算法flink
和Yarn-Cluster模式不同,Session模式的资源在启动Yarn-Session时候就已经启动了,后续提交的作业全都在已申请的资源空间内运行,比较适合小而多的作业
# 启动yarn-session模式,不用启动flink集群
cm:
http://152.32.141.11:7180/cmf/login
登陆manager节点:
sudo su hdfs
yarn application -list
#查flink session的application id

#打开flink的web管理
http://manager.algorithm.opayride.com:8088/proxy/application_1572516566413_0919/#/job
#算法启动session:
/data/flink/bin/yarn-session.sh -n 20 -m 4 -qu flink -jm 1024 -tm 8192 -s 2 -d
-n 多少个容器
tm 每个容器的内存
-s 每个任务用多少slot
#在session上run job
cd /var/lib/hadoop-hdfs/src/oride-research/flink/flink-ufile
flink run -p 4 -c com.opay.research.hadoop.UfileJob target/flink-ufile-1.0.jar --prod
重启session:
1/ 在web管理界面上退出:
点running jobs,点运行的session job进去,把它cancel掉
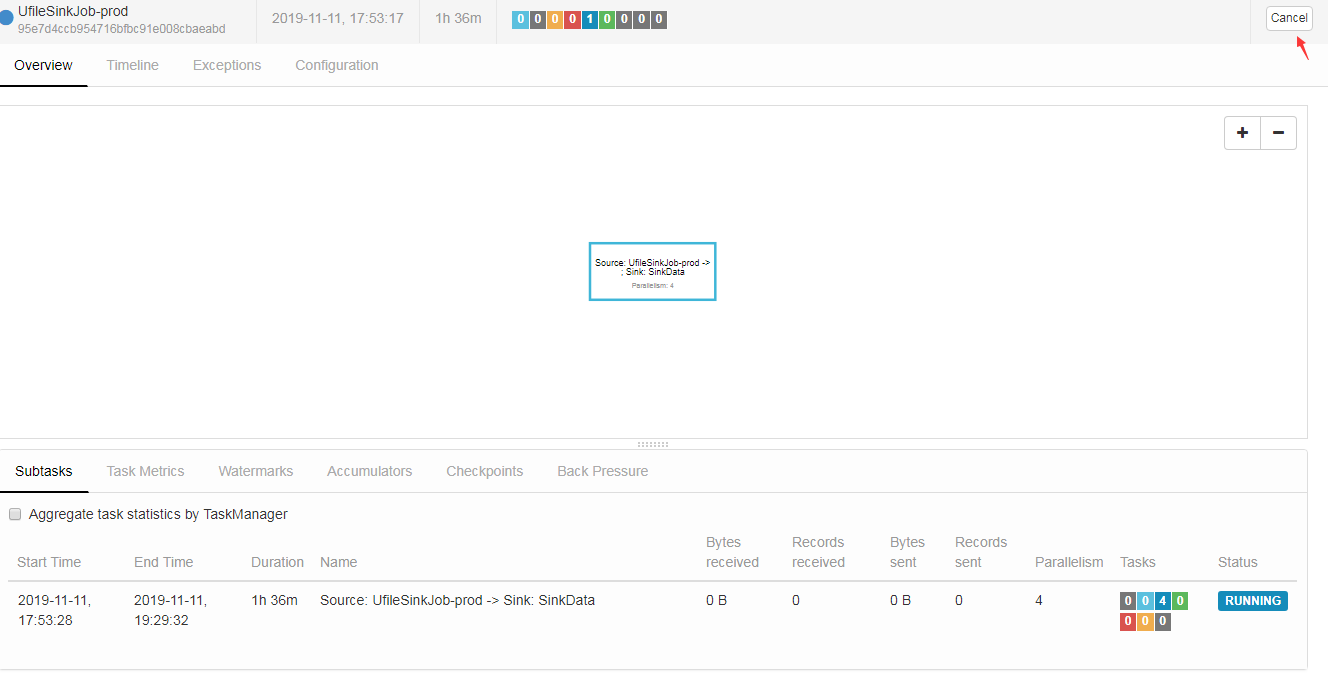
2/ 用yarn kill application xxx把flink作业kill
3/ 重新启动seesion
/data/flink/bin/yarn-session.sh -n 20 -m 4 -qu flink -jm 1024 -tm 8192 -s 2 -d
参数:
bin/yarn-session.sh –help
Usage:
Required
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached mode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-n,--container <arg> Number of YARN container to allocate (=Number of Task Managers)
-nl,--nodeLabel <arg> Specify YARN node label for the YARN application
-nm,--name <arg> Set a custom name for the application on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-sae,--shutdownOnAttachedExit If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such
as typing Ctrl + C.
-st,--streaming Start Flink in streaming mode
-t,--ship <arg> Ship files in the specified directory (t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
也可在启动时得到它的web地址
# 启动yarn-session模式,不用启动flink集群
[root@oldboy-node101 conf]# yarn-session.sh
2019-08-03 21:57:59,585 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Flink JobManager is now running on oldboy-node103:35244 with leader id 00000000-0000-0000-0000-000000000000.
JobManager Web Interface: http://oldboy-node103:35244
算法flink的更多相关文章
- (二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔: (总览)基于商品属性的相似商品推荐算法 (一)基于商品属性的相似商品推荐算法--整体框架及处理流程 (二)基于商品属性的相似商品推荐算法--Flink SQL实时计算实现商品的隐式评分 ( ...
- Peeking into Apache Flink's Engine Room
http://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html Join Processin ...
- Apache Flink vs Apache Spark——感觉二者是互相抄袭啊 看谁的好就抄过来 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率
Apache Flink是什么 Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理.这个目标看起来和Spark和类似.没错,Flink也在尝试解决 Spark在解决的问题.这两套系统都在 ...
- flink Transitive Closure算法,实现寻找新的可达路径
flink 使用Transitive Closure算法实现可达路径查找. 1.Transitive Closure是翻译闭包传递?我觉得直译不准确,意译应该是传递特性直至特性关闭,也符合本例中传递路 ...
- flink 实现ConnectedComponents 连通分量,增量迭代算法(Delta Iteration)实现详解
1.连通分量是什么? 首先需要了解什么是连通图.无向连通图.极大连通子图等概念,这些概念都来自数据结构-图,这里简单介绍一下. 下图是连通图和非连通图,都是无向的,这里不扩展有向图: 连通分量(con ...
- flink KMeans算法实现
更正:之前发的有两个错误. 1.K均值聚类算法 百度解释:k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类 ...
- flink 实现三角枚举EnumTriangles算法详解
1.三角枚举,从所有无向边对中找到相互连接的三角形 /** * @Author: xu.dm * @Date: 2019/7/4 21:31 * @Description: 三角枚举算法 * 三角枚举 ...
- flink PageRank详解(批量迭代的页面排名算法的基本实现)
1.PageRank算法原理 2.基本数据准备 /** * numPages缺省15个测试页面 * * EDGES表示从一个pageId指向相连的另外一个pageId */ public clas ...
- Flink 剖析
1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来,笔者为大家介绍Fl ...
随机推荐
- Java设计模式-策略模式实际应用场景
容错恢复机制 容错恢复机制是应用程序开发中非常常见的功能.那么什么是容错恢复呢?简单点说就是:程序运行的时候,正常情况下应该按照某种方式来做,如果按照某种方式来做发生错误的话,系统并不会 ...
- [Loj] 数列分块入门 1 - 9
数列分块入门 1 https://loj.ac/problem/6277 区间加 + 单点查询 #include <iostream> #include <cstdio> #i ...
- AGC032F One Third
很奇怪的一个题.看见了无从下手.概率期望好题. 给一个面积为 \(1\) 的圆,经过圆心随机幅角切直径 \(n\) 次,定义 \(f(x) = \min |S - \frac{1}{3}|\),其中 ...
- Windows下安装Elasticsearch6.4.1和Head,IK分词器
所需运行环境 1.安装jdk1.8(步骤略) 2.安装git(步骤略)3.安装nodejs(步骤略) 一.ElasticSearch的安装 下载elasticsearch6.4.1,将下载后的es解压 ...
- 由 Vue 中三个常见问题引发的深度思考
为什么 data 要写成函数,而不允许写成对象? Vue 中常说的数据劫持到底是什么? Vue 实例中数组改变 length 或下标直接赋值什么不能更新视图? http://www.sohu.com/ ...
- POJ 1741 Tree ——(树分治)
思路参考于:http://blog.csdn.net/yang_7_46/article/details/9966455,不再赘述. 复杂度:找树的重心然后分治复杂度为logn,每次对距离数组dep排 ...
- 使用io/ioutil进行读写文件
读文件: package main import ( "fmt" "io/ioutil" ) func main() { b, err := ioutil.Re ...
- VS2008 Qt Designer 中自定义信号槽
一.Qt Designer自定义槽函数 发现:在VS2008 +Qt4.7 中打开ui文件,所用的英文QT Designer工具,没有转到槽函数的功能,不如QtCreator自带的QtDesigne ...
- Python 寻找文件夹里以特定格式结尾的文件
代码: import os, re, time name = 'linuxday01' flags = True# 文件夹bi_test中的文件列表 print os.listdir('E:\\bi_ ...
- ubuntu19.04 安装workbench
1.首先下载安装这两个包: https://packages.ubuntu.com/cosmic/amd64/libssl1.0.0/download https://packages.ubuntu. ...