机器学习算法-K-NN的学习 /ML 算法 (K-NEAREST NEIGHBORS ALGORITHM TUTORIAL)
1为什么我们需要KNN
现在为止,我们都知道机器学习模型可以做出预测通过学习以往可以获得的数据.
因为KNN基于特征相似性,所以我们可以使用KNN分类器做分类.

2KNN是什么?
KNN K-近邻,是一种简单的机器学习算法,目前被广泛使用分类.KNN做分类基于基于与 将要分类的点 的邻居的类别.

KNN 存储所有可以获得的例子,并基于相似性的度量做出分类 (也就是说和仓库里的特征进行对比,谁相近 就判为哪一类.)
k在KNN中是一个参数,指的是在多数表决过程中要包括的最近的邻居的数量(这里的意思就是找的所要判别的最近邻居的数量,比如K=5,就么就找5个最近的邻居,这5个中那一个标签占多数,则可以判别出书属于哪一个标签)
(k in KNN is a parameter that refer to the number of nearest neighbors to include in the majority voting process)
3我们怎样选择K 参数?
KNN算法基于特征相似性:选择一个正确的K值是一个参数调优的过程,这对于获得一个更好的精度是非常重要的.
(KNN Algorithm is based on feature similarity:choosing the right value of k is a process called parameter tuning, and is important for better accuracy)
对于不同的K值,最终分类的结果可能是不同的,见下图的情况.当选择K=3时,新样本被判别为方框,但是当选择K=7时新样本被判别为三角形
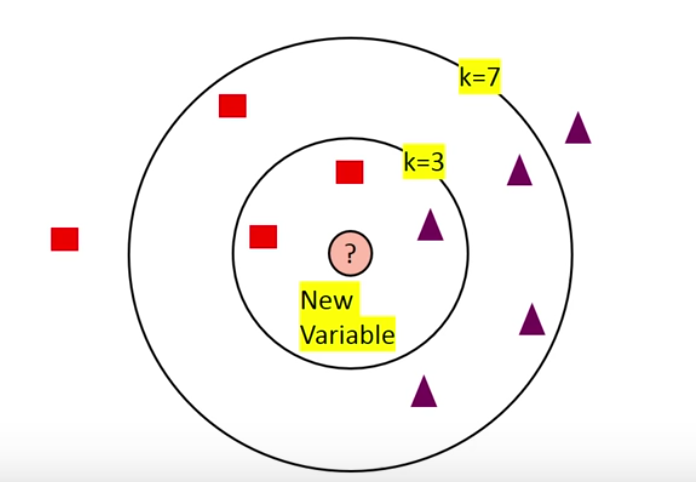
所以我们应该怎样选择一个好的K值呢?一般有下面两个注意点
(1) 对所有数据点数目开平方得到的数作为K值。这里需要注意对谁开平方,我目前理解的是对训练的数据集数量开平方。
(2) 选择K的奇数值是为了避免两类数据之间的混淆。例如在本教程视频中附带的一个例子,对训练数据集开平方得12,409 ,但是作者为了取奇数,用12-1=11把11作为K值。
见下图:

4我们什么时候使用KNN
we can use knn when {date is labled;data is noise free ;data is small}
对于数据集小的解释是:because KNN is a lazy learner ,so doesn't learn a discriminative function from the traing set (因为KNN是一个懒惰的学习者,所以不会从训练集中学习判别函数.对于小的数据集,KNN 是非常好的
)

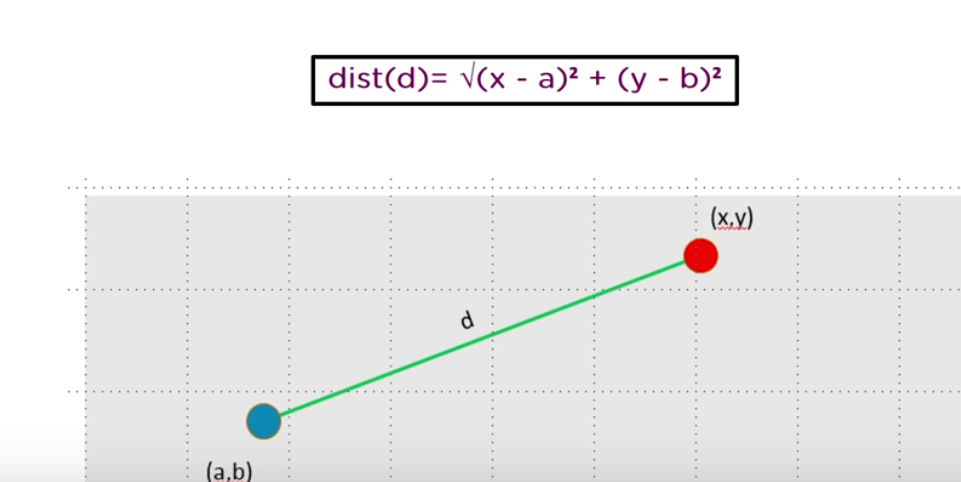
让我们通过计算来更清晰的理解欧式距离

5KNN是怎样工作的 ?
(1) 考虑一个数据集有两个变量:高度(cm)和重量(kg)并且数据集的每一个数据点被分类为正常和重量低的,基于给出的数据集,我们需要来分类一个数据点。怎样找到这个数据段最近的邻居呢? 考虑用欧式距离,那么什么是欧式距离呢?公式如下:
(2)然后,我们计算需要分类的 未知数据点的所有欧式距离显示在下表中。

(3)现在让我们以K=3 来计算出三个最近邻,因为这三个最近邻指示的标签都为Normal,所以待判别的数据点对应的类也是Normal

6 回顾KNN算法(recap the KNN)

KNN算法的回顾一共有4个点,分别为:
(1)指定一个正整数k和一个新样本。
(2)我们在数据库中选择最接近新样本的K个条目
(3)我们发现这些条目最常见的分类
(4)这是我们给新样品的分类
——————————分割线——————————
该视频的后面还讲述了一个使用KNN 算法进行预测糖尿病的实例,收录在我的博客中,如有兴趣,请到分类Python&Python_case查询。
机器学习算法-K-NN的学习 /ML 算法 (K-NEAREST NEIGHBORS ALGORITHM TUTORIAL)的更多相关文章
- 【机器学习笔记之一】深入浅出学习K-Means算法
摘要:在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. 在数据挖掘中,K-Means算法是一种c ...
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习之二:K-近邻(KNN)算法
一.概述 K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中 ...
随机推荐
- reCAPTCHA打不开的解决方法
reCAPTCHA打不开的解决方法 by WernerPosted on2018年1月8日 reCAPTCHA是国外广泛使用的验证码,但由于一些原因国内无法使用. 观察使用reCAPTCHA的网站,发 ...
- MongoDB 分片键分类与数据分发
In sharded clusters, if you do not use the _id field as the shard key, then your application must en ...
- php+超大文件上传
1 背景 用户本地有一份txt或者csv文件,无论是从业务数据库导出.还是其他途径获取,当需要使用蚂蚁的大数据分析工具进行数据加工.挖掘和共创应用的时候,首先要将本地文件上传至ODPS,普通的小文件通 ...
- P2679 子串 DP
P2679 子串 DP 从字符串A中取出\(k\)段子串,按原顺序拼接,问存在多少个方案使拼接的字符串与字符串B相同 淦,又是这种字符串dp 设状态\(ans[i][j][k]\)表示A串位置\(i\ ...
- Cogs 750. 栅格网络(对偶图)
栅格网络流 ★★☆ 输入文件:flowa.in 输出文件:flowa.out 简单对比 时间限制:1 s 内存限制:128 MB [问题描述] Bob 觉得一般图的最大流问题太难了,他不知道如何解决, ...
- (转)实验文档5:企业级kubernetes容器云自动化运维平台
部署对象式存储minio 运维主机HDSS7-200.host.com上: 准备docker镜像 镜像下载地址 复制 12345678910111213141516 [root@hdss7-200 ~ ...
- $.extend和$.fn.extend详解
一.定义 $.extend()属于j全局的Query对象,用于将一个或多个对象合并到目标对象上: $.fn.extend()属于jQuery的原型对象,用于在jQuery原型上扩展实例属性和方法. 二 ...
- 实现Callable接口实现多线程
package com.roocon.thread.t2; import java.util.concurrent.Callable; import java.util.concurrent.Exec ...
- LeetCode 第 153 场周赛
一.公交站间的距离(LeetCode-5181) 1.1 题目描述 1.2 解题思路 比较简单的一题,顺时针.逆时针两次遍历,就能解决. 1.3 解题代码 class Solution { publi ...
- [RK3399] /bin/sh: 1: lz4c: not found
CPU:RK3399 系统:Android 8.1 第一次在 RK3399 编译 Android 8.1 的系统,编译内核过程中报错如下: /bin/sh: : lz4c: not found mak ...