drf-序列化器、反序列化、反序列化校验
1.APIView执行流程
1.之前我们是基于django原生的View编写接口,drf提供给咱们的一个类APIView,以后使用drf写视图类,都是继承这个类及其子类,APIView本身就是继承了Django原生的View。
1.1 基于APIView+JsonResponse编写接口:
views中代码:
from .models import Book
from rest_framework.views import APIView
from django.http import JsonResponse
class BookView(APIView):
def get(self,request):
book_queryset = Book.objects.all()
book_list = []
for book_obj in book_queryset:
book_list.append({'name':book_obj.name,'price':book_obj.price,'publish':book_obj.publish})
return JsonResponse(book_list,safe=False)
1.2 基于APIView+Response写接口
Response可以序列化字典和列表,并且不需要加参数:
from rest_framework.response import Response
from .models import Book
from rest_framework.views import APIView
class BookView(APIView):
def get(self, request):
book_queryset = Book.objects.all()
book_list = []
for book_obj in book_queryset:
book_list.append({'name':book_obj.name,'price':book_obj.price,'publish':book_obj.publish})
return Response(book_list)
以上两种效果一致,都可以拿到所有的图书信息:
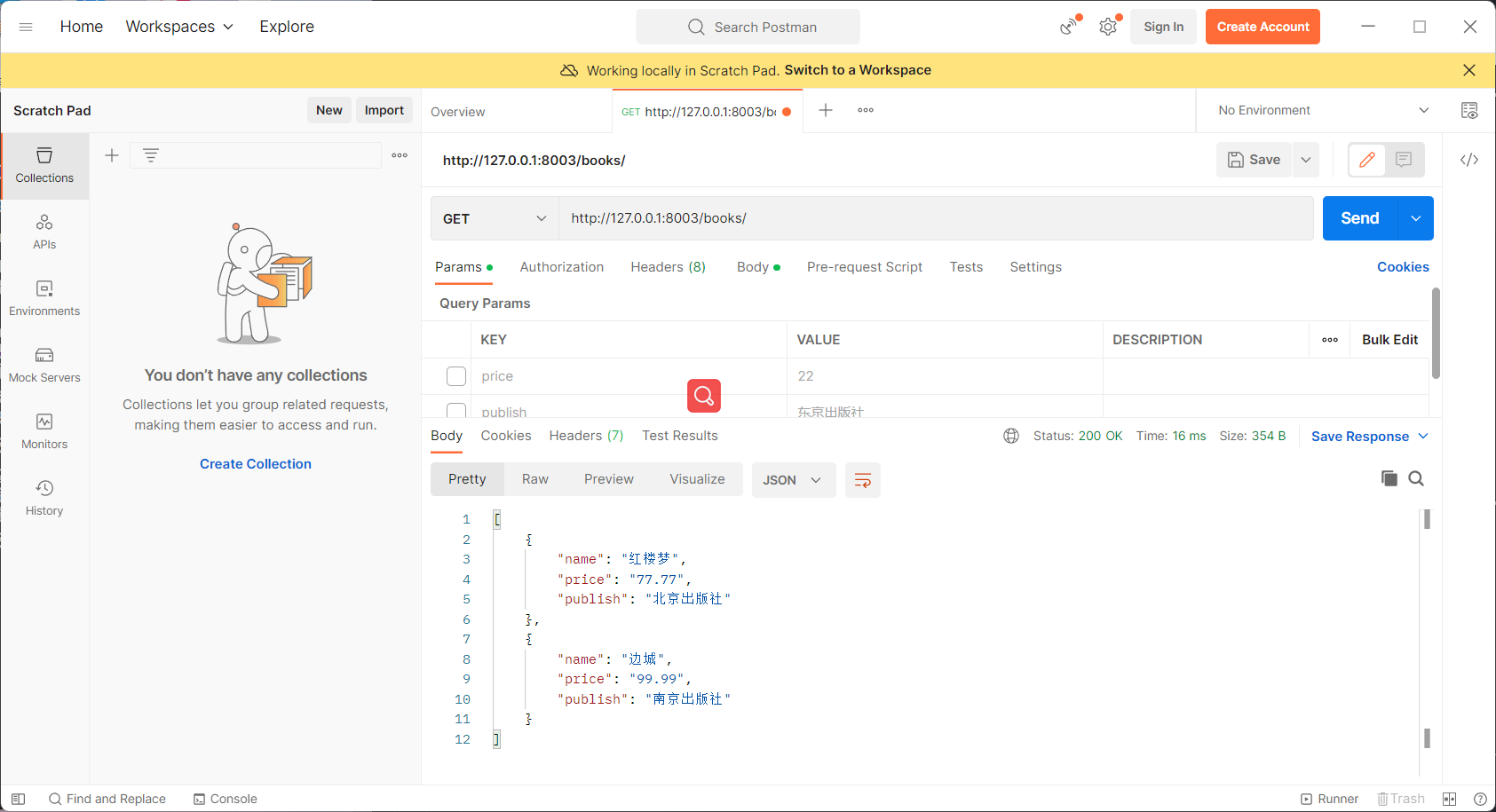
2.APIView的执行流程
1.路由层中:path('books/', views.BookView.as_view()),找到的as_view()是APIView中的as_view(),虽然APIView也继承View但是APIView中本身就有as_view()。
2.源码分析:
@classmethod
def as_view(cls, **initkwargs):
view = super().as_view(**initkwargs)
"""
父类view中as_view()的返回值还是view,把django原生View的as_view方法中的闭包函数中的view拿出来了。
"""
return csrf_exempt(view)
"""
相当于在所有的方法上面加了csrf_exempt装饰器,所以此后我们不需要注掉settings中的csrf。
"""
路由匹配成功,执行csrf_exempt(view)(request)>>>View的as_view中的闭包函数view>>>self.dispatch>>>self是视图类对象,在APIView中找到了dispatch:
def dispatch(self, request, *args, **kwargs):
"""
此时的request是django原生的request,老的request
"""
request = self.initialize_request(request, *args, **kwargs)
"""
把老的request包装成了新的request,这个是drf提供的Request类的对象。到此以后,这个request就是新的了。老的requestrequest._request。
"""
self.request = request
try:
# 执行了三大认证【认证,频率,权限】,使用新的request,不读
self.initial(request, *args, **kwargs)
# Get the appropriate handler method
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
"""
把新的request传入了,视图类的方法中get的request也是新的
"""
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
总结:
1.去除了所有方法的csrf认证
2.包装了新的request,以后在视图类中用的request是新的request,是Request类的对象,不是原生的了
3.在执行视图类的方法之前,执行了3大认证
4.如果在3大认证或视图函数方法执行过程中出了错,会有异常捕获----》全局异常捕获
5.以后视图类方法中的request都是新的了
3.Request对象源码分析(了解)
# 新的Request---》区别于老的
# 老的:django.core.handlers.wsgi.WSGIRequest
# 新的:from rest_framework.request import Request
-新的 request._request 是老的
# Request源码
-方法 __getattr__
-在视图类的方法中,执行request.method ,新的request是没有method的,就触发了新的Request的__getattr__方法的执行
def __getattr__(self, attr):
try:
# 从老的request中反射出 要取得属性
return getattr(self._request, attr)
except AttributeError:
return self.__getattribute__(attr)
-request.data--->这是个方法,包装成了数据属性
-以后无论post,put。。放在body中提交的数据,都从request.data中取,取出来就是字典
-无论是那种编码格式
-request.query_params--->这是个方法,包装成了数据属性
-get请求携带的参数,以后从这里面取
-query_params:查询参数--->restful规范请求地址中带查询参数
-request.FILES--->这是个方法,包装成了数据属性
-前端提交过来的文件,从这里取
# Request类总结
-1 新的request用起来,跟之前一模一样,因为新的取不到,会取老的__getattr__
-2 request.data 无论什么编码,什么请求方式,只要是body中的数据,就从这里取,字典
-3 request.query_params 就是原来的request._request.GET
-4 上传的文件从request.FILES
# python 中有很多魔法方法,在类中,某种情况下触发,会自动执行
-__str__:打印对象会调用
-__init__:类() 会调用
-__call__: 对象() 会调用
-__new__:
-__getattr__:对象.属性,如果属性不存在,会触发它的执行
4.序列化器介绍和快速使用
4.1 序列化多条数据
1.在写接口时,需要序列化,需要反序列化,而且反序列化的过程中要做数据校验---》drf直接提供了固定的写法,只要按照固定写法使用,就能完成上面的三个需求。
2.drf提供了两个类:Serializer,ModelSerializer。以后只需要写自己的类,继承drf提供的序列化类,使用其中的某些方法,就能完成上面的操作。
3.代码:
serializer.py:
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
publish = serializers.CharField()
"""
序列化类中的字段名,需要和模型类保持一致
"""
views.py:
class BookView(APIView):
def get(self,request):
book_queryset = Book.objects.all()
ser = BookSerializer(instance=book_queryset,many=True)
# ser.data是一个OrderDict:[OrderedDict([('name', '北方出版社'), ('location', '北京'), ('phone', '111')]), OrderedDict([('name', '南方出版社'), ('location', '南京'), ('phone', '222')])]
# ser.data单条是字典,多条是列表。
return Response(ser.data)
urls.py:
urlpatterns = [
path('admin/', admin.site.urls),
path('books/',views.BookView.as_view()),
]
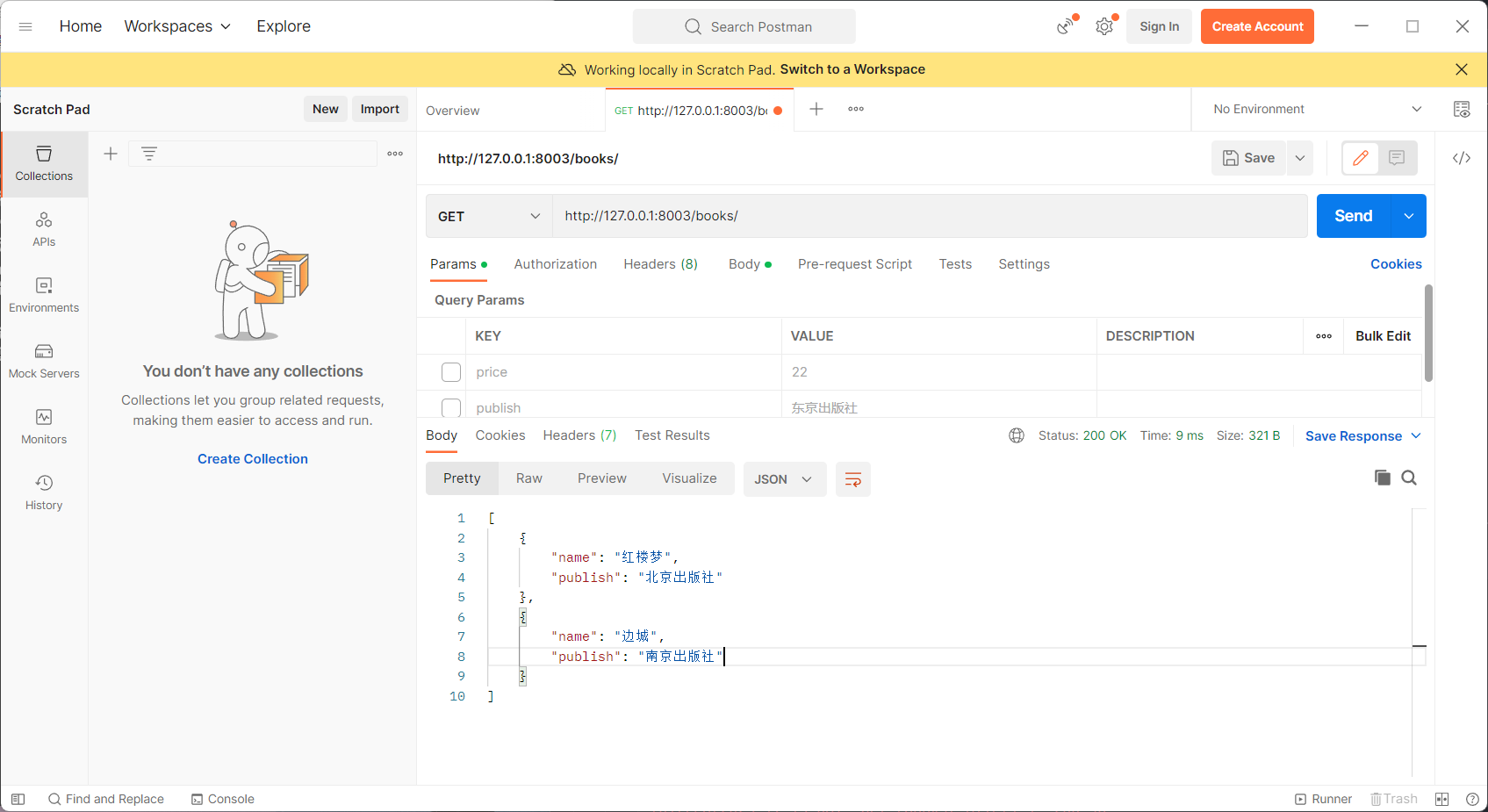
4.2序列化单条数据
序列化多条数据需要在类BookSerializer中传入参数many=True,序列化单条数据不需要上传。
1.代码:
serializer.py:
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
publish = serializers.CharField()
views.py:
class BookDetailView(APIView):
def get(self,request,*args,**kwargs):
book_obj = Book.objects.filter(pk=kwargs.get('pk')).first()
"""
序列化(查询)时需要在序列化类中跟instance参数,instance后面既可以跟queryset也可以跟obj。如果是多个queryset需要跟参数:many=True
"""
ser = BookSerializer(instance=book_obj)
return Response(ser.data)
urls.py:
urlpatterns = [
path('admin/', admin.site.urls),
path('book/<int:pk>/',views.BookDetailView.as_view()),
]
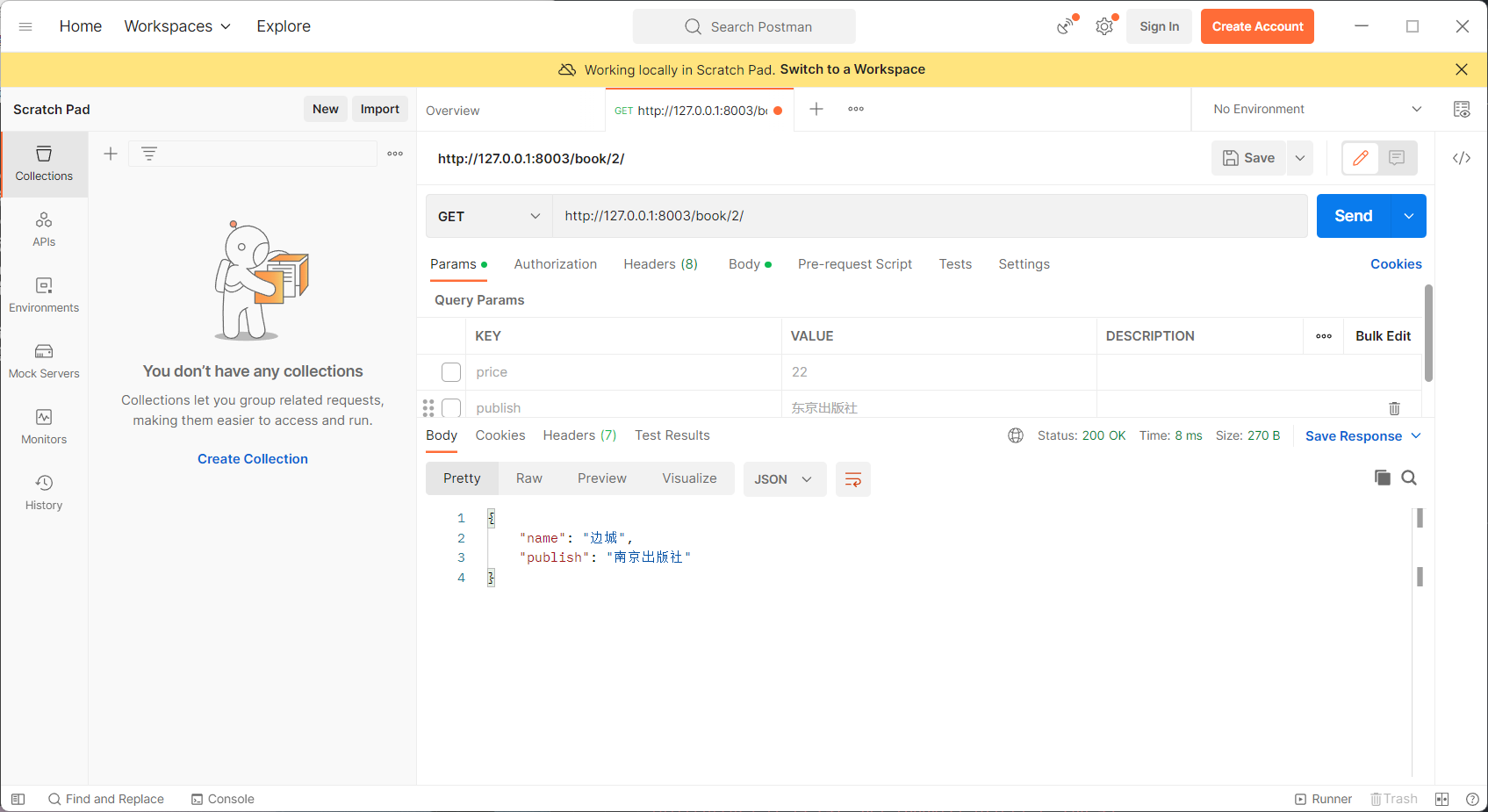
5.反序列化
5.1反序列化新增
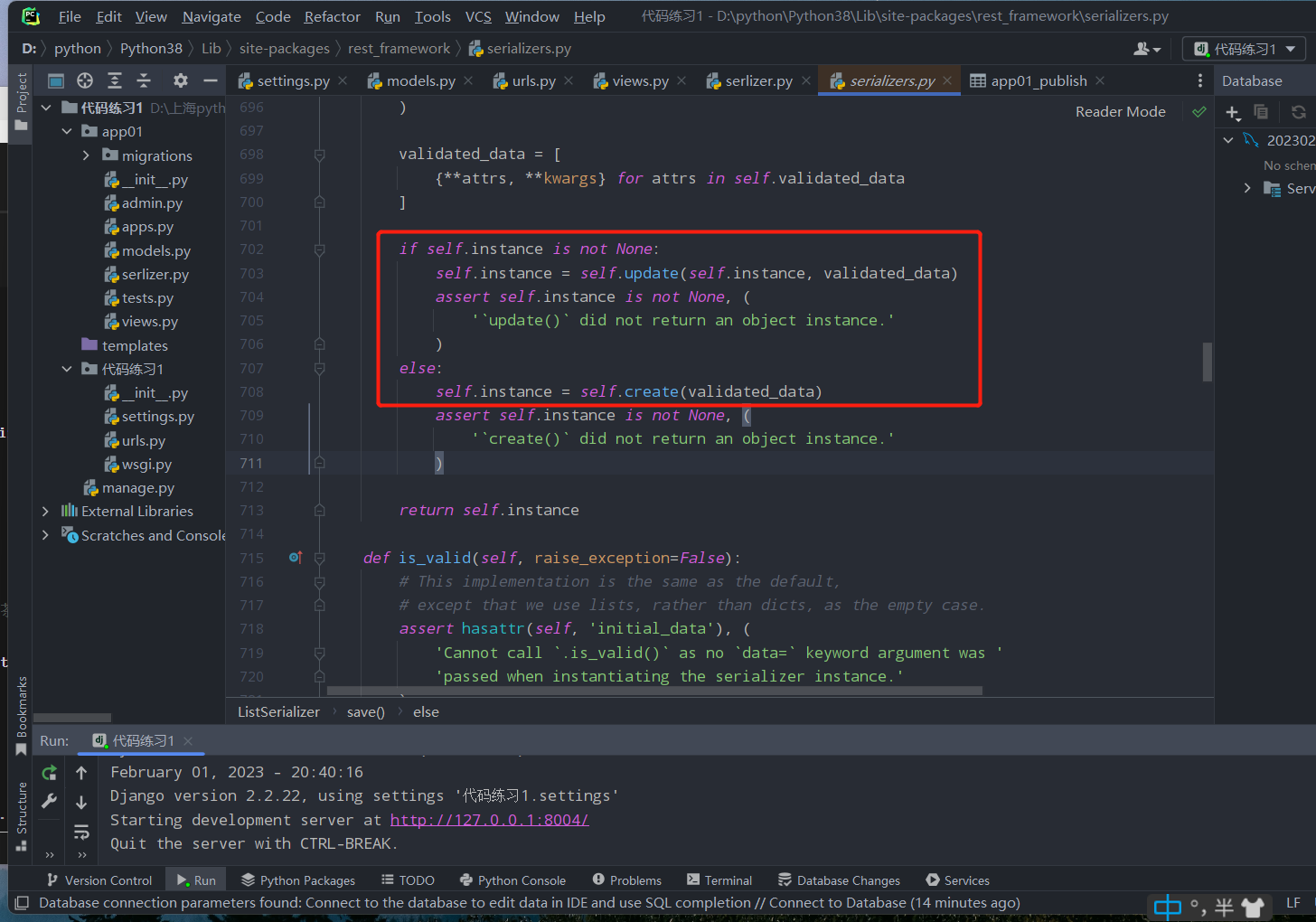
从源码可得知:更新需要上传instance参数,新增不需要上传instance参数。
serializer.py:
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
# 需要自己构造create方法保存
def create(self, validated_data):
# validdated_data:{'name': '茶花女', 'price': '66', 'publish': '东京出版社'}
book_obj = Book.objects.create(**validated_data)
return book_obj
views.py:
class BookView(APIView):
def get(self,request):
book_queryset = Book.objects.all()
ser = BookSerializer(instance=book_queryset,many=True)
return Response(ser.data)
def post(self,request):
ser = BookSerializer(data=request.data)
if ser.is_valid():
ser.save()
# 调用save会触发我们自己写的create,保存起来
return Response({'code':100,'msg':'新增成功','result':ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
5.2 反序列化的修改
post请求和put请求因为要向后端发送数据,所以后端生成seriialize对象时要上传data=request.data拿到前端上传的数据,无论前端是什么编码,拿到的都是字典。
其中form-data和urlencoded传入通过request.data拿到的是QueryDict,通过JSON上传拿到的是普通的dict。
request.query_params相当于原来的request.GET。
serializer.py:
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
print(validated_data)
book_obj = Book.objects.create(**validated_data)
return book_obj
def update(self, instance, validated_data):
# instance是修改的对象
# validated_data:校验符合的数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
instance.save()
return instance
views.py:
class BookDetailView(APIView):
def get(self,request,*args,**kwargs):
book_obj = Book.objects.filter(pk=kwargs.get('pk')).first()
ser = BookSerializer(instance=book_obj)
return Response(ser.data)
def put(self,request,pk):
book = Book.objects.filter(pk=pk).first()
print(request.data)
ser = BookSerializer(data=request.data,instance=book)
if ser.is_valid():
ser.save()
return Response({'code':100,'msg':'修改成功','result':ser.data})
else:
return Response({'code':101,'msg':ser.errors})
5.3 删除单条
views.py:
class BookDetailView(APIView):
def get(self,request,*args,**kwargs):
book_obj = Book.objects.filter(pk=kwargs.get('pk')).first()
ser = BookSerializer(instance=book_obj)
return Response(ser.data)
def put(self,request,pk):
book = Book.objects.filter(pk=pk).first()
print(request.data)
ser = BookSerializer(data=request.data,instance=book)
if ser.is_valid():
ser.save()
return Response({'code':100,'msg':'修改成功','result':ser.data})
else:
return Response({'code':101,'msg':ser.errors})
def delete(self,request,pk):
Book.objects.filter(pk=pk).delete()
return Response({'code':100,'msg':'删除成功'})
6.反序列化的校验
from rest_framework import serializers
from .models import Book
from rest_framework.exceptions import ValidationError
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
print(validated_data)
book_obj = Book.objects.create(**validated_data)
return book_obj
def update(self, instance, validated_data):
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
instance.save()
return instance
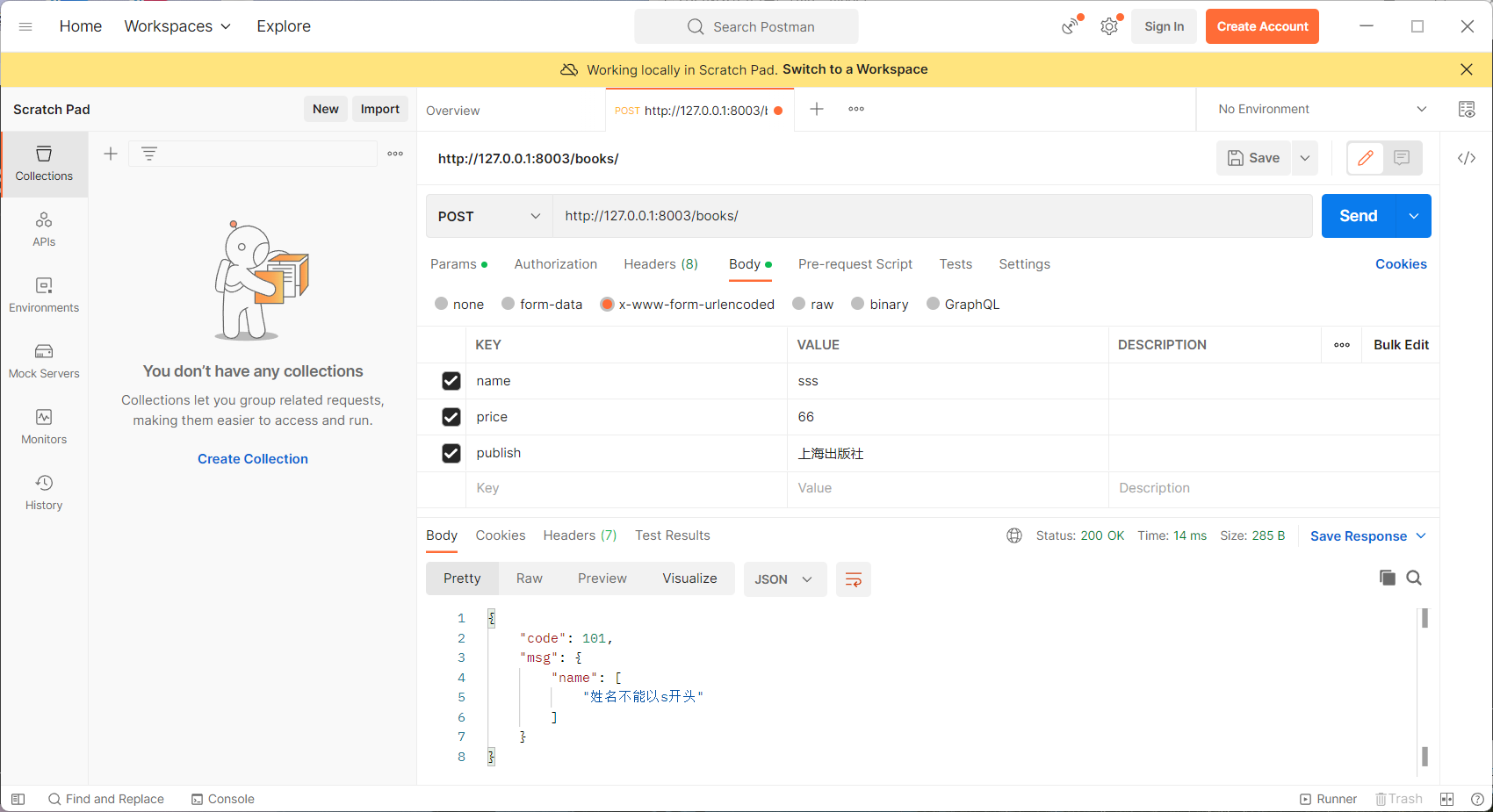
def validate_name(self,name):
"""
相当于局部钩子,校验某一个字段
"""
if name.startswith('s'):
raise ValidationError('姓名不能以s开头')
else:
return name
def validate(self,attrs):
"""
相当于全局钩子
"""
# print(attrs) OrderedDict([('name', '孔乙己'), ('price', '66'), ('publish', '上海出版社')])
if attrs.get('name') == attrs.get('publish'):
# 假设校验条件是书名和出版社名不能一致
raise ValidationError('书名不能和出版社名一致')
else:
return attrs
drf-序列化器、反序列化、反序列化校验的更多相关文章
- drf序列化器与反序列化
什么是序列化与反序列化 """ 序列化:对象转换为字符串用于传输 反序列化:字符串转换为对象用于使用 """ drf序列化与反序列化 &qu ...
- DRF框架之Serializer序列化器的反序列化操作
昨天,我们完成了Serializer序列化器的反序列化操作,那么今天我们就来学习Serializer序列化器的最后一点知识,反序列化操作. 首先,我们定要明确什么是反序列化操作? 反序列化操作:JOS ...
- drf序列化器的实例
应用目录结构: views.py from django.shortcuts import render # Create your views here. from django.views imp ...
- DRF 序列化器-Serializer (2)
作用 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 完成数据校验功能 3. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器 ...
- DRF序列化器的使用
序列化器的使用 序列化器的使用分两个阶段: 在客户端请求时,使用序列化器可以完成对数据的反序列化. 在服务器响应时,使用序列化器可以完成对数据的序列化. 序列化的基本使用 使用的还是上一篇博文中使用的 ...
- DRF序列化器
序列化器-Serializer 作用: 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 反序列化,把客户端发送过来的数据,经过request以后变成字典 ...
- serializers 序列化器里面进行 校验等
一.第一版(一般不用) # 声明序列化器from rest_framework import serializersfrom djangoDome.models import Book class P ...
- drf序列化器serializers.SerializerMethodField()的用法
问题描述: 为什么DRF中有时候返回的json中图片是带域名的,有时候是不带域名的呢? 解析: 带域名的结果是在view中对模型类序列化的,DRF在序列化图片的时候 会检查上下文有没有request, ...
- 对drf序列化器的理解
序列化: 将对象的状态信息转换为可以存储或传输的形式的过程.(百度定义) 对应到drf中,序列化即把模型对象转换为字典形式, 再返回给前端,主要用于输出 反序列化: 把其他格式转化为程序中的格式. 对 ...
- 关于定义序列化器时,read_only和write_only有什么作用
关于序列化和反序列化 在谈论前,先说一下序列化和反序列化,这两个概念最初是在学习json的时候提出来的,回头来看,其实可以用最初的理解就可以了 序列化就是将对象转化方便传输和存储字节序列,例如js ...
随机推荐
- c#入参使用引用类型为啥要加ref?
摘一段来自官网的说明 :方法的参数列表中使用 ref 关键字时,它指示参数按引用传递,而非按值传递. ref 关键字让形参成为实参的别名,这必须是变量. 换而言之,对形参执行的任何操作都是对实参执行的 ...
- django启动报错:DisallowedHost at /
学习django第一天,第一次启动服务就报错,报错内容如下: DisallowedHost at / Invalid HTTP_HOST header: '192.168.116.22:8000'. ...
- Crony 一个基于Go语言实现的分布式定时任务管理平台
crony - 分布式定时任务管理平台 1. 基本介绍 1.1 项目背景 项目中存在许多定时任务,很多代码写法都是采取见缝插针式的写法或者直接丢到task服务里面写,存在以下问题 服务多实例时执行定时 ...
- HSSFSheet XSSFWorkbook SXSSF Java读取Excel数据
HSSF是POI工程对Excel 97(-2007)文件操作的纯Java实现 XSSF是POI工程对Excel 2007 OOXML (.xlsx)文件操作的纯Java实现 SXSSF通过一个滑动窗口 ...
- python-函数的参数与返回值
Python函数 4.1.函数初识 在编写程序的过程中,有某一功能代码块出现多次,但是为了提高编写的效率以及代码的重用,所以把具有独立功能的代码块组织为一个小模块,这就是函数 就是一系列Python语 ...
- 使用Supervisor监控mysql
Supervisor安装教程参考:https://www.cnblogs.com/brad93/p/16639953.html mysql安装教程参考:https://www.cnblogs.com/ ...
- SUPERVISOR监控tomcat配置文件
Supervisor安装教程参考:https://www.cnblogs.com/brad93/p/16639953.html tomcat安装教程参考:https://www.cnblogs.com ...
- 9V,12V输入充3.7V单节锂电池电路和芯片
锂电池充电管理电路中,普遍常用使用最多的的如PW4054这种的线性降压充电管理芯片,特点就是外围极简洁,但是只能支持USB口的输入5V了.当然也有稍微高点的PW4065,输入电压范围是4.7V-8V的 ...
- 【openEuler系列】部署文件共享服务Samba
个人名片: 对人间的热爱与歌颂,可抵岁月冗长 Github:念舒_C.ying CSDN主页️:念舒_C.ying 个人博客 :念舒_C.ying 目录 1 配置环境 2 配置软件安装源 3 安装文 ...
- js修改数组中的属性名
将数组 [{id:"1",name:"AAA"}] 修改为 ===> [{id:"1",text:"AAA",va ...