BFS和DFS算法
昨晚刚昨晚华为笔试题,用到了BFS和DFS,可惜自己学艺不精,忘记了实现原理,现在借用大佬写的内容给自己做个提高
转自:https://www.jianshu.com/p/70952b51f0c8
图是一种灵活的数据结构,一般作为一种模型用来定义对象之间的关系或联系。对象由顶点(V)表示,而对象之间的关系或者关联则通过图的边(E)来表示。
图可以分为有向图和无向图,一般用G=(V,E)来表示图。经常用邻接矩阵或者邻接表来描述一副图。
在图的基本算法中,最初需要接触的就是图的遍历算法,根据访问节点的顺序,可分为广度优先搜索(BFS)和深度优先搜索(DFS)。
广度优先搜索(BFS)
广度优先搜索在进一步遍历图中顶点之前,先访问当前顶点的所有邻接结点。
a .首先选择一个顶点作为起始结点,并将其染成灰色,其余结点为白色。
b. 将起始结点放入队列中。
c. 从队列首部选出一个顶点,并找出所有与之邻接的结点,将找到的邻接结点放入队列尾部,将已访问过结点涂成黑色,没访问过的结点是白色。如果顶点的颜色是灰色,表示已经发现并且放入了队列,如果顶点的颜色是白色,表示还没有发现
d. 按照同样的方法处理队列中的下一个结点。
基本就是出队的顶点变成黑色,在队列里的是灰色,还没入队的是白色。
用一副图来表达这个流程如下:

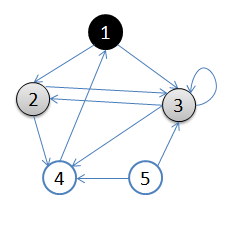
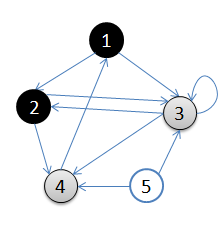


- 初始状态,从顶点1开始,队列={1}
- 访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}
- 访问2的邻接结点,2出队,4入队,队列={3,4}
- 访问3的邻接结点,3出队,队列={4}
- 访问4的邻接结点,4出队,队列={ 空}
结点5对于1来说不可达。
上面的图可以通过如下邻接矩阵表示:
int maze[5][5] = {
{ 0, 1, 1, 0, 0 },
{ 0, 0, 1, 1, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 0, 0, 0, 0 },
{ 0, 0, 1, 1, 0 }
};
BFS核心代码如下:
#include <iostream>
#include <queue>
#define N 5
using namespace std;
int maze[N][N] = {
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , }
};
int visited[N + ] = { , };
void BFS(int start)
{
queue<int> Q;
Q.push(start);
visited[start] = ;
while (!Q.empty())
{
int front = Q.front();
cout << front << " ";
Q.pop();
for (int i = ; i <= N; i++)
{
if (!visited[i] && maze[front - ][i - ] == )
{
visited[i] = ;
Q.push(i);
}
}
}
}
int main()
{
for (int i = ; i <= N; i++)
{
if (visited[i] == )
continue;
BFS(i);
}
return ;
}
深度优先搜索在搜索过程中访问某个顶点后,需要递归地访问此顶点的所有未访问过的相邻顶点。
初始条件下所有节点为白色,选择一个作为起始顶点,按照如下步骤遍历:
a. 选择起始顶点涂成灰色,表示还未访问
b. 从该顶点的邻接顶点中选择一个,继续这个过程(即再寻找邻接结点的邻接结点),一直深入下去,直到一个顶点没有邻接结点了,涂黑它,表示访问过了
c. 回溯到这个涂黑顶点的上一层顶点,再找这个上一层顶点的其余邻接结点,继续如上操作,如果所有邻接结点往下都访问过了,就把自己涂黑,再回溯到更上一层。
d. 上一层继续做如上操作,知道所有顶点都访问过。
用图可以更清楚的表达这个过程:


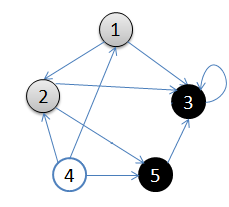
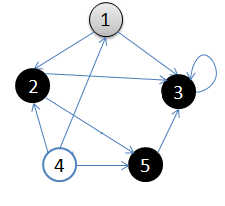
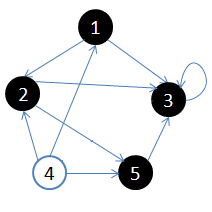

- 初始状态,从顶点1开始
- 依次访问过顶点1,2,3后,终止于顶点3
- 从顶点3回溯到顶点2,继续访问顶点5,并且终止于顶点5
- 从顶点5回溯到顶点2,并且终止于顶点2
- 从顶点2回溯到顶点1,并终止于顶点1
- 从顶点4开始访问,并终止于顶点4
上面的图可以通过如下邻接矩阵表示:
int maze[][] = {
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , }
};
DFS核心代码如下(递归实现):
#include <iostream>
#define N 5
using namespace std;
int maze[N][N] = {
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , }
};
int visited[N + ] = { , };
void DFS(int start)
{
visited[start] = ;
for (int i = ; i <= N; i++)
{
if (!visited[i] && maze[start - ][i - ] == )
DFS(i);
}
cout << start << " ";
}
int main()
{
for (int i = ; i <= N; i++)
{
if (visited[i] == )
continue;
DFS(i);
}
return ;
}
非递归实现如下,借助一个栈:
#include <iostream>
#include <stack>
#define N 5
using namespace std;
int maze[N][N] = {
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , },
{ , , , , }
};
int visited[N + ] = { , };
void DFS(int start)
{
stack<int> s;
s.push(start);
visited[start] = ;
bool is_push = false;
while (!s.empty())
{
is_push = false;
int v = s.top();
for (int i = ; i <= N; i++)
{
if (maze[v - ][i - ] == && !visited[i])
{
visited[i] = ;
s.push(i);
is_push = true;
break;
}
}
if (!is_push)
{
cout << v << " ";
s.pop();
} }
}
int main()
{
for (int i = ; i <= N; i++)
{
if (visited[i] == )
continue;
DFS(i);
}
return ;
}
有的DFS是先访问读取到的结点,等回溯时就不再输出该结点,也是可以的。算法和我上面的区别就是输出点的时机不同,思想还是一样的。DFS在环监测和拓扑排序中都有不错的应用。
BFS和DFS算法的更多相关文章
- 邻接矩阵实现Dijkstra算法以及BFS与DFS算法
//============================================================================ // Name : MatrixUDG.c ...
- 15 图-图的遍历-基于邻接矩阵实现的BFS与DFS算法
算法分析和具体步骤解说直接写在代码注释上了 TvT 没时间了等下还要去洗衣服 就先不赘述了 有不明白的欢迎留言交流!(估计是没人看的了) 直接上代码: #include<stdio.h> ...
- BFS与DFS算法解析
1)前言 和树的遍历类似,图的遍历也是从图中某点出发,然后按照某种方法对图种所有顶点进行访问,且仅访问一次. 但是图的遍历相对树的遍历更为复杂,因为图中任意顶点都能与其他顶点相邻,所以在图的遍历中必须 ...
- BFS/DFS算法介绍与实现(转)
广度优先搜索(Breadth-First-Search)和深度优先搜索(Deep-First-Search)是搜索策略中最经常用到的两种方法,特别常用于图的搜索.其中有很多的算法都用到了这两种思想,比 ...
- 算法录 之 BFS和DFS
说一下BFS和DFS,这是个比较重要的概念,是很多很多算法的基础. 不过在说这个之前需要先说一下图和树,当然这里的图不是自拍的图片了,树也不是能结苹果的树了.这里要说的是图论和数学里面的概念. 以上概 ...
- 算法学习之BFS、DFS入门
算法学习之BFS.DFS入门 0x1 问题描述 迷宫的最短路径 给定一个大小为N*M的迷宫.迷宫由通道和墙壁组成,每一步可以向相邻的上下左右四格的通道移动.请求出从起点到终点所需的最小步数.如果不能到 ...
- 算法基础:BFS和DFS的直观解释
算法基础:BFS和DFS的直观解释 https://cuijiahua.com/blog/2018/01/alogrithm_10.html 一.前言 我们首次接触 BFS 和 DFS 时,应该是在数 ...
- SPFA算法的判负环问题(BFS与DFS实现)
经过笔者的多次实践(失败),在此温馨提示:用SPFA判负环时一定要特别小心! 首先SPFA有BFS和DFS两种实现方式,两者的判负环方式也是不同的. BFS是用一个num数组,num[x] ...
- BFS与DFS常考算法整理
BFS与DFS常考算法整理 Preface BFS(Breath-First Search,广度优先搜索)与DFS(Depth-First Search,深度优先搜索)是两种针对树与图数据结构的遍历或 ...
随机推荐
- 不能用c99的情况下,如何动态定义数组的长度
#include <stdio.h>#include <stdlib.h> int main(int argc, char const *argv[]){ int num ...
- java如何对map进行排序详解(map集合的使用)
今天做统计时需要对X轴的地区按照地区代码(areaCode)进行排序,由于在构建XMLData使用的map来进行数据统计的,所以在统计过程中就需要对map进行排序. 一.简单介绍Map 在讲解Map排 ...
- CSRF攻击详解
CSRF是什么 CSRF(Cross-site request forgery),中文名称:跨站请求伪造,也被称为:one click attack/session riding,缩写为:CSRF/X ...
- Volley源码分析(四)NetWork与ResponseDelivery工作原理
这篇文章主要分析网络请求和结果交付的过程. NetWork工作原理 之前已经说到通过mNetWork.performRequest()方法来得到NetResponse,看一下该方法具体的执行流程,pe ...
- Sqoop学习之路 (一)
一.概述 sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具. 核心的功能有两个: 导入.迁入 导出.迁出 导入数据:MySQL,Oracle 导入数据到 H ...
- shiro实战系列(五)之Authentication(身份验证)
建议学习shiro读读官方文档,虽然不一定读的懂,但是建议要大致浏览,心中有个大概,这样对于学习还是有一定帮助 官网地址:https://shiro.apache.org/ Authenticatio ...
- PHP7.0新特性
http://blog.csdn.net/h330531987/article/details/74364681 反射 闭包 trait 还有数组
- Features + Git + Drush,打造你的Drupal开发与维护标准工作流
还在为如何将本地的开发工作如何部署到生产环境而皱眉头?本文以实战历程教你如何一步步将你的工作成果从开发环境部署到生产环境. 如题所示,需要用到Features, Git, Drush:如果你还不知道他 ...
- 开启Node.js的大门
其实也没什么好说的,简而言之,就是如何配置node.js环境,然后进行开发.博主最近比较堕落,觉得什么事情也没有就不知道想干什么,想融入一些事情又觉得没大神指引,于是自娱自乐开始自己玩node.js, ...
- Android SDK版本号与API Level 的对应关系-转
Android SDK版本号 与 API Level 对应关系 http://developer.android.com/guide/appendix/api-levels.html Android ...