(长期更新)【python数据建模实战】零零散散问题及解决方案梳理
注1:本文旨在梳理汇总出我们在建模过程中遇到的零碎小问题及解决方案(即当作一份答疑文档),会不定期更新,不断完善, 也欢迎大家提问,我会填写进来。
注2:感谢阅读。为方便您查找想要问题的答案,可以就本页按快捷键Ctrl+F,搜索关键词查找,谢谢。
1. 读写csv文件时,存在新的一列,Unnamed:0?
答:read_csv()时,防止出现,设置参数index_col=0;写入csv文件时,防止出现,设置参数index=False。
2. 日期类型和其他类型互转。
场景1:我们从数据库取得的数据往往不是规整的,如存在‘19900807,1992-04-12’格式,且数据类型为str。
答:引入datetime模块。举例如下:
数据如图:
代码如下,即可解决:
data['app_date'] = data['app_date'].apply(lambda x: x.replace('-', '')) # 20190326,20181228
data['app_date'] = data['app_date'].apply(lambda x: datetime.datetime.strptime(x,'%Y%m%d')) # %Y%m%d or %Y-%m-%d的选择,取决于x格式带不带'-'
data['app_date'] = data['app_date'].apply(lambda x: x.strftime('%y%m')) # %y%m: 1903,1812...; %Y%m:201903, 201812...
场景2:将int型转为时间格式。pd.to_datetime()
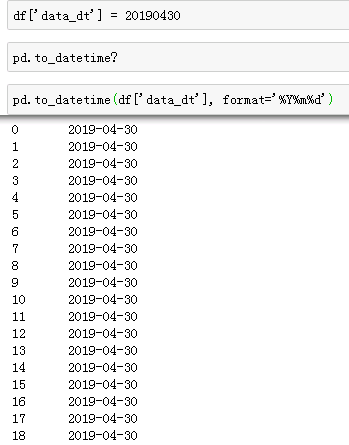
3. (简写)字符串格式化,两种方式
①%
for i in range(3):
s = '%d' %i
print(s) # 依次输出 1, 2, 3
②{}.format()
s = '等级考试'
y = '-' print ('{0:{1}^25}'.format(s, y)) # ----------等级考试-----------
4. 建模时,对于python删除变量的两种小思路
1) 针对dataframe格式的data
data.drop(col, aixs= 1, inplace = True)
#col为想要删除的变量名--列名,方法:DataFrame.drop(self, labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
2) 针对series格式的columns行索引
cols = data.columns cols = cols.drop(col) #有个方法:cols.drop(labels, errors='raise')
5. 我们在预处理及特征工程阶段会分析各变量属于什么类别,都有哪些呢?
我们接触到的统计学变量(variables)可以分为数值变量(Numerical Variables)和分类变量(Categorical Variables)。
数值变量又可以分为---离散型变量(discrete)、连续型变量(continuous)。
分类变量又可以分为---有序分类变量(ordinal)、无序分类变量(nominal)。
6. python读写文件时模式mode选择的异同(多用于open('xx')、to_csv('xx')等地方)
1). r模式
只读模式,该模式下打开的文件如果不存在,将会出错;并且打开后,只能读取,不能写入
2). r+模式
在上述特点上增加一条:可以向文件中写入。
3). w模式
该模式打开的文件如果已经存在,会先清空,如果没有,会新建一个文件,然后只能写入数据,不能读取
4). w+模式
在上述特点上增加一条:可以读取。
5). a模式
该模式打开的文件如果已经存在,不会清空,写入的内容追加到文件尾,但不能读取文件;文件不存在就会新建一个,然后写入。(以追加的方式写入)
6). a+模式
在上述特点上增加一条:可以读取数据。
7). 二进制模式,在上述后面加上b,如'rb',读取二进制文件。
7. 排序取最大(小)值对应的索引,argmin,idxmin,argmax,argmin
numpy分析: numpy 的 ndarray.argmin 的 Series 版
Series分析: argmin=idxmin,argmax=idxmax
DataFrame分析: 没有arg,只有idxmin,idxmax
8. 经常要用到映射方法,apply,applymap,map,定义如下
apply: 使用在DataFrame上,用于对row或者column进行计算;
applymap: 用于DataFrame上,是元素级操作(常用);
map: 用于series上,是元素级操作。
9. 删除特定列的重复行,drop_duplicates()
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
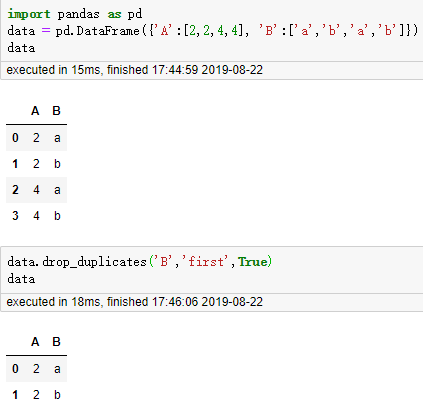
10. 记录一个map,str的join的示例
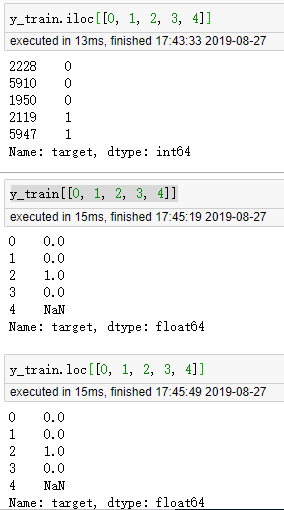
11. DataFrame/Series 索引问题。iloc,loc,直接索引[[]]
(y_train是个Series类型,且我没有reset_index)
12. 把python中的DataFrame中的object对象转换成我们需要的类型,convert
df.infer_objects
13. 去除字符串中指定字符
①python中的strip()可以去除头尾指定字符,基本用法:
ss.strip()参数为空时,默认去除ss字符串中头尾\r, \t, \n, 空格等字符
ss.lstrip()删除ss字符串开头处的指定字符,ss.rstrip()删除ss结尾处的指定字符
②想要去除中间字符,可以使用replace()函数
基本用法:replace(old, new[, max])
14. DataFrame中某些列值替换,如y值替换为0,1 (两种方法)
①-- np.where()

②-- pandas series map()

15. 关于DataFrame赋值注意事项(空表和有值表赋值的差异)

16.Python读取csv文件时编码报错问题
一,读取csv文件:
train= pd.read_csv(train_path)
1. 如果报错OSError: Initializing from file failed,可尝试的方法有:
train= pd.read_csv(open(train_path))
2. 如果是编码报错,如:UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 38: illegal multibyte sequence
可尝试:
train= pd.read_csv(train_path,encoding='gbk')
这里的encoding可以尝试其他的,如utf-8,gb2312,gb18030,ISO-8859-1,反正各种试,总有一个可以通过。
3. 如果上面这些都不行,还是编码报错,试试下面这方法,应该都会通过:
train= pd.read_csv(open(train_path,encoding='utf-8',errors='ignore'))
这里的encoding选什么就试了。
注:train_path 是你要读取的文件路径。
注:感谢阅读。如果书写风格影响观看体验,还望多多提出来,本人会虚心接受,谢谢
(长期更新)【python数据建模实战】零零散散问题及解决方案梳理的更多相关文章
- dython:Python数据建模宝藏库
尽管已经有了scikit-learn.statsmodels.seaborn等非常优秀的数据建模库,但实际数据分析过程中常用到的一些功能场景仍然需要编写数十行以上的代码才能实现. 而今天要给大家推荐的 ...
- Python数据可视化实战:实时更新海外疫情数据,实现数据可视化
前言 我国的疫情已经得到了科学的控制,开始了全面的复工复产,但是国外的疫情却“停不下来”.国外现在可谓就是处于水深火热当中啊,病毒极强的传染性,导致了许多的人都“中招”了,我国已经全面复工复产了,人大 ...
- 逻辑回归--美国挑战者号飞船事故_同盾分数与多头借贷Python建模实战
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- Python数学建模-02.数据导入
数据导入是所有数模编程的第一步,比你想象的更重要. 先要学会一种未必最佳,但是通用.安全.简单.好学的方法. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数据导入 ...
- python的多版本安装以及常见错误(长期更新)
(此文长期更新)Python安装常见错误汇总 注:本教程以python3.6为基准 既然是总结安装过程中遇到的错误,就顺便记录一下我的安装过程好了. 先来列举一下安装python3.6过程中可能需要的 ...
- Python数学建模-01.新手必读
Python 完全可以满足数学建模的需要. Python 是数学建模的最佳选择之一,而且在其它工作中也无所不能. 『Python 数学建模 @ Youcans』带你从数模小白成为国赛达人. 1. 数学 ...
- woe_iv原理和python代码建模
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- python异常值检验实战2_医美手术价格
python信用评分卡建模(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_ca ...
- Elasticsearch 数据建模指南
文章转载自:https://mp.weixin.qq.com/s/vSh6w3eL_oQvU1mxnxsArA 0.题记 我在做 Elasticsearch 相关咨询和培训过程中,发现大家普遍更关注实 ...
随机推荐
- CSS实现按钮YES-NO按钮+Jquery获取按钮状态。
前几天我经理突然跟我说,能不能做一个开关按钮,需要过滤的一个标识.说实话,一个做后端我是懵逼状态的. 不过网上资料很多,查了一遭,发现一个不错的哥们给出的案例,模仿一下成功实现,下面就自己总结一下: ...
- SimpleDateFormat线程不安全及解决办法(转)
以前没有注意到SimpleDateFormat线程不安全的问题,写时间工具类,一般写成静态的成员变量,不知,此种写法的危险性!在此讨论一下SimpleDateFormat线程不安全问题,以及解决方法. ...
- PHP大文件分片上传
前段时间做视频上传业务,通过网页上传视频到服务器. 视频大小 小则几十M,大则 1G+,以一般的HTTP请求发送数据的方式的话,会遇到的问题:1,文件过大,超出服务端的请求大小限制:2,请求时间过长, ...
- 【原创】tarjan算法初步(强连通子图缩点)
[原创]tarjan算法初步(强连通子图缩点) tarjan算法的思路不是一般的绕!!(不过既然是求强连通子图这样的回路也就可以稍微原谅了..) 但是研究tarjan之前总得知道强连通分量是什么吧.. ...
- 从斐波那契数列看java方法的调用过程
先看斐波那契数列的定义: 斐波那契数列(Fibonacci sequence),又称黄金分割数列.因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为 ...
- Python: 关于 sys.stdout.flush()
stackoverflow https://stackoverflow.com/questions/10019456/usage-of-sys-stdout-flush-method Python's ...
- Selenium定位class包含空格的元素-复合class节点
在HTML中, 节点有三种常见属性, 分别是id, name和class, 其中class是一个特殊的属性, 支持多个类名, 以空格隔开, 如下图所示: 你是否注意到, 为什么selenium中的fi ...
- 在django中解决跨域AJAX
由于浏览器存在同源策略机制,同源策略阻止从一个源加载的文档或脚本获取另一个源加载的文档的属性. 特别的:由于同源策略是浏览器的限制,所以请求的发送和响应是可以进行,只不过浏览器不接收罢了. 浏览器同源 ...
- 在iOS开发中使用icon font的方法
http://iconfont.cn/help/iconuse.html 在开发阿里数据iOS版客户端的时候,由于项目进度很紧,项目里的所有图标都是用最平常的背景图片方案来实现.而为了要兼容普通屏与R ...
- python 列表切片之负数的含义代码示例
a = list(range(10)) print(a[::]) #复制一个列表 print(a[::2]) #每隔2个取一次 print(a[::3]) #每隔3个取一次 print(a[::-1] ...