二、单层感知器和BP神经网络算法
一、单层感知器
1958年[仅仅60年前]美国心理学家FrankRosenblant剔除一种具有单层计算单元的神经网络,称为Perceptron,即感知器。感知器研究中首次提出了自组织、自学习的思想,而且对对所解决的问题存在着收敛算法,并能从数学上严格证明,因而对神经网络的研究齐了重要作用。
1.单层感知器模型
单层感知器是指只有一层处理单元的感知器,如果包括输入层在内,应为两层。如图所示:

a.输入层:$ X=(x_1, x_2, .., x_i, ..., x_n)^T$。
b.输出层:$ O=(o_1, o_2, ..., o_i, ..., o_n)^T$。
c.权值向量:$ W= (w_1, w_2, ..., w_i, ..., w_n)^T$。
由前面介绍的神经元模型可值看,对于处理节点$net_j$,其输入的值为,$ net'_j = \sum_{i=1}^{n}\omega_{ij}x_i $。
同时,如果取符号函数来处理离散变量,则该处理节点的输出值为$ o_j = sgn(net'_j - T_j) = sgn(\sum_{i=0}^{n}) = sgn(W_j^T X) $。
现在探讨一下单计算接单感知器的功能。假设符号函数为双极性阈值转移函数,即:
\[ \begin{equation}o_j=sgn(W_j^T X) \left \{\begin{aligned} 1, W_j^T X \ge0 \\ -1, W_j^T X \le0 \\ \end{aligned}\right.\end{equation} \]
假设输入向量是$\textbf{X}=(x_1, x_2)^T$,显然它表示空间里一个点。如果用符号函数处理节点并作为输出,那么类似X的多个样本输入,其结果只有[0,1]两种情况。
\[ \begin{equation}o_j=sgn(W_j^T\textbf{X}) \left \{ \begin{aligned}1, w_{1j}x_1+w_{2j}x_2-T_j \ge0 \\ -1, w_{1j}x_1+w_{2j}x_2 - T \le 0 \\ \end{aligned} \right. \end{equation} \]
于是方程$w_{1j}x_1 + w_{2j}x_2 - T = 0$称为所有输入变量的一条分割线。$T_j$可视为常量b。
它的物理意义在于,寻找一条分界线去分割二位平面上的点。
同样地,如果输入向量们是$\textbf{X}=(x_1, x_2, x_3)^T$,该公式可写为$w_{1j}x_1 + w_{2j}x_2 + w_{3j}x_3 - T_j = 0$。它的物理意义在于,寻找一个分界面去分割三维空间里的点。
由此推理,设输入向量X的维度为n,$\textbf{X} = (w_1, w_2, ..., w_n)^T$,它在几何上构成一个n维空间。我们总是可以定义一个n维空间上的超平面:
\[ w_{1j}x_1 + w_{2j}x_2 + ... + w_{nj}x_n - T_j = 0 \]
去尝试把输入向量分为两类。超平面的“超”,指的就是$T_j$。它的值可看作是其它维度上的一种映射或表征,用以作为分类的依据。
许多学者已经证明,如果输入样本线性可分,无论感知器的初始权向量如何取值,经过有限次调整后,总能够稳定到一个权向量,该权向量确定的超平面能将两类样本正确分开。
2.感知器的功能作用:
a.在输出层,配合符号函数或概率函数求argmax(非连续型激活函数),可以做分类器。双隐层感知器足以解决任何复杂的分类问题。该结论已经经过严格的数学证明。
b.在输出层,配合双极性阈值转移函数(sigmod)等(连续型激活函数),可以做线性回归。
c.在隐层,双极性阈值转移函数(sigmod)等(连续型激活函数),一般一般作为全连接层。
小练习:某单计算节点感知器有3个输入。给定3对训练样本如下:
\[ \textbf{X}^1 = (-1, 1, -2, 0)^T ,d^1 = -1 ; \textbf{X}^2 = (-1, 0, 1.5, -0.5)^T, d^2 = -1 ; \textbf{X}^3 = (-1, -1, 1, 0.5)^T, d^3 = 1 \]
设初始权向量$\textbf{W}(0) = (0.5, 1, -1, 0)^T, \eta = 0.1$。试根据以上学习规则训练感知器。
import numpy as np
x1 = np.array([[-1], [1], [-2], [0]])
d1 = -1 x2 = np.array([[-1], [0], [1.5], [-0.5]])
d2 = -1 x3 = np.array([[-1], [-1], [1], [0.5]])
d3 = 1 w0 = np.array([[0.5], [1], [-1], [0]]) learning_rate = 0.1 def sgn(x):
return -1 if x<0 else 1 w0_x1 = np.dot(w0.T, x1)
o1 = sgn(w0_x1)
w1 = w0 + learning_rate * (d1 - o1) * x1 w1_x2 = np.dot(w1.T, x2)
o2 = sgn(w1_x2)
w2 = w1 + learning_rate * (d2 - o2) * x2 w2_x3 = np.dot(w2.T, x3)
o3 = sgn(w2_x3)
w3 = w2 + learning_rate * (d3 - o3) * x3 print(w1, end="\n\n")
print(w2, end="\n\n")
print(w3)
练习
3.感知器的局限性:
(1)感知器不能解决异或问题。感知器能够把不属于同一类别的样本分为不同的类别(就是所谓的“异”),也能把属于同一类别的样本分到相同的类里(就是所谓的“或”)。但是感知器无法区分“你中有我,我中有你”的样本(就是异或问题)。说白了,单层感知器无法应对线性不可分的问题。
其对应的解决办法是,多添加一层或几层感知器。
假如输入向量是二维平面上的点,我们再加入一层隐藏层。此时,隐藏层中的每一个神经元节点都确立了二维平面上的一条分界直线。多条直线经输出节点组合后会形成各种形状的凸域。(所谓凸域是指其边界上任意两点之间的连线均在域内)。通过训练调整凸域的形状,可将两类线性不可分样本分为域内和域外。输出层节点负责将域内外的两类样本进行分类。
当单隐层感知器具有多个节点时,节点数量增加可以使多边形凸域的边数增加,从而在输入空间构建出任意形状的凸域。如果在此基础上再增加一层,称为第二个隐层,则该层的每个节点确定一个凸域。[再加一层隐藏层表示什么几何意义?]
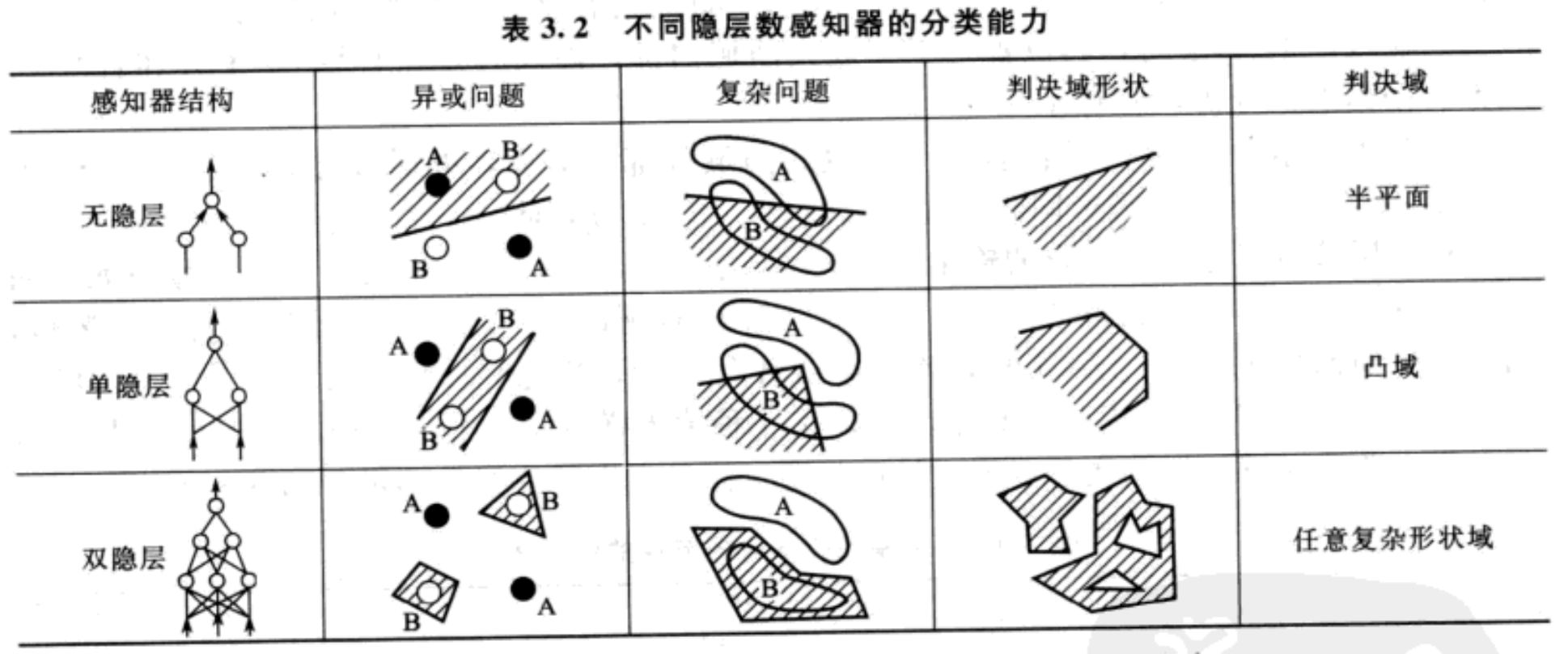
(2)感知器无法解决权值调整问题。感知器属于有监督学习,即需要给出期望值。在单层感知器中,有给出期望值,可以根据期望值和实际输出之差来调整权值。但是在多层感知器中,隐层的期望值是不知道的,从而无法计算权值,也就是该学习规则对隐层权值不适用。另外,感知器仅是前馈神经网络。
(3)感知器无法解决“最优”决策。这个是由它的权值调整缺陷造成的。因为它的输出控制不是基于误差的,所以不能找到最优的分类方法。
于是应运而生了BP神经网络算法。人们也常把多层感知器直接称为BP神经网络。
4.单层感知器算法练习
下面给出的训练集由玩具兔和玩具熊组成,输入样本向量的第一个分量代表玩具的重量,第二个分量代表玩具耳朵的长度,教师信号为-1表示玩具兔,教师信号为1表示玩具熊。试构建一个感知器来完成此训练并对感知器进行验证。
X_1=(1,4), d=-1; X_2=(1,5), d=-1; X_3=(2,4), d=-1; X_4=(2,5), d=-1; X_5=(3,1), d=1; X_6=(3, 2), d=1; X_7=(4, 1), d=1; X_8=(4, 2), d=1;
1.预分析:显然这两类样本能够只用一条线去划分,于是可以用单层感知器建立模型[即一个输入层,一个输出层,输出层只有一个神经元]。
2.开始撸一串代码。
import numpy as np
import pandas as pd # 定义双极性阈值函数
def sgn(x):
return 1 if x>0 else -1 # 定义误差计算方式
def errors(d, o):
return (1/2) *(d - o) ** 2 # 定义输入和格式
def dataHandle():
"""根据题设,把训练样本的数据转换成一般的数据处理格式"""
x1 = [1, 4]
x2 = [1, 5]
x3 = [2, 4]
x4 = [2, 5]
dx = -1
y1 = [3, 1]
y2 = [3, 2]
y3 = [4, 1]
y4 = [4, 2]
dy = 1 # 合并数据并添加教师信号到末尾
X = [x.append(dx) for x in [x1, x2, x3, x4]]
Y = [y.append(dy) for y in [y1, y2, y3, y4]]
# 转换成数组形式
X = np.array([x1,x2,x3,x4])
Y = np.array([y1,y2,y3,y4]) # 把x,y的样本合并到一起,并打乱顺序
XY = np.row_stack((X,Y))
np.random.shuffle(XY)
# 给数组添加一列作为biase(常量值)
samples = np.insert(XY, 0, values=1, axis=1)
# samples = XY
# 再把教师信号和对应的样本分开保存
labels = samples[:,-1]
train_data = samples[:, :-1]
return {"samples": samples, "labels": labels, "train_data": train_data} # 定义训练数据
def train(train_data, labels, learning_rate, n_steps, f):
"""
train_data:训练样本
labels:样本对应的教师信号向量
learning_rate:学习信号
f: 激活函数
deltaW:学习规则[这里也可以写激活函数]
"""
record = []
# 初始化权值向量
w = np.random.rand(1, 3)
n = 0
while n <= n_steps:
error = 0 # 定义每次训练的误差
count = 0 # 统计训练正确的样本 # 由于这里的点只分成了两类,所以一个输入层,一个输出层,输出层一个单层感知器即可
for index, _ in enumerate(train_data):
"""----------------训练模型---------------"""
net = np.dot(w, train_data[index].T)[0] # 权值向量和输入向量的点积,作为输出层的输入数据
o = f(net) # 经输出层的激活函数处理,o即为输出层的输出
# 权值调整策略
w = w + learning_rate * (labels[index] - f(o)) * train_data[index] # 更新权值向量
"""----------------训练信息统计---------------"""
# 计算此次的误差
error = error + errors(labels[index], o)
# 简单计算当前样本是否正确被分类
if labels[index] - o == 0:
count = count + 1
# 计算准确率
accuracy = count / len(train_data)
# 把error和arruracy保存下来
record.append([n, error, accuracy, w]) n += 1
return pd.DataFrame(record, columns=["训练次数", "误差", "准确率", "权值"]) if __name__ == "__main__":
data = dataHandle()
outcome = train(train_data=data["train_data"], labels=data["labels"], learning_rate=0.01, n_steps=4, f=sgn)
3.验证。结果为True。
list(data["labels"]) == [sgn(x) for x in list(np.dot(data["train_data"], outcome.iloc[-1, -1].T))]
2.BP神经网络
1.BP神经网络核心思想
1986年,Rumelhart和McCelland领导的科学家小组在<<Parallel Distributed Processing>>一书中详细分析了误差反向传播算法(error back proragation,简称BP),实现了Minsky关于多层网络的设想。
BP算法的基本思想是:学习过程由信号的正向传播与误差的反向传播两个过程组成(和js中的冒泡事件过程相似)。正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。误差反传是将输出误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
这种信号正向传播与误差反向传播的各层权值调整过程是周而复始地进行。权值不断调整的过程,也就是网络的学习训练过程。此过程一直进行到网络输出的误差减少到可接受的程度,或进行到预先设定的学习次数为止。
BP算法的多层感知器是至今为止应用最广泛的神经网络。
2.以三层感知器为例,包括输入层、隐层、输出层。
假设在三层感知器中,
输入向量为$ \textbf{X} = (x_1, x_2, ..., x_i, ..., c_n)^T $,$ x_0 = -1 $ 是为隐藏层神经元引入阈值而设置的;
隐藏层输出向量为$\textbf{Y} = (y_1, y_2, ..., y_j, ..., y_n)^T$,$y_0 = -1$是为输出层神经元引入阈值而设置的;输出层输出向量为$\textbf{O} = (o_1, o_2, ..., o_k, ..., o_l)^T$;
期望输出为$d = (d_1, d_2, ..., d_k, ..., d_l)^T$。
输入层到隐层之间的权值矩阵用$\textbf{V}$表示,$\textbf{V} = (\textbf{V}_1, \textbf{V}_2, ..., \textbf{V}_j, ..., \textbf{V}_m)$,
其中列向量$\textbf{V}_j$为隐层第j个神经元对应的权向量;
隐层到输出层之间的权值矩阵用$\textbf{W}$表示,$\textbf{W} = (\textbf{W}_1, \textbf{W}_2, ..., \textbf{W}_k, ..., \textbf{W}_i)$,其中列向量$\textbf{W}_k$为输出层第k个神经元对应的权向量。
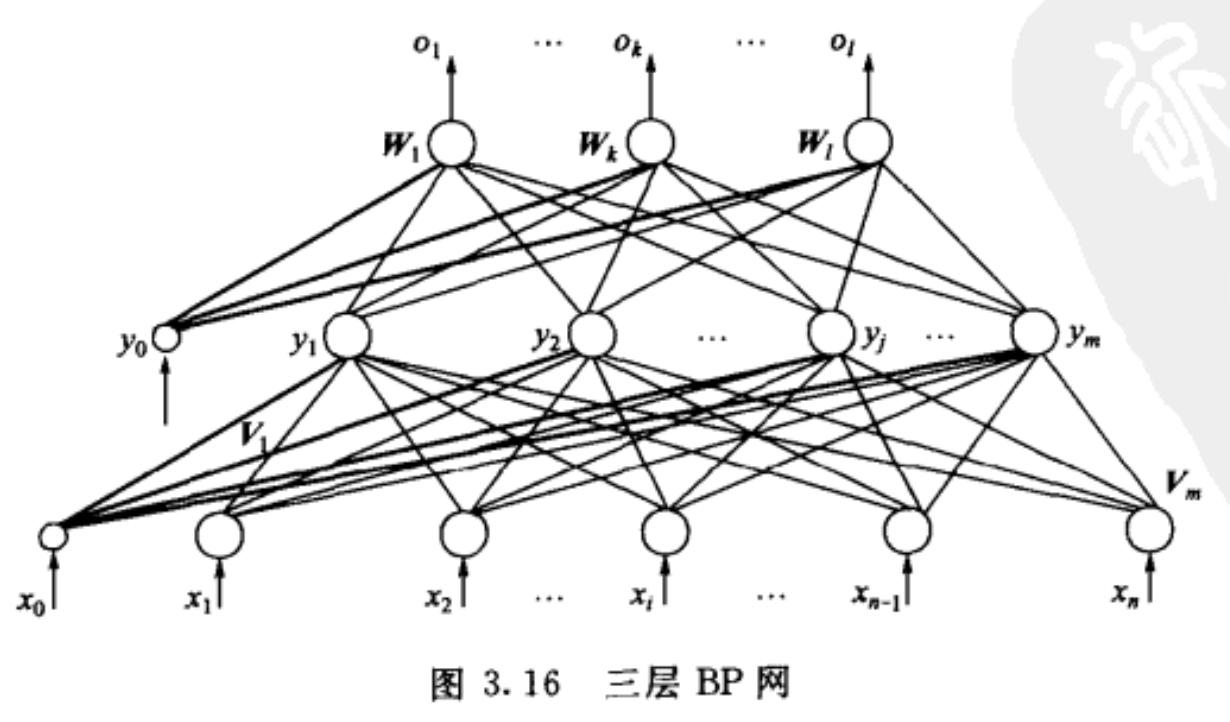
下面分析各层信号之间的数学关系:
对于输出层有:
\[ o_k = f(net_k) , k=1,2,...,l \],
\[ net_k = \sum_{j=0}^{m}w_{jk}y_j , k=1,2,...,l \]
对于输入层有:
\[ y_j = f(net_j) , j=1,2,...,m \],
\[ net_j = \sum_{i=0}^{n}v_{ij}x_i ,j=1,2,...,m \]
以上两式中,转移函数f(x)均为单极性Sigmiod函数$f(x) = \frac{1}{1 + e^{-x}}$,且有:$f'(x) = f(x)[1 - f(x)]$,当然根据应用需要也可以采用双极性Sigmod函数(双曲线正切函数)$f(x) = \frac{1 - e^{-x}}{1 + e^{-x}}$。
上式构成了三层感知器的数学模型。
3.BP学习算法模型构建
当网络输出与期望输出不等时,存在输出误差$\textbf{E}$,定义如下:[$还对\delta学习规则有印象吗?$]
\[ \textbf{E} = \frac{1}{2} (\textbf{d} - \textbf{O})^2 = \frac{1}{2} \sum_{k=1}^{l}(d_k - o_k)^2 \]
这个误差的定义就很常见了,跟方差的定义只错了$\frac{1}{2}$这个常数。
将以上误差定义式展开至隐层:
\[ \textbf{E} = \frac{1}{2} \sum_{k=1}^{1} [d_k - f(net_k)]^2 = \frac{1}{2} \sum_{k=1}^{l} [d_k - f(\sum_{j=0}^{m} w_{jk}y_j)] , ----a1\]
进一步展开至输入层,有:
\[ \textbf{E} = \frac{1}{2} \sum_{k=1}^{l} \{ d_k - f[\sum_{j=0}^{m}w_{jk}f(net_j)] \}^2 \]
\[ \textbf{E} = \frac{1}{2} \sum_{k=1}^{l} \{ d_k - f[\sum_{j=0}^{m} w_{jk} f(\sum_{i=0}^{n} v_{ij}x_i)] \}^2, ----b1\]
由上式可知,网络误差是各层权值$w_{jk}、v_{ij}$的函数,因此调整权值可改变误差$\textbf{E}$。显然,调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即:
\[ \Delta w_{jk} = - \eta \frac{\partial \textbf{E}}{ \partial w_{jk}}, j=0,1,2,...,m; k=1,2,...,l \]
\[ \Delta v_{jk} = - \eta \frac{\partial \textbf{E}}{ \partial v_{ij}}, i=0,1,2,...,n; j=1,2,...,m \]
符号表示梯度下降,常数$\eta \in (0, 1)$表示比例系数,在训练中反应了学习速率。可以看出,BP算法属于$\delta$学习规则类。这类算法被称为误差的梯度下降算法(gradient descent)算法。这里只是写了一下思路,$\partial w_{jk} 是 \partial net_k 中的一个$,$\partial v_{ij} 是 \partial net_j $
4.BP算法推导:
下面正式对三层BP算法权值调整计算公式进行推导。这里的求导的参数是权值。
(1)对于输出层,上a式可写为:
\[ \Delta w_{jk} = - \eta \frac{\partial \textbf{E}}{ \partial w_{jk}} = - \eta \frac{\partial \textbf{E}}{\partial net_k} * \frac{\partial net_k}{\partial w_{jk}} = -\frac{\partial \textbf{E}}{\partial net_k} f'(net_k) ,这里的f'(net_k)是个双极性阈值函数 ----a2 \]
a.对于输出层的单个神经元k,有$f'(net_k) = f(net_k)[1 - f(net_k)]$。根据a1式和a2式,尝试对输出层(也就是$\textbf{W}_1, ..., \textbf{W}_k, \textbf{W}_l$)的每个神经元进行求导(也就是对输出层的输入权值进行求导):
\[ [\frac{1}{2} (d_k - f(net_k))^2]' = -(d_k - f(net_k)) * f'(net_k) = -(d_k - f(net_k)) * f(net_k)(1 - f(net_k)) ----a3\]
b.那么根据$\delta$学习规则,构建输出层的权值调整策略[把上式结果定义为$\delta_k$,此式用于简写隐层b3式推导中的部分内容]:
\[ \Delta W_{jk} = -\eta * [- (d_k - f(net_k)) * f(net_k)(1 - f(net_k))] * y_j ----a4\]
c.$W_{jk}$表示第k个神经元的第j个权值调整,这里没写成向量式,需要遍历。
d.这里的总误差分摊到了每个输出层神经元身上,每个输出层的神经元又根据$f(net_k)$再分摊到上一层(隐层)的每个权值上。因此在这里需要做两层循环。
(2)对于隐层,上b式可写为:
\[ \Delta v_{jk} = - \eta \frac{\partial \textbf{E}}{ \partial v_{ij}} = - \eta \frac{\partial \textbf{E}}{\partial net_j} * \frac{\partial net_j}{\partial v_{jk}} ----b2\]
a.对于隐层的单个神经元,有$f'(net_j) = f(net_j)[1 - f(net_j)]$,现在开始尝试捋一捋从输入层i到输出层j的权值调整$V_{ij}$,根据a1式和a2式,来对权值$v_{ij}$进行求导:
\[ \Delta V_{ij} = ([d_k - f(\sum_{j=0}^{m}w_{jk}f(net_j))]^2)' = - [d_k - f(net_k)] * f'(\sum_{j=0}^{m}w_{jk}f(net_j)) ----b3\]
\[ = -[d_k - f(net_k) * f(net_k) * (1 - f(net_k))] * (\sum_{j=0}^{m} w_{jk}f(net_j))' \]
\[ = - \delta_k * \lgroup \sum_{j=0}^{m} w_{jk} \rgroup * f'(net_j) \]
\[ = - \lgroup \sum_{j=0}^{m} w_{jk} \delta_k \rgroup [f(net_j)(1 - f(net_j))] \]
\[ = - \lgroup \sum_{j=0}^{m} w_{jk} \delta_k \rgroup y_j (1 - y_j) \]
b.那么相应的学习规则是:
\[ \Delta v_{ij} = \eta \lgroup \sum_{j=0}^{m} w_{jk} \delta_k \rgroup y_j (1 - y_j) * x_i \]
c.看到$x_i$,显然要进行三次循环计算了
5.BP算法总结[...]:
对于一般的多层感知器
设有h个隐层,按向前顺序,各隐层神经元节点数为$m_1, m_2, ..., m_n$,
各隐层的输出为分别为$y^1, y^2, ..., y^h$,
各层权值矩阵为$\textbf{W}_1, \textbf{W}_2, ..., \textbf{W}_h$,
则各层的权值计算公式为:
输出层:$\Delta w_{jk}^{h+1} = \eta \Delta_{k}^{h+1} y_{j}^{h} = \eta (d_k - o_k) o_k (1 - o_k) y_{j}^{h}, j=0,1, ..., m_h; k=1,2, ..., l$
$m_h$表示第h个隐层的节点个数,l表示输出层到最后实际值的分类个数
第h隐层:$\Delta w_{ij}^{h} = \eta \Delta_{j}^{h} y_{i}^{h-1} = \eta \lgroup \sum_{k=1}^{l} \Delta_k w_{jk}^{h+1} \rgroup y_{j}^{h} (1 - y_{j}^{h}) y_{j}^{h-1}$,
$i=0,1,2, ..., m_{h-1}; j=1,2, ..., m_h$
按以上规律类推,第一层的权值调整计算公式为:$\Delta w_{pq}^1=\eta \Delta_q^1 x_p=\eta \lgroup \sum_{r=1}^{m_2} \Delta_r w_{qr}^2 \rgroup y_q^1 (1 - y_q^1) x_p$
$p=0,1,2, ..., n; j=1,2, ..., m_1$
6.BP算法误差调整方式
二、单层感知器和BP神经网络算法的更多相关文章
- bp神经网络算法
对于BP神经网络算法,由于之前一直没有应用到项目中,今日偶然之时 进行了学习, 这个算法的基本思路是这样的:不断地迭代优化网络权值,使得输入与输出之间的映射关系与所期望的映射关系一致,利用梯度下降的方 ...
- BP神经网络算法预测销量高低
理论以前写过:https://www.cnblogs.com/fangxiaoqi/p/11306545.html,这里根据天气.是否周末.有无促销的情况,来预测销量情况. function [ ma ...
- BP神经网络算法推导及代码实现笔记zz
一. 前言: 作为AI入门小白,参考了一些文章,想记点笔记加深印象,发出来是给有需求的童鞋学习共勉,大神轻拍! [毒鸡汤]:算法这东西,读完之后的状态多半是 --> “我是谁,我在哪?” 没事的 ...
- 数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了.神经网络有很多种:前向传输网络.反向传输网络.递归神经网络.卷积神经网络等.本文介绍基本的反向传输神经网络(Backpropaga ...
- JAVA实现BP神经网络算法
工作中需要预测一个过程的时间,就想到了使用BP神经网络来进行预测. 简介 BP神经网络(Back Propagation Neural Network)是一种基于BP算法的人工神经网络,其使用BP算法 ...
- BP神经网络算法学习
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是眼下应用最广泛的神经网络模型之中的一个 ...
- R_Studio(神经网络)BP神经网络算法预测销量的高低
BP神经网络 百度百科:传送门 BP(back propagation)神经网络:一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络 #设置文件工作区间 setwd('D:\\ ...
- MATLAB——单层感知器
1.创建一个感知器 实例 % example4_1.m p=[-,;-,] % 输入向量有两个分量,两个分量取值范围均为-~ % p = % % - % - t=; % 共有1个输出节点 net=ne ...
- matlab练习程序(单层感知器)
clear all; close all; clc; %生成两组已标记数据 randn(); mu1=[ ]; S1=[ ; ; 0.4]; P1=mvnrnd(mu1,S1,); mu2=[ ]; ...
随机推荐
- Xamarin Android Webview中JS调用App中的C#方法
参考链接:https://github.com/xamarin/recipes/tree/master/Recipes/android/controls/webview/call_csharp_fro ...
- [ActionScript 3.0] 框选裁剪
package { import flash.display.Bitmap; import flash.display.BitmapData; import flash.display.Loader; ...
- [ActionScript 3.0] 常用的正则表达式
as 3.0常用的正则表达式: /* * 去除字符串前面的空格和跳格符 */ var src:String=" Hello! "; trace(src); //原文本 trace( ...
- UIView中的tintColor和renderingMode
tintColor 每一个view都有一个tintcolor,类似于魔法色,实现类似于换肤的效果. 每一个view的subview都集成view的tintcolor,当然subview可以指定自己的t ...
- 如何保证一个textfield输入最长的文字
NSString *lang = [self.inputTextField.textInputMode primaryLanguage]; // 键盘输入模式 if ([lang isEqualToS ...
- 闭包(Closure)和匿名函数(Anonymous function)/lambda表达式的区别
闭包(Closure)和匿名函数(Anonymous function)/lambda表达式的区别 函数最常见的形式是具名函数(named function): function foo(){ con ...
- document.documentElement和document.body区别介绍
document.documentElement和document.body区别介绍 * 区别 body是DOM对象黎明的body子节点,即标签 docummentElement 是整个树的根节点ro ...
- Ubuntu16.04安装视觉SLAM环境(ceres-solver)
1.先在github上下载ceres-solver git clone https://github.com/ceres-solver/ceres-solver.git 2.安装ceres-solve ...
- CF1067D. Computer Game(斜率优化+倍增+矩阵乘法)
题目链接 https://codeforces.com/contest/1067/problem/D 题解 首先,如果我们获得了一次升级机会,我们一定希望升级 \(b_i \times p_i\) 最 ...
- POJ_1990 MooFest 【树状数组】
一.题面 POJ1990 二.分析 一个简单的树状数组运用.首先要把样例分析清楚,凑出57,理解一下.然后可以发现,如果每次取最大的v就可以肆无忌惮的直接去乘以坐标差值就可以了,写代码的时候是反着来的 ...