Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页
下载下面这个链接的销售数据
https://item.jd.com/6733026.html#comment
1、 翻页的时候,谷歌F12的Network页签可以看到下面的请求。(这里的翻页指商品评价中1、2、3页等)
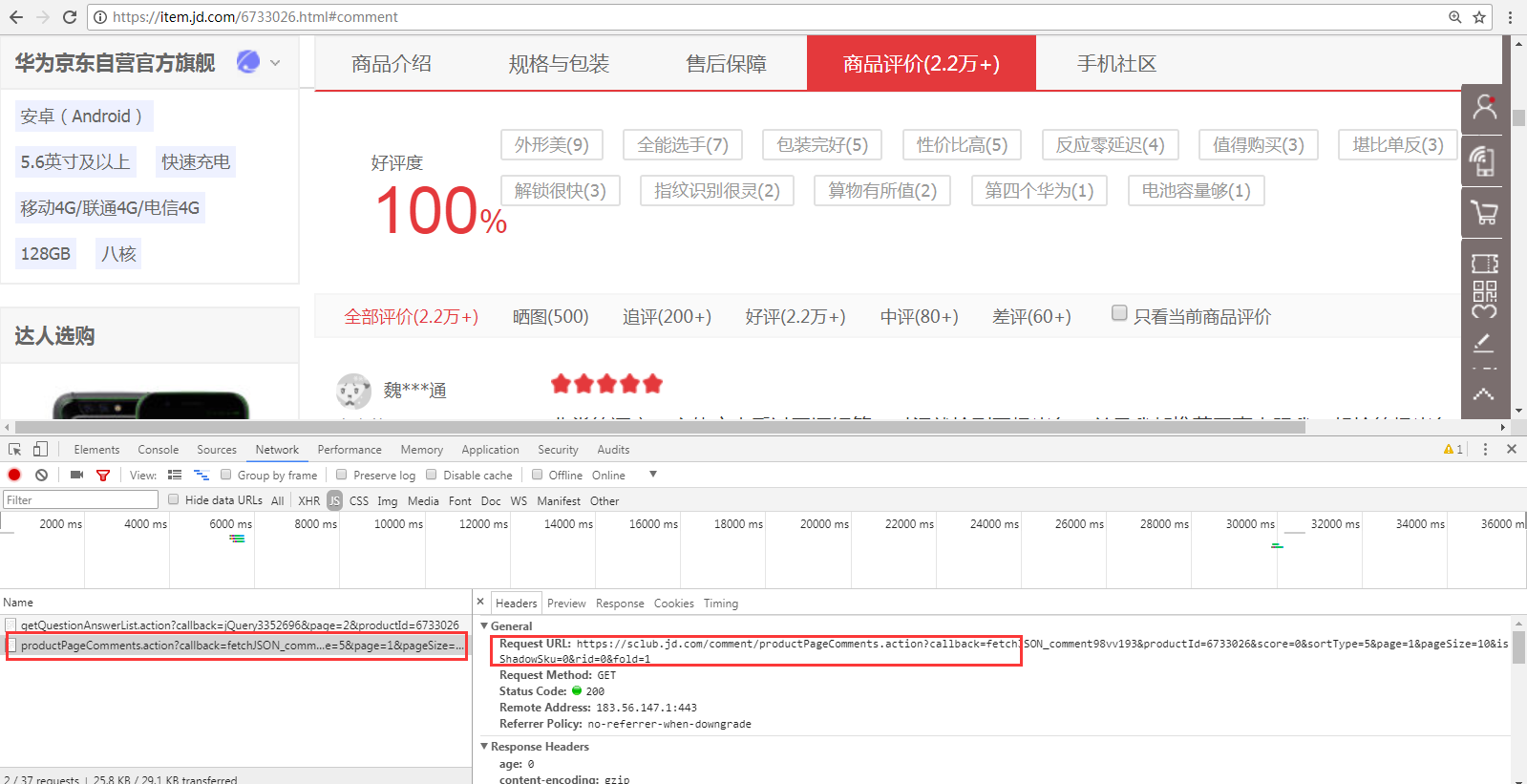
从Preview页签可以看出,这个请求是获取评论信息的
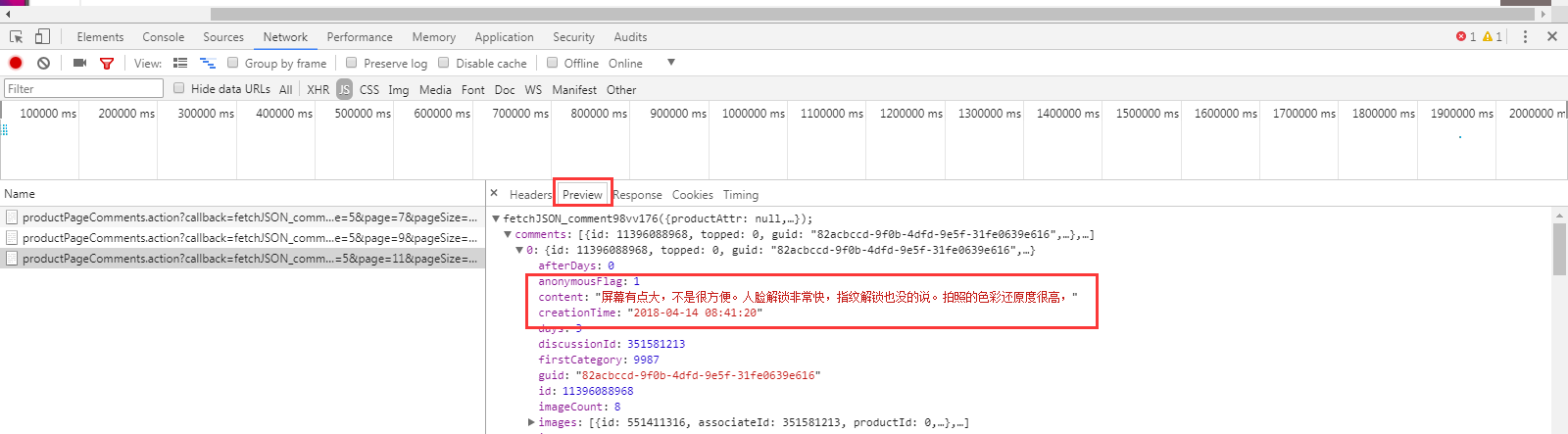
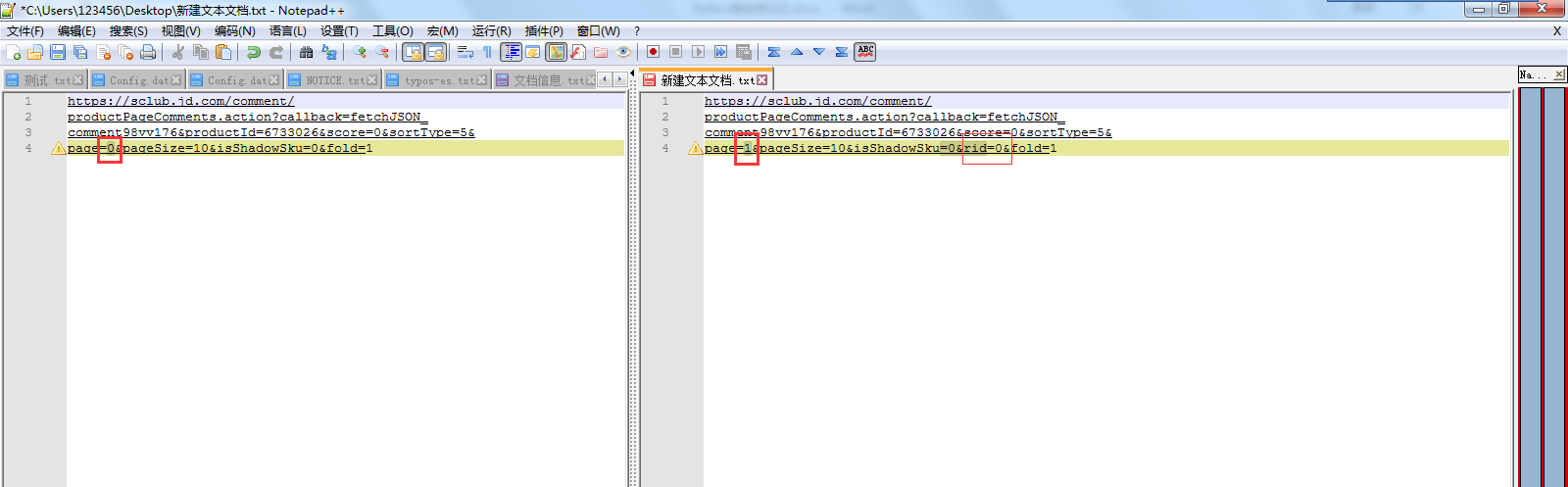
2、 对比第一页、第二页、第三页…请求URL的区别
可以发现 page=0、page=1,0和1指的应该是页数。
第一页的 request url:没有这个rid=0& 。 第二、三页…的request url:多了这个rid=0&
除了上面这2个地方,其他内容都是一样的。
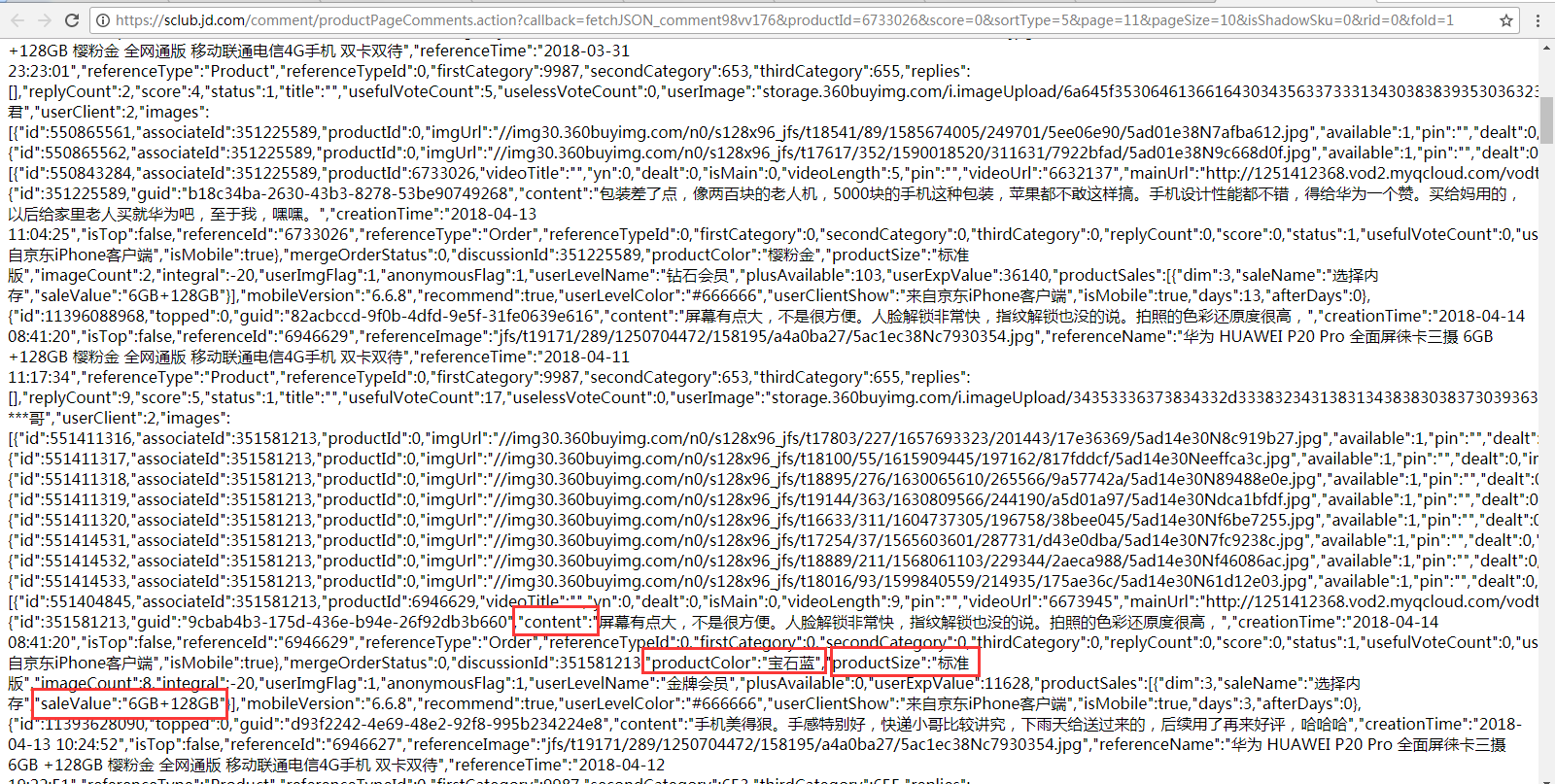
3、 直接在浏览器输入 复制出来的request url,可以看到评论、颜色、版本、内存信息,代码将根据这些信息来写正则表达式进行匹配。
(二) 实现代码
delayed.py的代码和我前面发的是一样的(Python网络爬虫笔记(二)),不限速的话把和这个模块相关的代码删除就行了
import urllib.request as ure
import urllib.parse
import openpyxl
import re
import os
from delayed import WaitFor
def download(url,user_agent='FireDrich',num=2,proxy=None):
print('下载:'+url)
#设置用户代理
headers = {'user_agent':user_agent}
request = ure.Request(url,headers=headers)
#支持代理
opener = ure.build_opener()
if proxy:
proxy_params = {urllib.parse.urlparse(url).scheme: proxy}
opener.add_handler(ure.ProxyHandler(proxy_params))
try:
#下载网页
# html = ure.urlopen(request).read()
html = opener.open(request).read()
except ure.URLError as e:
print('下载失败'+e.reason)
html=None
if num>0:
#遇到5XX错误时,递归调用自身重试下载,最多重复2次
if hasattr(e,'code') and 500<=e.code<600:
return download(url,num=num-1)
return html
def writeXls(sale_list):
#如果Excel不存在,创建Excel,否则直接打开已经存在文档
if 'P20销售情况.xlsx' not in os.listdir():
wb =openpyxl.Workbook()
else:
wb =openpyxl.load_workbook('P20销售情况.xlsx')
sheet = wb['Sheet']
sheet['A1'] = '颜色'
sheet['B1'] = '版本'
sheet['C1'] = '内存'
sheet['D1'] = '评论'
sheet['E1'] = '评论时间'
x = 2
#迭代所有销售信息(列表)
for s in sale_list:
#获取颜色等信息
content = s[0]
creationTime = s[1]
productColor = s[2]
productSize = s[3]
saleValue = s[4]
# 将颜色等信息添加到Excel
sheet['A' + str(x)] = productColor
sheet['B' + str(x)] = productSize
sheet['C' + str(x)] = saleValue
sheet['D' + str(x)] = content
sheet['E' + str(x)] = creationTime
x += 1
wb.save('P20销售情况.xlsx') page = 0
allSale =[]
waitFor = WaitFor(2)
#预编译匹配颜色、版本、内存等信息的正则表达式
regex = re.compile('"content":"(.*?)","creationTime":"(.*?)".*?"productColor":"(.*?)","productSize":"(.*?)".*?"saleValue":"(.*?)"')
#这里只下载20页数据,可以设置大一些(因为就算没评论信息,也能下载到一些标签信息等,所以可以if 正则没匹配的话就结束循环,当然,下面没处理这个)
while page<20:
if page==0:
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1'
else:
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&rid=0&fold=1'
waitFor.wait(url)
html = download(url)
html = html.decode('GBK')
#以列表形式返回颜色、版本、内存等信息
sale = regex.findall(html)
#将颜色、版本、内存等信息添加到allSale中(扩展allSale列表)
allSale.extend(sale)
page += 1 writeXls(allSale)
(三) 数据分析
1、 下载后的数据如下图所示。

2、 生成图表。
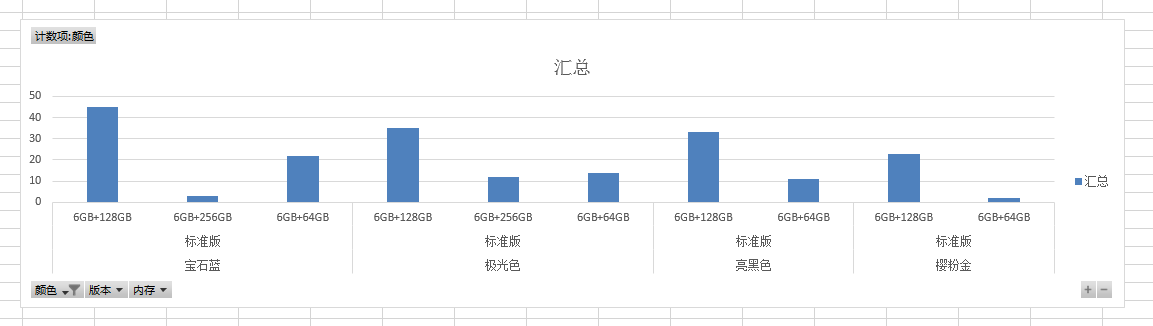
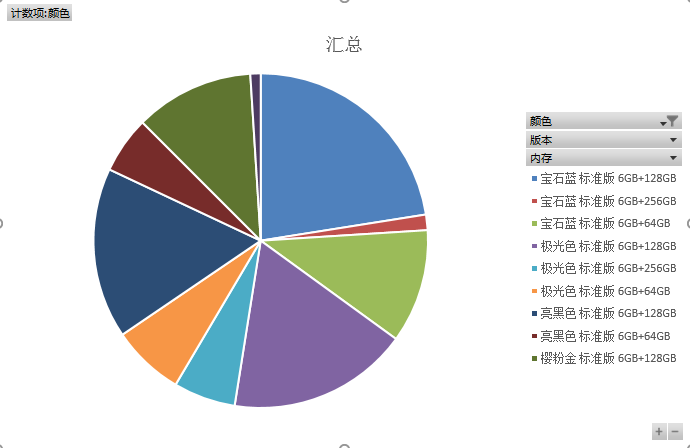
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=3ff1njli6hwk0
Python网络爬虫笔记(五):下载、分析京东P20销售数据的更多相关文章
- Python网络爬虫实战(五)批量下载B站收藏夹视频
我们除了爬取文本信息,有的时候还需要爬媒体信息,比如视频图片音乐等.就拿B站来说,我的收藏夹内的视频可能随时会失效,所以把它们下载到本地是非常保险的一件事. 对于这种大量列表型的数据,可以猜测B站收藏 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(五)
一.python的类对象的继承 1.所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__, ...
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8925978 前面说到了urllib2的简单入门,下面整理了一部分urllib2的使用 ...
- [Python]网络爬虫(五):urllib2的使用细节与抓站技巧(转)
1.Proxy 的设置 urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy. 如果想在程序中明确控制 Proxy 而不受环境变量的影响,可以使用代理. 新建test ...
- python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块 urllib2最简单的就是使用urllie2.urlopen函数使用如下 urllib2.urlopen(url[,data[,timeo ...
- python网络爬虫笔记(八)
一.pthon 序列化json格式 1.将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-li ...
随机推荐
- 【django之权限组件】
一.需求分析 RBAC(Role-Based Access Control,基于角色的访问控制),就是用户通过角色与权限进行关联.简单地说,一个用户拥有若干角色,一个角色拥有若干权限.这样,就构造成& ...
- 听翁恺老师mooc笔记(16)--程序设计与C语言
问题1:计算机遍布生活的各个方面,若你需要一个功能可以下载APP,我们需要的大部分功能都可以找到对应的APP,如果没有可以自己写一个软件,但是很少人需要这么做,那么我们为什么学习计算机编程语言? 学习 ...
- C语言第二次作业---分支结构
一.PTA实验作业 题目1:计算分段函数[2] 1.实验代码 double x,y; scanf("%lf",&x); if(x>=0){ y=sqrt(x); } ...
- 20162327WJH第五周作业
学号 20162327 <程序设计与数据结构>第5周学习总结 教材学习内容总结 1.java是一种面向对象的语言.面向对象是一种编程方法.更是一种思维方式. 2.面向对象编程的终极目标是消 ...
- 如何进行服务器Linux系统下的ext文件系统修复
一.故障描述 服务器是dell 730系列服务器,存储阵列是MD3200系列存储5T的Lun,操作系统是Linux centos 7,文件系统类型是EXT4,因意外断电,导致系统不能正常启动,修复之后 ...
- Angular.js 1++快速上手
AngularJS诞生于2009年,由Misko Hevery 等人创建,后为Goole所收购.是一款优秀的前端JS框架.AngularJS有着诸多特性,最为核心的是:MVC,撗块化,自动化双向数据绑 ...
- MyBatis 中使用数据库查询别名进行映射
方法1 XXMapper.xml <mapper namespace="com.hfepc.dao.andon.AndonExceptionKanbanVOMapper" & ...
- mui对话框事件
mui.confirm('生成成功,是否跳转到订单页面?','',['跳转','取消'],function(e){ if(e.index==0){ //点击跳转 }else if(e.index==1 ...
- HTML事件处理程序
事件处理程序中的代码执行时,有权访问全局作用域中任何代码. //为按钮btn_event添加了两个个事件处理程序,而且该事件会在冒泡阶段触发(最后一个参数是false). var btn_event ...
- python 内置函数之lambda-filter-reduce-apply-map
(1)lambda lambda是Python中一个很有用的语法,它允许你快速定义单行最小函数.类似于C语言中的宏,可以用在任何需要函数的地方. 基本语法如下: 函数名 = lambda args1, ...