雪花算法-Java分布式系统自增id
1、雪花算法的用途
分布式系统中ID生成方案,比较简单的是UUID(Universally Unique Identifier,通用唯一识别码),但是其存在两个明显的弊端:
一、UUID是128位的,长度过长;
二、UUID是完全随机的,无法生成递增有序的UUID。
而现在流行的基于 Snowflake 雪花算法的ID生成方案就可以很好的解决了UUID存在的这两个问题
2、算法原理
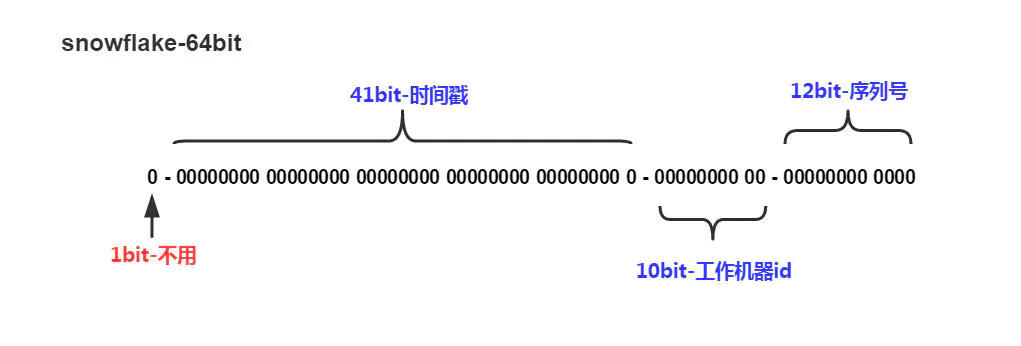
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
41bit-时间戳,用来记录时间戳,毫秒级。
- 41位可以表示个数字,
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至
- 也就是说41位可以表示年
10bit-工作机器id,用来记录工作机器id。
- 可以部署在个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
12bit-序列号,序列号,用来记录同毫秒内产生的不同id。
- 12位(bit)可以表示的最大正整数是,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
3、Java 实现雪花算法
public class IdWorker{
//下面两个每个5位,加起来就是10位的工作机器id
private long workerId; //工作id
private long datacenterId; //数据id
//12位的序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作id需要左移的位数,12位
private long workerIdShift = sequenceBits;
//数据id需要左移位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳,初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId(){
return datacenterId;
}
public long getTimestamp(){
return System.currentTimeMillis();
}
//下一个ID生成算法
public synchronized long nextId() {
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
//获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//将上次时间戳值刷新
lastTimestamp = timestamp;
/**
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取系统时间戳
private long timeGen(){
return System.currentTimeMillis();
}
//---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1,1,1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
雪花算法-Java分布式系统自增id的更多相关文章
- 开源一个比雪花算法更好用的ID生成算法(雪花漂移)
比雪花算法更好用的ID生成算法(单机或分布式唯一ID) 转载及版权声明 本人从未在博客园之外的网站,发表过本算法长文,其它网站所现文章,均属他人拷贝之作. 所有拷贝之作,均须保留项目开源链接,否则禁止 ...
- 使用雪花算法为分布式下全局ID、订单号等简单解决方案考虑到时钟回拨
1.snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同 ...
- 雪花算法 Java 版
雪花算法根据时间戳生成有序的 64 bit 的 Long 类型的唯一 ID 各 bit 含义: 1 bit: 符号位,0 是正数 1 是负数, ID 为正数,所以恒取 0 41 bit: 时间差,我们 ...
- SnowflakeId雪花ID算法,分布式自增ID应用
概述 snowflake是Twitter开源的分布式ID生成算法,结果是一个Long型的ID.其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器I ...
- 雪花算法,生成分布式唯一ID
2.3 基于算法实现 [转载] 这里介绍下Twitter的Snowflake算法——snowflake,它把时间戳,工作机器id,序列号组合在一起,以保证在分布式系统中唯一性和自增性. snowfla ...
- 全局唯一Id:雪花算法
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 雪花算法生成分布式ID
分布式主键ID生成方案 分布式主键ID的生成方案有以下几种: 数据库自增主键 缺点: 导入旧数据时,可能会ID重复,导致导入失败 分布式架构,多个Mysql实例可能会导致ID重复 UUID 缺点: 占 ...
- 雪花算法-snowflake
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- 分布式系统为什么不用自增id,要用雪花算法生成id???
1.为什么数据库id自增和uuid不适合分布式id id自增:当数据量庞大时,在数据库分库分表后,数据库自增id不能满足唯一id来标识数据:因为每个表都按自己节奏自增,会造成id冲突,无法满足需求. ...
- 【Java】分布式自增ID算法---雪花算法 (snowflake,Java版)
一般情况,实现全局唯一ID,有三种方案,分别是通过中间件方式.UUID.雪花算法. 方案一,通过中间件方式,可以是把数据库或者redis缓存作为媒介,从中间件获取ID.这种呢,优点是可以体现全局的递增 ...
随机推荐
- drf-jwt源码分析以及自定义token签发认证、alc和rbac
1.drf-jwt源码执行流程 1.1 签发(登录) 1.代码: urls.py: from rest_framework_jwt.views import obtain_jwt_token urlp ...
- 影片自由,丝滑流畅,Docker容器基于WebDav协议通过Alist挂载(百度网盘/阿里云盘)Python3.10接入
使用过NAS(Network Attached Storage)的朋友都知道,它可以通过局域网将本地硬盘转换为局域网内的"网盘",简单理解就是搭建自己的"私有云" ...
- MRS+LakeFormation:打造一站式湖仓,释放数据价值
摘要:华为LakeFormation是企业级的一站式湖仓构建服务. 本文分享自华为云社区<华为云MRS支持LakeFormation能力,打造一站式湖仓,释放数据价值]>,作者:break ...
- vue+element 返回数组或json数据自定义某列显示的处理--两种方法
本文是作者开发一个业务需求时,将返回数据列表的其中一个数据长度很长的字段处理成数组,并将其作为子表显示的过程,具体样式如下(数据做了马赛克处理) 返回的过长字段数据处理(用分号分隔的一个长字段): t ...
- 二:Spring Mvc 框架
二:SpringMVC 异常码: 405:请求不允许 404:资源不存在 400:参数有问题 500:代码有问题 SpringMvc是Spring FrameWork提供的WEB组件,是目前的主流的实 ...
- SpringBoot集成Tomcat服务
目录 一.Tomcat集成 1.依赖层级 2.自动化配置 二.Tomcat架构 三.Tomcat配置 1.基础配置 2.属性配置类 3.配置加载分析 四.周期管理方法 1.控制类 2.核心方法 五.参 ...
- 前后端分离项目创建项目详细过程项、目需求分析、pip换源、创建虚环境、后端目录调整以及解决问题
引言,本项目是前后端分离的,前端用Vue2 后端用Django,后台管理部分是通过simpleUI完成的项目,项目名称为路飞,是商城类(知识付费项目).本篇文章主要讨论一个前后端分离的项目第一步怎么做 ...
- c语言以及高级语言中的float到底是什么以及IEEE754
对内存里float4字节的好奇 初学计算机都要学那个什么二进制十进制什么补码 反码那些玩意儿哈,由于最近要做一个单片机往另外一个单片机发数据的需求,直接c语言指针 然后float4字节传过去不就得了吗 ...
- Eureka高可用集群服务端和客户端配置
微服务应用中,生产环境一般都需要保障服务注册中心的高可用!高可用也分好几个等级,例如:同数据中心(可用Zone区)高可用-->同地域(Region)跨数据中心(可用Zone区)高可用--> ...
- [BSR文摘] 如何解释CRP正常而多普勒超声显示关节炎活动的RA亚型
如何解释CRP正常而多普勒超声显示关节炎活动的RA亚型 Braford CM, et al.Rheumatology 2016. Present ID: 72. 背景:临床门诊越来越多地利用肌肉骨骼超 ...