Linux零拷贝原理
Linux零拷贝原理
前言
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量。
DMA技术
在没有DMA技术之前,IO过程是这样的:

可以看到,整个数据的传输过程,都要需要 CPU 亲自参与搬运数据的过程,而且这个过程,CPU 是不能做其他事情的。当我们用千兆网卡或者硬盘传输大量数据的时候,都用 CPU 来搬运的话,肯定忙不过来。
DMA即直接内存访问(*Direct Memory Access*) 技术:在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。

也就是说等待磁盘读取数据并将其拷贝到内核空间这部分工作交给了DMA控制器,解放CPU,从而让CPU做更重要的事情。
文件传输过程及优化
如果我们需要将文件读取出来,然后通过网络协议发送给客户端
read(file,buf,len);
write(socket,buf,len);
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
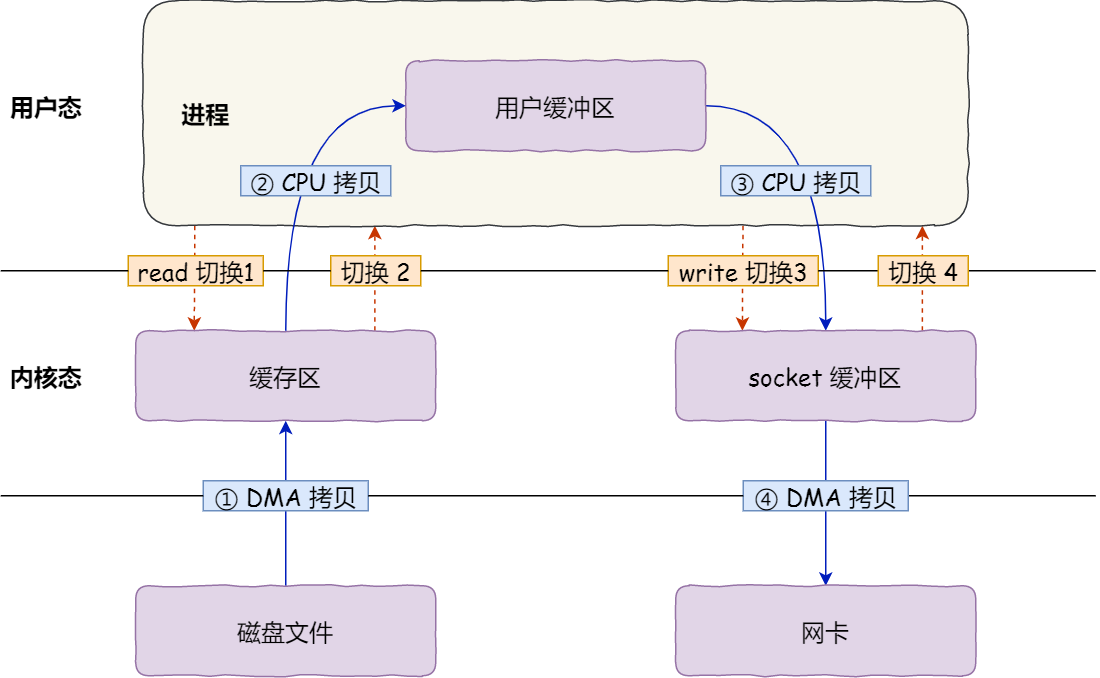
期间一共发生4次用户态和内核态的上下文切换,因为一次系统调用需要来回两次切换。
还发生了4次数据拷贝操作,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的。过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
如何减少内核态和用户态之间的切换的次数呢?
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
如何减少内存拷贝次数呢?
「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
零拷贝技术
零拷贝(Zero-Copy)是一种 I/O 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。
因此零拷贝技术只传输文件的原始内容,不允许进程对文件内容作进一步的加工的,比如压缩数据和加密。
目前只有在使用NIO和Epoll传输时才可以使用该特性。
零拷贝技术实现的方式通常有 2 种:
mmap + write
buf = mmap(file, len);
write(sockfd, buf, len);现在操作系统都使用虚拟内存,好处是:
1、多个虚拟内存可以指向同一块物理地址
2、虚拟内存的空间可以远大于物理内存的空间
正是有了虚拟内存的出现,我们可以把内核空间和用户空间的虚拟地址映射到同一块物理地址上,这样在IO操作时就不用来回复制来。
mmap()系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
当DMA将数据拷贝到内核缓冲区中后,应用进程跟内核共享这个缓冲区。
应用进程再调用
write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据。但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数
sendfile()。首先,它可以替代前面的
read()和write()这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。

这也不是真正的零拷贝,因为还是有CPU的参与。
于是,从 Linux 内核
2.4版本开始起,对于支持网卡支持 SG-DMA 技术的情况下,sendfile()系统调用的过程发生了点变化。CPU不做数据拷贝,而只是将缓存区里的内存地址和偏移量记录到相应的socket缓冲区里,SG-DMA 控制器直接将内核缓存中的数据拷贝到网卡的缓冲区里。
整个过程只有2次数据拷贝,两次上下文切换。整体来说可以把文件传输性能提升一倍以上。
这就是所谓的零拷贝技术,全程没有CPU来搬运数据,所有数据都是通过DMA完成的。
splice
splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了两者之间的 CPU 拷贝操作。
splice使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备。

整个过程发生2次上下文切换和2次DMA拷贝,CPU只是在内核缓冲区和socket缓冲区之间建立管道。
kafka就使用了零拷贝技术,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
kafka文件传输的代码最终调用的是JAVA NIO库里的transferTo方法,如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
nginx默认也是开启零拷贝技术。
PageCache(内核缓冲区)作用
PageCache就是上面所说的内核缓冲区,它实际上是磁盘高速缓存。
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 IO 合并与预读,这也是顺序读比随机读性能好的原因。这些优势,进一步提升了零拷贝的性能。
用PageCache 来缓存最近被访问的数据,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能。
这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。
另外,由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,无法享受缓存带来的优势。
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,反而由于多做一次的数据拷贝损失性能。这样在高并发的环境下,会带来严重的性能问题。
大文件传输实现方式
前面说到的所有方式都有一个特点:就是用户进程需要阻塞等待,因此,这种操作被称为同步阻塞IO。
对于阻塞的问题,可以用异步 I/O 来解决。

用户进程向内核发起IO请求后直接返回,处理其他任务。
而内核将磁盘控制器缓冲区的数据直接拷贝到用户缓冲区,然后通知用户进程来读。
异步IO没有涉及到PageCache,这种绕开PageCache的IO也叫直接IO,使用PageCache的IO叫做缓存IO。
由于 CPU 和磁盘 I/O 之间的执行时间差距,会造成大量资源的浪费,因此直接IO一般都是和异步IO结合才有意义。
前面也提到,大文件的传输不应该使用 PageCache,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache。
于是,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
而传输小文件时,使用零拷贝技术。
知识点回顾
虚拟内存
虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)。
虚拟内存通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换,加载到物理内存中来。 每个进程所能使用的虚拟地址大小和 CPU 位数有关。在 32 位的系统上,虚拟地址空间大小是 2 ^ 32 = 4G。
虚拟内存的好处:
- 更大的地址空间,并且地址空间时连续的,使得程序编写链接更简单
- 地址隔离:进程之间不会影响
- 数据保护:每块虚拟内存都有相应的读写属性,保护程序代码不被修改,增加系统安全性
- 内存映射:不同的虚拟内存可以映射到同一块物理内存上,可以实现进程之间相互共享数据
- 物理内存管理:应用程序申请和释放的空间操作都是针对虚拟内存的,实际的物理内存管理是由操作系统完成,从而可以更好的利用内存,平衡进程间对内存的需求。
内核态和用户态
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的权限。为了避免用户进程直接操作内核,保证内核安全,操作系统将虚拟内存划分为两部分,一部分是内核空间(Kernel-space),一部分是用户空间(User-space)。 内核进程和用户进程所占的虚拟内存比例是 1:3
在 Linux 系统中,内核模块运行在内核空间,对应的进程处于内核态;内核空间总是驻留在内存中,它是为操作系统的内核保留的。内核态可以执行任意命令,调用系统的一切资源。
而用户程序运行在用户空间,对应的进程处于用户态。处于用户态的进程不能访问内核空间中的数据,也不能直接调用内核函数的 ,因此要进行系统调用的时候,就要将进程切换到内核态才行。用户态只能执行简单的运算,不能直接调用系统资源。用户态必须通过系统接口(System Call),才能向内核发出指令。
写时复制
在某些情况下,内核缓冲区可能被多个进程所共享,如果某个进程想要这个共享区进行 write 操作,由于 write 不提供任何的锁操作,那么就会对共享区中的数据造成破坏,写时复制的引入就是 Linux 用来保护数据的。
写时复制指的是当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中。这样做并不影响其他进程对这块数据的操作,每个进程要修改的时候才会进行拷贝,所以叫写时拷贝。这种方法在某种程度上能够降低系统开销,如果某个进程永远不会对所访问的数据进行更改,那么也就永远不需要拷贝。
BIO、NIO、AIO
这些是网络编程模型,由于socket也是一种特殊的文件,从网络中收到数据和从磁盘读取数据过程差不多,所以被称为IO模型,一个IO请求就可以看成一个网络连接。
同步:同步是用户线程需要等待内核IO操作完成,才能继续执行;
异步:异步不需要等内核完成,内核完成后会通知用户线程来读取。
阻塞:阻塞时用户线程需要等IO操作彻底完成后才能返回用户空间。
非阻塞:非阻塞是IO操作被调用后立即返回用户状态值。
BIO(Blocking IO):同步阻塞模型,传统的IO模型,每个IO操作对应一个Thread,上面我们举的例子都是传统IO。
NIO(NonBlocking IO):同步非阻塞模型,虽然可以立即返回用户空间,但用户线程需要轮询来读取数据。
AIO:异步非阻塞模型。
Linux零拷贝原理的更多相关文章
- 【面试普通人VS高手】Kafka的零拷贝原理?
最近一个学员去滴滴面试,在第二面的时候遇到了这个问题: "请你简单说一下Kafka的零拷贝原理" 然后那个学员努力在大脑里检索了很久,没有回答上来. 那么今天,我们基于这个问题来看 ...
- Netty 零拷贝(一)Linux 零拷贝
Netty 零拷贝(一)Linux 零拷贝 本文探讨 Linux 中主要的几种零拷贝技术以及零拷贝技术适用的场景. 一.几个重要的概念 1.1 用户空间与内核空间 操作系统的核心是内核,独立于普通的应 ...
- Linux零拷贝技术 直接 io
Linux零拷贝技术 .https://kknews.cc/code/2yeazxe.html https://zhuanlan.zhihu.com/p/76640160 https://clou ...
- NIO学习笔记,从Linux IO演化模型到Netty—— Linux零拷贝
这里只是感性地认识Linux零拷贝,不涉及具体细节. 1.Linux传统的数据拷贝 用户进程是不能直接访问文件系统的,要先切换到内核态,发起系统调用,DMA把磁盘中的数据写入内核空间,内核再把数据拷贝 ...
- Linux零拷贝技术
本文转载自Linux零拷贝技术 导语 本文讲解 Linux 的零拷贝技术,云计算是一门很庞大的技术学科,融合了很多技术,Linux 算是比较基础的技术,所以,学好 Linux 对于云计算的学习会有比较 ...
- Linux零拷贝技术,看完这篇文章就懂了
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复 「1024」 即可领取,欢迎大家关注,二维码文末可以扫. 本文讲解 ...
- Linux 零拷贝技术
简介 零拷贝(zero-copy)技术可以减少数据拷贝和共享总线操作的次数,消除通信数据在存储器之间不必要的中间拷贝过程,有效地提高通信效率,是设计高速接口通道.实现高速服务器和路由器的关键技术之一. ...
- Linux "零拷贝" sendfile函数中文说明及实际操作分析
Sendfile函数说明 #include ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count); sendfile ...
- 框架篇:Linux零拷贝机制和FileChannel
前言 大白话解释,零拷贝就是没有把数据从一个存储区域拷贝到另一个存储区域.但是没有数据的复制,怎么可能实现数据的传输呢?其实我们在java NIO.netty.kafka遇到的零拷贝,并不是不复制数据 ...
随机推荐
- C# · 委托语句简化演变
1.委托基础语句形式 namespace QLVision { delegate void dHelp();//定义委托 static class Program { /// <summary& ...
- Linux的文件路径和访问文件相关命令
Linux的绝对和相对路径 绝地路径 绝对路径:以根作为起来的路径 相对路径 相对路径:以当前位置作为起点 文件操作命令 显示当前工作目录: pwd命令 pwd:显示文件所在的路径 基名:basena ...
- 【python基础】第09回 数据类型内置方法 01
本章内容概要 1.数据类型的内置方法简介 2.整型相关方法 3.浮点型相关方法 4.字符串相关方法 5.列表相关方法 本章内容详情 1.数据类型的内置方法简介 数据类型是用来记录事物状态的,而事物的状 ...
- 这么多房子,哪一间是我的小窝?python采集数据并做数据可视化~
前言 嗨喽,大家好呀!这里是小熊猫 环境使用: (https://jq.qq.com/?_wv=1027&k=ONMKhFSZ) Python 3.8 Pycharm 模块使用: (https ...
- exe4j下载和使用
https://blog.csdn.net/weixin_44678104/article/details/101015065
- CF989C A Mist of Florescence 题解
因为 \(1 \leq a,b,c,d \leq 100\) 所以每一个颜色都有属于自己的联通块. 考虑 \(a = b=c=d=1\) 的情况. AAAAAAAAAAAAAAAAAAAAAAAAAA ...
- HHL论文及代码理解(Generalizing A Person Retrieval Model Hetero- and Homogeneously ECCV 2018)
行人再识别Re-ID面临两个特殊的问题: 1)源数据集和目标数据集类别完全不同 2)相机造成的图片差异 因为一般来说传统的域适应问题源域和目标域的类别是相同的,相机之间的不匹配也是造成行人再识别数据集 ...
- Mybatis源码解读-配置加载和Mapper的生成
问题 Mybatis四大对象的创建顺序? Mybatis插件的执行顺序? 工程创建 环境:Mybatis(3.5.9) mybatis-demo,参考官方文档 简单示例 这里只放出main方法的示例, ...
- 鸟枪换炮,利用python3对球员做大数据降维(因子分析得分),为C罗找到合格僚机
鸟枪换炮,利用python3对球员做大数据降维(因子分析得分),为C罗找到合格僚机 原文转载自「刘悦的技术博客」https://v3u.cn/a_id_176 众所周知,尤文图斯需要一座欧冠奖杯,C罗 ...
- 企业级数据治理工作怎么开展?Datahub这样做
大数据发展到今天,扮演了越来越重要的作用.数据可以为各种组织和企业提供关键决策的支持,也可以通过数据分析帮助发现更多的有价值的东西,如商机.风险等等. 在数据治理工作开展的时候,往往会有一个专门负责数 ...