python网络爬虫笔记(三)
一、切片和迭代
1、列表生成式
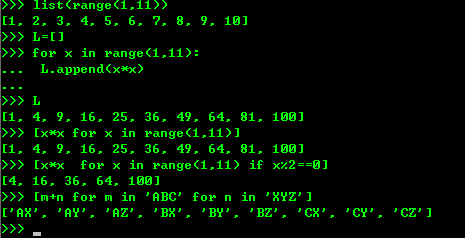
2、生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate
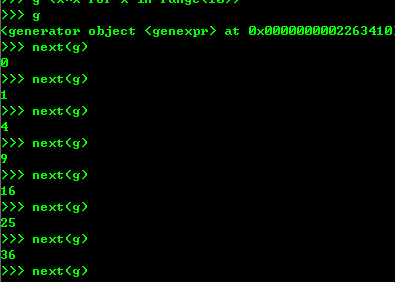
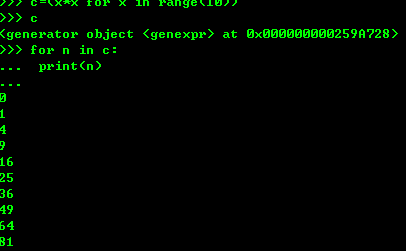
二、iteration 循环
1、凡是作用于for循环的对象都是Iterable的类型; 凡是作用于next()函数的对象都是Iteratior类型,表示一个惰性计算的序列; 集合数据类型list dict str 是iterable 但不是Iteratior对象。python d的for循环就是不断地调用next() 函数实现。
这里要说明的一点就是 list dict str 虽然不是Iterator 但是是Iterable 把 他们变成Iterator可以使用iter() 函数
2、函数式编程和函数编程 不是同一回事。 functional programming 其思想更接近于数学的思想计算,高阶函数 Higher-orderfunction
由于'score'没有被放到__slots__中,所以不能绑定score属性,试图绑定score将得到AttributeError的错误。
使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:

3、python内置的装饰器@property 负责将一个方法编程属性的调用
4、python函数内建了map()和reduce()函数,
map()函数接受两个参数 ,一个是函数一个是Iterable ,map将传入的函数依次作用到序列的每个元素,并并把结果作为新的Iterabor返回
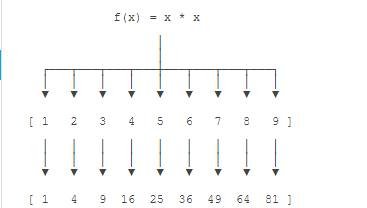
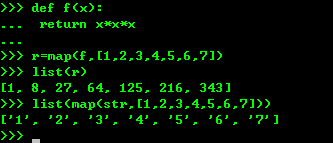
reduce()函数,reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,
Python内建的filter()函数用于过滤序列。
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
python网络爬虫笔记(三)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- python网络爬虫(三)requests库的13个控制访问参数及简单案例
酱酱~小编又来啦~
- [Python]网络爬虫(三):异常的处理和HTTP状态码的分类
先来说一说HTTP的异常处理问题. 当urlopen不能够处理一个response时,产生urlError. 不过通常的Python APIs异常如ValueError,TypeError等也会同时产 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python网络爬虫实战(三)照片定位与B站弹幕
之前两篇已经说完了如何爬取网页以及如何解析其中的数据,那么今天我们就可以开始第一次实战了. 这篇实战包含两个内容. * 利用爬虫调用Api来解析照片的拍摄位置 * 利用爬虫爬取Bilibili视频中的 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
随机推荐
- js对象数组去重
<script> var array = [{ greeting: "Hello", nickName: "Aziz" }, { greeting: ...
- whatis命令,一个非常有用的命令
比如我不知道yum的配置文件yum.conf怎么用,就可以whatis yum.conf,
- centos 6.8下载地址
centos6.8校验码查询网站:https://wiki.centos.org/zh-tw/Manuals/ReleaseNotes/CentOS6.8 CentOS 6.8 64位DVD 种子下载 ...
- Maven配置 和创建一个Maven项目
Maven的好处: maven的两大核心: **依赖管理:对jar包管理过程 **项目构建:项目在编码完成后,对项目进行编译.测试.打包.部署等一系列的操作都通过命令来实现 maven项目的生命周期( ...
- IDA7.0安装keypatch和findcrypt-yara插件
IDA7.0安装keypatch和findcrypt-yara插件 谢天谢地终于装上了,赶紧把方法写一下.找了半天网上的安装方法又繁琐有坑人,偏偏这个插件利用keystone对版本要求很高. Keyp ...
- sublime text 3 左侧目录树中文文件夹显示方框问题解决
0 - 解决方法 打开Preferences->Settings 在弹出的Settings对话框中,加入"dpi_scale": 1.0 重新启动sublime text 3 ...
- RabbitMQ简单应用の主题模式(topic)
Topic exchange(主题转发器) 发送给主题转发器的消息不能是任意设置的选择键,必须是用小数点隔开的一系列的标识符.这些标识符可以是随意,但是通常跟消息的某些特性相关联.一些合法的路由选择键 ...
- Curator实现分布式锁
分布式锁的应用 分布式锁服务宕机, ZooKeeper 一般是以集群部署, 如果出现 ZooKeeper 宕机, 那么只要当前正常的服务器超过集群的半数, 依然可以正常提供服务 持有锁资源服务器宕机, ...
- 连接字符串配置在App.config中
<?xml version="1.0" encoding="utf-8"?> <configuration> <connectio ...
- java知识点5
扩展篇 云计算 IaaS.SaaS.PaaS.虚拟化技术.openstack.Serverlsess 搜索引擎 Solr.Lucene.Nutch.Elasticsearch 权限管理 Shiro 区 ...