吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets,ensemble
from sklearn.model_selection import train_test_split def load_data_classification():
'''
加载用于分类问题的数据集
'''
# 使用 scikit-learn 自带的 digits 数据集
digits=datasets.load_digits()
# 分层采样拆分成训练集和测试集,测试集大小为原始数据集大小的 1/4
return train_test_split(digits.data,digits.target,test_size=0.25,random_state=0,stratify=digits.target) #集成学习AdaBoost算法分类模型
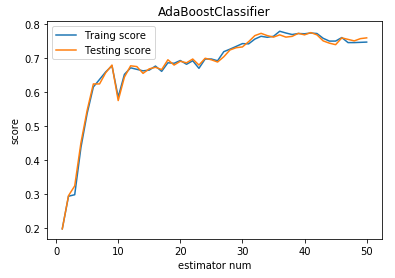
def test_AdaBoostClassifier(*data):
'''
测试 AdaBoostClassifier 的用法,绘制 AdaBoostClassifier 的预测性能随基础分类器数量的影响
'''
X_train,X_test,y_train,y_test=data
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 获取分类数据
X_train,X_test,y_train,y_test=load_data_classification()
# 调用 test_AdaBoostClassifier
test_AdaBoostClassifier(X_train,X_test,y_train,y_test)
def test_AdaBoostClassifier_base_classifier(*data):
'''
测试 AdaBoostClassifier 的预测性能随基础分类器数量和基础分类器的类型的影响
'''
from sklearn.naive_bayes import GaussianNB X_train,X_test,y_train,y_test=data
fig=plt.figure()
ax=fig.add_subplot(2,1,1)
########### 默认的个体分类器 #############
clf=ensemble.AdaBoostClassifier(learning_rate=0.1)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Decision Tree")
####### Gaussian Naive Bayes 个体分类器 ########
ax=fig.add_subplot(2,1,2)
clf=ensemble.AdaBoostClassifier(learning_rate=0.1,base_estimator=GaussianNB())
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="Traing score")
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="Testing score")
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_ylim(0,1)
ax.set_title("AdaBoostClassifier with Gaussian Naive Bayes")
plt.show() # 调用 test_AdaBoostClassifier_base_classifier
test_AdaBoostClassifier_base_classifier(X_train,X_test,y_train,y_test)

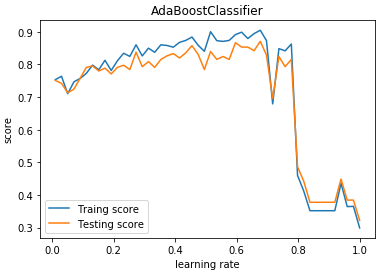
def test_AdaBoostClassifier_learning_rate(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率的影响
'''
X_train,X_test,y_train,y_test=data
learning_rates=np.linspace(0.01,1)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
traing_scores=[]
testing_scores=[]
for learning_rate in learning_rates:
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,n_estimators=500)
clf.fit(X_train,y_train)
traing_scores.append(clf.score(X_train,y_train))
testing_scores.append(clf.score(X_test,y_test))
ax.plot(learning_rates,traing_scores,label="Traing score")
ax.plot(learning_rates,testing_scores,label="Testing score")
ax.set_xlabel("learning rate")
ax.set_ylabel("score")
ax.legend(loc="best")
ax.set_title("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_learning_rate
test_AdaBoostClassifier_learning_rate(X_train,X_test,y_train,y_test)
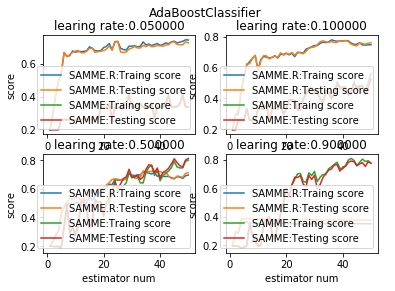
def test_AdaBoostClassifier_algorithm(*data):
'''
测试 AdaBoostClassifier 的预测性能随学习率和 algorithm 参数的影响
'''
X_train,X_test,y_train,y_test=data
algorithms=['SAMME.R','SAMME']
fig=plt.figure()
learning_rates=[0.05,0.1,0.5,0.9]
for i,learning_rate in enumerate(learning_rates):
ax=fig.add_subplot(2,2,i+1)
for i ,algorithm in enumerate(algorithms):
clf=ensemble.AdaBoostClassifier(learning_rate=learning_rate,algorithm=algorithm)
clf.fit(X_train,y_train)
## 绘图
estimators_num=len(clf.estimators_)
X=range(1,estimators_num+1)
ax.plot(list(X),list(clf.staged_score(X_train,y_train)),label="%s:Traing score"%algorithms[i])
ax.plot(list(X),list(clf.staged_score(X_test,y_test)),label="%s:Testing score"%algorithms[i])
ax.set_xlabel("estimator num")
ax.set_ylabel("score")
ax.legend(loc="lower right")
ax.set_title("learing rate:%f"%learning_rate)
fig.suptitle("AdaBoostClassifier")
plt.show() # 调用 test_AdaBoostClassifier_algorithm
test_AdaBoostClassifier_algorithm(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型的更多相关文章
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——人工神经网络与原始感知机模型
import numpy as np from matplotlib import pyplot as plt from mpl_toolkits.mplot3d import Axes3D from ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
随机推荐
- Aspx Ajax 调用 C#函数处理数据
jquery ajax 调用后台函数 var res; $.ajax({ type: "POST", url: "fast_index_overview.aspx/Get ...
- Java Set集合的详解
一,Set Set:注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素 用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复. 对象的相等性 引用到堆上同一个对象 ...
- AcWing 891. Nim游戏
//a1 ^ a2 ^ ··· ^ an = 0 –>先手必败: //a1 ^ a2 ^ ··· ^ an != 0 –>先手必胜: #include<iostream> us ...
- 杭电oj_1713——相遇周期(java实现)
question:相遇周期 思路: 首先将两个分数化为最简形式(也就是分子分母同时除以最大公约数) 然后题意是要求两个分数的最小公倍数 借助以下两个公式,就可以求出结果 1.最小公倍数*最大公约数 = ...
- 【Python】输入身份证号,输出出生日期
name = input("请输入你的名字:") id = input("请输入你的身份证号码:") year = id[6:10] month = id[10 ...
- altair package and altair_viewer
pip install altair pip install altair_viewer Altair is a declarative statistical visualization libra ...
- Spring Boot Actuator未授权访问
当我们发现某一个网页的logo是一篇叶子或者报错信息如下图所示的话,就可以尝试Spring Boot Actuator未授权访问. /dump - 显示线程转储(包括堆栈跟踪) /autoconfig ...
- 01-Java基本语法【前言、入门程序、常量、变量】
重点知识记录: 1.java语言是美国Sun公司在1995年推出的高级编程语言. 2.java语言主要应用在互联网程序的开发领域. 3.二进制转换 1)十进制数据转换成二进制数据:使用除以2获取余数的 ...
- Python MonkeyRunner 连接设备总是返回连接成功问题
device = mr.waitForConnection(1,deviceName) 当使用waitForConnection时,不管设备是否连接,device总是返回一个对象,所以没有办法通过 i ...
- Tomcat创建项目
查看项目信息 index.jsp默认首页 更新资源自动部署不用重启服务器,要用debug的方式启动 更新java代码和更新资源自动部署不用重启服务器,要用debug的方式启动