雪花算法-Java分布式系统自增id
1、雪花算法的用途
分布式系统中ID生成方案,比较简单的是UUID(Universally Unique Identifier,通用唯一识别码),但是其存在两个明显的弊端:
一、UUID是128位的,长度过长;
二、UUID是完全随机的,无法生成递增有序的UUID。
而现在流行的基于 Snowflake 雪花算法的ID生成方案就可以很好的解决了UUID存在的这两个问题
2、算法原理
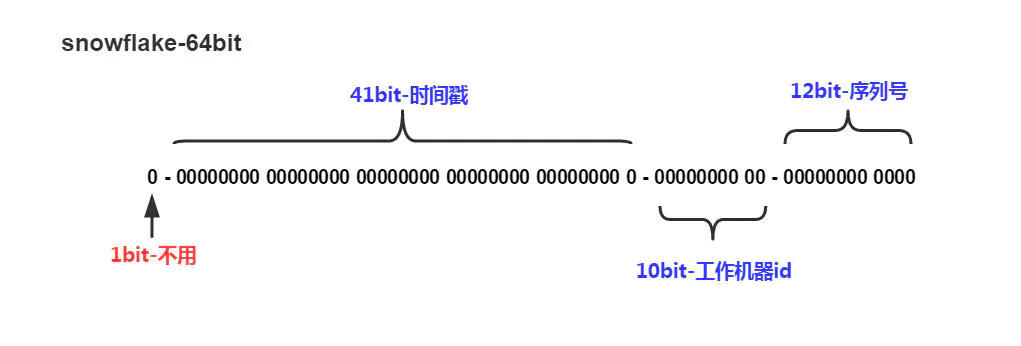
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
41bit-时间戳,用来记录时间戳,毫秒级。
- 41位可以表示个数字,
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至
- 也就是说41位可以表示年
10bit-工作机器id,用来记录工作机器id。
- 可以部署在个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
12bit-序列号,序列号,用来记录同毫秒内产生的不同id。
- 12位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
3、Java 实现雪花算法
public class IdWorker{
//下面两个每个5位,加起来就是10位的工作机器id
private long workerId; //工作id
private long datacenterId; //数据id
//12位的序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作id需要左移的位数,12位
private long workerIdShift = sequenceBits;
//数据id需要左移位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳,初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId(){
return datacenterId;
}
public long getTimestamp(){
return System.currentTimeMillis();
}
//下一个ID生成算法
public synchronized long nextId() {
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
//获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//将上次时间戳值刷新
lastTimestamp = timestamp;
/**
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取系统时间戳
private long timeGen(){
return System.currentTimeMillis();
}
//---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1,1,1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
雪花算法-Java分布式系统自增id的更多相关文章
- 开源一个比雪花算法更好用的ID生成算法(雪花漂移)
比雪花算法更好用的ID生成算法(单机或分布式唯一ID) 转载及版权声明 本人从未在博客园之外的网站,发表过本算法长文,其它网站所现文章,均属他人拷贝之作. 所有拷贝之作,均须保留项目开源链接,否则禁止 ...
- 使用雪花算法为分布式下全局ID、订单号等简单解决方案考虑到时钟回拨
1.snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同 ...
- 雪花算法 Java 版
雪花算法根据时间戳生成有序的 64 bit 的 Long 类型的唯一 ID 各 bit 含义: 1 bit: 符号位,0 是正数 1 是负数, ID 为正数,所以恒取 0 41 bit: 时间差,我们 ...
- SnowflakeId雪花ID算法,分布式自增ID应用
概述 snowflake是Twitter开源的分布式ID生成算法,结果是一个Long型的ID.其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器I ...
- 雪花算法,生成分布式唯一ID
2.3 基于算法实现 [转载] 这里介绍下Twitter的Snowflake算法——snowflake,它把时间戳,工作机器id,序列号组合在一起,以保证在分布式系统中唯一性和自增性. snowfla ...
- 全局唯一Id:雪花算法
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 雪花算法生成分布式ID
分布式主键ID生成方案 分布式主键ID的生成方案有以下几种: 数据库自增主键 缺点: 导入旧数据时,可能会ID重复,导致导入失败 分布式架构,多个Mysql实例可能会导致ID重复 UUID 缺点: 占 ...
- 雪花算法-snowflake
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 分布式系统为什么不用自增id,要用雪花算法生成id???
1.为什么数据库id自增和uuid不适合分布式id id自增:当数据量庞大时,在数据库分库分表后,数据库自增id不能满足唯一id来标识数据:因为每个表都按自己节奏自增,会造成id冲突,无法满足需求. ...
- 【Java】分布式自增ID算法---雪花算法 (snowflake,Java版)
一般情况,实现全局唯一ID,有三种方案,分别是通过中间件方式.UUID.雪花算法. 方案一,通过中间件方式,可以是把数据库或者redis缓存作为媒介,从中间件获取ID.这种呢,优点是可以体现全局的递增 ...
随机推荐
- 5步带你入门GaussDB(DWS)的GDS导入导出
摘要:本篇文档为使用GDS导入示例的具体简单步骤和示例. 本文分享自华为云社区<带你快速入门GDS导入导出,玩转PB级数仓GaussDB(DWS)>,作者: yd_220527686. 1 ...
- UBUNTU安装代码阅读器Understand
https://blog.csdn.net/weixin_40641902/article/details/79607225 1.直接下载 Understand-3.1.670-Linux-64bit ...
- 为Jekyll静态网站添加PlantUML插件
前言 突然想起来要好好整理一下自己的博客空间,已经荒废很多年,如果再不捡起来,等到自己知识老化的时候再去写东西就没人看了. 使用Github Pages + Jekyll把博客发布为静态网站,给人感觉 ...
- quasar使用electron打包
quasar使用electron打包 从构建好的项目中,我们不难发现,electron打包有两种方式: electron-packager打包 这篇博客是通过我尝试了很多种方法之后,最先开始,我使 ...
- JZOJ 2020.07.16【NOIP提高组】模拟
总结 这套题相比昨天,简单了不止一点 然而有的人拿了 \(300\) 多 而我只有 \(198\) 预估应该有 \(268\) 的,假了 \(70\) 分 出现了很多奇怪的 \(mistakes\) ...
- PHP的25种框架
本篇文章给大家分享的内容是25种PHP框架 -有着一定的参考价值,有需要的朋友可以参考一下. 世界流行框架汇总 在项目开发中,一些架构和代码都是重复的,为了避免重复劳动,于是各种各样的框架诞生了. 在 ...
- PostgreSQL事务隔离级别
一.概念 并发控制是多个事务在并发运行时,数据库保证事务一致性(Consistency)和隔离性(Isolation)的一种机制.PostgreSQL使用了多版本并发控制技术的一种变体:快照隔离San ...
- oracle快速将表缓存到内存
共有2种方法: 1) alter table fisher cache; 2) alter table fisher storage(buffer_pool keep); --取消缓存 1) alte ...
- LeetCode-429 N叉树的层次遍历
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/n-ary-tree-level-order-traversal著作权归领扣网络所有.商业转载请联 ...
- LeetCode-1034 边界着色
题目来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/coloring-a-border/ 题目描述 给你一个大小为 m x n 的整数矩阵 gri ...