xlutils.copy import copy # 打开想要更改的excel文件 old_excel = xlrd.open_workboo ...
- springbatch
springbatch job的创建使用 job:作业,是批处理中的核心概念,是batch操作的基础单元,每个job由多个step组成 step:步骤,任务完成的节点 每个job是由JobBuildF ...
- CSRF(cross-site request forgery )跨站请求攻击
CSRF(cross-site request forgery )跨站请求伪造,攻击者盗用了你的身份,以你的名义发送恶意请求,对服务器来说这个请求是完全合法的,但是却完成了攻击者所期望的一个操作,通过 ...
- 机器学习中的数学-强大的矩阵奇异值分解(SVD)及其应用
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...