C/C++内存对齐原则
C/C++内存对齐
what && why
当用户自定义类型时(struct 或 class),编译器会自动计算该类型占用的字节数。
C/C++ 为什么要内存对齐?我道行太浅,摘抄了网上的一个解释。
为了方便从内存中读取数据。假设没有内存对齐,在内存中存储一个 int 变量 x(占 4 字节),放在了地址 2-5 上。现在要读取 x 到寄存器中,CPU 知道读 int 一次应该读 4 字节,但是不会直接读地址 2-5(为什么不会?我也不知道啊!但是 CPU 有直接读 2-5 地址的功能,但它没有用起来),一次读出来,而是先读 0-3,再读 4-7,丢掉多余的字节。可以看到对齐后少读了一次内存,性能肯定得到提升了(我们知道 C/C++ 是追求极致性能的)。
举例
#include <iostream>
using namespace std;
// #pragma pack (1)
struct Test
{
int i1;
char c;
int i2;
double d;
};
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl; // 24
return 0;
}
如果没有内存对齐,Test 类型的大小应该是 4+1+4+8 = 17 字节,经过对齐后变成了 24 字节。
第 5 行注释就是设置内存对齐基数,取值一般是 1, 2, 4, 8,若该值为 1 则表示不对齐(不信就去掉注释再运行一次,输出肯定是 17)。
内存对齐原则
- 整体对齐基数 n:假设默认或通过
#pragma pack ()设置的对齐基数是 i(现在机器一般都是 8,旧一些的应该是 4),struct 中“最大”成员所占用的字节数 j,则n = min(i, j),也就是说这个 struct 类型最终的大小必须是 n 的倍数。 - 成员对齐基数 k:它的计算方式是
k = min(sizeof(memberType), n),它要求每个成员的 offset 必须是 k 的倍数,第一个成员的 offset 为 0。比如一个 short 成员的k = min(sizeof(short), n)
可以看出,当 i = 1 时就是不对齐;当 i >= j 时,i 不起作用。
操练一下
假设 n = 8
先进行成员对齐:
#include <iostream>
using namespace std;
struct Test
{
int i1; // offset为0, 占用第0-3字节
char c; // 1 < 8, offset是1的倍数, 因此offset为4, 占用第4字节
int i2; // 4 < 8, offset是4的倍数, 因此offset为8, 占用第8-11字节
double d; // 8 == 8, offset是8的倍数, 因此offset为16, 占用第16-23字节
// 构造函数
Test(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
// 来验证一下
int main(int argc, char* argv[])
{
cout << sizeof(Test) << endl;
Test *pt = new Test(1, 'a', 2, 1.25); // 基地址
unsigned char* ppt = (unsigned char*)pt; // 强制类型转换, 按字节读
for (int i = 0; i < sizeof(Test); ++i) {
printf("%x ", *(ppt + i));
}
cout << endl;
// 1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f
return 0;
}
再进行整体对齐:这个 struct 类型所需字节为 24 字节,恰好是 n 的倍数,无须在尾部额外填充。
内存排列如下图所示:
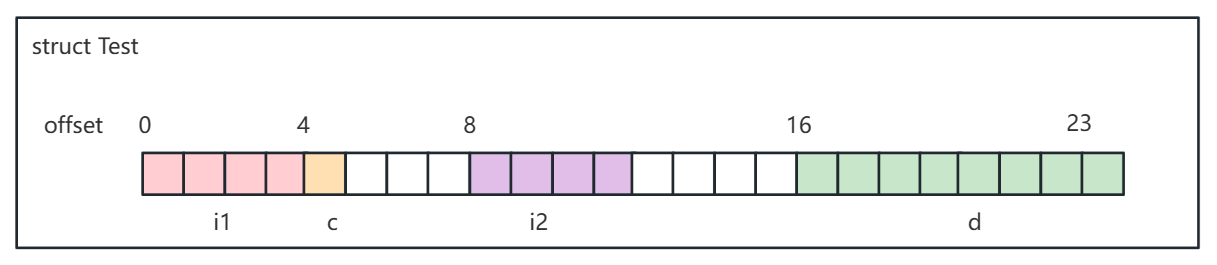
其中白色格子代表填充,其内容是不确定的。
按十六进制输出:1 0 0 0 61 f0 ad ba 2 0 0 0 d f0 ad ba 0 0 0 0 0 0 f4 3f
可以看到前面 4 字节是 1 0 0 0,是
i1 = 1;第 5 字节是 61,是
'a'的十六进制 ASCII 码;然后 6-7 字节是填充的内容,不确定的;
第 8-11 字节是 2 0 0 0,是
i2 = 2;第 12 - 15 字节是填充的内容,不确定的;
第 16-23 字节是
d = 1.25的底层二进制表示(怎么算的我也忘了好久了,参考神书《CSAPP:深入理解计算机系统》即可找回记忆)。
留下疑问
问:在自定义类型嵌套时,比如 Test1 嵌套正在 Test2 中,此时应该怎么进行内存对齐呢?
struct Test1
{
int i1;
char c;
int i2;
double d;
// 构造函数
Test1(int ii1, char cc, int ii2, double dd):
i1(ii1), c(cc), i2(ii2), d(dd) {}
};
struct Test2
{
Test1 t1;
int x;
};
答:先计算 Test1 所占字节大小 sizeof(Test1),然后继续按照上述基本原则计算 Test2 即可。如果是多重嵌套,那就递归找到那个成员全都是基本类型的 struct 开始计算,然后回溯。
问:继承体系中如何进行内存对齐?
struct A
{
int i;
char c1;
};
struct B: public A
{
char c2;
};
struct C: public B
{
char c3;
};
答:我也不会!我郁闷了,在我 64 位 Windows 操作系统 + gcc8.1.0 和 ubuntu18.04 + gcc7.5.0 上的运行结果都是 12!
但是我参考的一篇博客说,他的结果是 8 或 16!C++ 内存对齐 - tenos - 博客园 (cnblogs.com)
博客里说根据编译器类型拥有两种方式:先继承后对齐和先对齐后继承。
但是我无论按哪种方式,#pragma pack ()取 4 或 8,排列组合 2*2=4 种可能,我都算不出来 12!但是我能算出 8 和 16!
希望有朋友可以解答我的疑惑,万分感谢。
最后
如果本文对你有帮助,请点个赞吧。
有任何疑问,欢迎评论和我一起讨论。
C/C++内存对齐原则的更多相关文章
- C/C++ 内存对齐原则及作用
struct/class/union内存对齐原则有四个: 1).数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储 ...
- c++内存对齐
内存对齐原则: 1.数据成员对齐规则:struct, union的数据成员,第一个数据成员放在offset为0的地方,之后的数据成员的存储起始位置都是放在该数据成员大小的整数倍位置.如在32bit的机 ...
- 【转】C/C++ struct/class/union内存对齐
原文链接:http://www.cnblogs.com/Miranda-lym/p/5197805.html struct/class/union内存对齐原则有四个: 1).数据成员对齐规则:结构(s ...
- C/C++中的内存对齐 C/C++中的内存对齐
一.什么是内存对齐.为什么需要内存对齐? 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址 ...
- C/C++中struct/union/class内存对齐
struct/union/class内存对齐原则有四个: 1).数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储 ...
- C/C++: C++位域和内存对齐问题
1. 位域: 1. 在C中,位域可以写成这样(注:位域的数据类型一律用无符号的,纪律性). struct bitmap { unsigned a : ; unsigned b : ; unsigned ...
- 解析C语言结构体对齐(内存对齐问题)
C语言结构体对齐也是老生常谈的话题了.基本上是面试题的必考题.内容虽然很基础,但一不小心就会弄错.写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的 ...
- C结构体中数据的内存对齐问题
转自:http://www.cnblogs.com/qwcbeyond/archive/2012/05/08/2490897.html 32位机一般默认4字节对齐(32位机机器字长4字节),64位机一 ...
- struct内存对齐1:gcc与VC的差别
struct内存对齐:gcc与VC的差别 内存对齐是编译器为了便于CPU快速访问而采用的一项技术,对于不同的编译器有不同的处理方法. Win32平台下的微软VC编译器在默认情况下采用如下的对齐规则: ...
- c语言内存对齐问题
#include <stdio.h>#pragma pack(4)struct stu{char a;short b;int c;char d;};int main(){printf(&q ...
随机推荐
- 记一次多个Java Agent同时使用的类增强冲突问题及分析
摘要:Java Agent技术常被用于加载class文件之前进行拦截并修改字节码,以实现对Java应用的无侵入式增强. 本文分享自华为云社区<记一次多个JavaAgent同时使用的类增强冲突问题 ...
- 又拍云之 Keepalived 高可用部署
在聊 Keepalived 之前,我们需要先简单了解一下 VRRP.VRRP(Virtual Router Redundancy Protocol)即虚拟路由冗余协议,是专门为了解决静态路由的高可用而 ...
- WPF之MVVM实践中的Command与CommandParameter
先记录一下,方便以后复习. https://www.cnblogs.com/babietongtianta/p/3474101.html
- 第2-3-2章 环境搭建-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
目录 5. 文件服务开发 5.1 环境搭建 5.1.1 数据库环境搭建 5.1.2 Nacos环境搭建 5.1.3 Nginx环境搭建 5.1.4 maven工程环境搭建 5. 文件服务开发 全套代码 ...
- scrapy框架命令
scrapy startproject #创建scrapy项目 scrapy genspider test www.baidu.com #在项目下的spider目录下生成爬虫文件 test爬虫名称 w ...
- 解决Anaconda关联VSCode使用conda运行Python报错(无法将“conda”项识别为 cmdlet、函数、脚本文件或可运行程序)
错误 刚安装好Anaconda之后创建好VS Code环境运行Python会报错,但是仍然是可以正常运行,强迫症想解决报错 PS C:\Users\Satan\Documents\Code\Pytho ...
- <七>深入理解new和delete的原理
new ,delete 运算符 int *p =new int; delete p; 看一下汇编代码 可以看到new 和delete 运算符其实也是 operator运算符重载函数的调用 malloc ...
- 【图像处理笔记】SIFT算法原理与源码分析
[图像处理笔记]总目录 0 引言 特征提取就是从图像中提取显著并且具有可区分性和可匹配性的点结构.常见的点结构一般为图像内容中的角点.交叉点.闭合区域中心点等具有一定物理结构的点,而提取点结构的一般思 ...
- 记一次 .NET 某工控MES程序 崩溃分析
一:背景 1.讲故事 前几天有位朋友找到我,说他的程序出现了偶发性崩溃,已经抓到了dump文件,Windows事件日志显示的崩溃点在 clr.dll 中,让我帮忙看下是怎么回事,那到底怎么回事呢? 上 ...
- bitlocker加密如何找密钥解锁
步骤1:在其他设备上登录[微软账号],地址:https://account.microsoft.com 步骤2:找到[自己的设备],查看[Bitlocker]密钥登录进去能看到[设备],找要解锁的那台 ...