爬虫初窥day3:BeautifulSoup
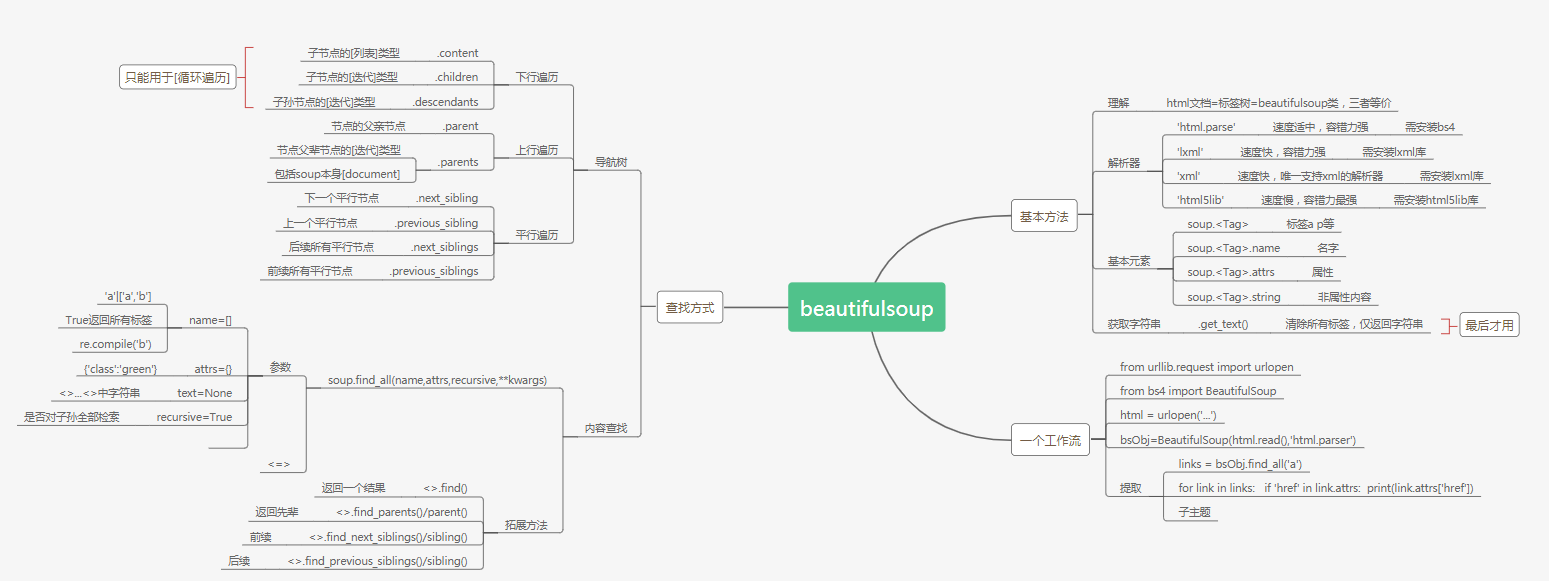
信息提取
1.通过Tag对象的属性和方法
#!/usr/bin/python
# -*- coding: utf- -*-
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen('https://www.cnblogs.com/pcat/p/5398997.html')
soup = BeautifulSoup(html.read().decode('utf-8'),'html.parser')#避免乱码,先utf-8解码 #print()输出第一个匹配项
print(soup)
print(soup.a)
print(soup.a.name)
print(soup.a.attrs)
print(soup.a.string) soup.html.get_text()输出字符串,原文排版
2.通过标签树对象的find_all()方法
aS = soup.find_all('a')
for i in aS:
print(i)
#print(i.name)
#print(i.attrs)
#print(i.string)
#find_all带条件(name,attrs,string,text,recursive,可多条件匹配)
hrefs = soup.find_all(href=re.compile('pcat$'))#以pcat结尾的链接
for i in hrefs:
print(i)
#对css类名属性class进行搜索时,为避免与python保留字冲突,需用class_
a = soup.find_all(class_ = 'postDesc')
print(a)
#补充1.text匹配非属性内容。.["a","b"]的形式,表示匹配多个值
3.通过标签树对象的find()方法
#find返回一个标签节点,find_all返回多值列表
#find
e1 =soup.find('head').find('title')#在标签名为head的tag中查找title标签
print(e1)
4.通过CSS选择器
#标签名
soup.select('p')#搜索所有标签名为p的标签
soup.select('p a')#搜索所有p标签的子孙节点中标签名为a的标签。即下N层
soup.select('p > a')#搜索所有p标签的直接子节点中标签名为a的标签。即下一层
#类名
soup.select('.blogStats ')#所有类名为blogStats的标签
soup.select('.blogStats span')#所有类名为blogStats且子孙节点中标签名为span的标签
soup.select('a.menu')#标签名为a并且类名为menu的标签
e1=soup.select('a.menu')#标签名为a并且类名为menu的标签
for i in e1:
print(i['href'])
#id
soup.select('#stats_post_count')#所有id为xxx的标签
soup.select('#navList #blog_nav_sitehome')#所有id为xxx且其子孙节点id为xxx的标签
#属性
soup.select('a[href]')#标签名为a且属性中存在href的所有标签
soup.select('a[href="https://www.cnblogs.com/pcat/"]')#标签名为a且href属性值为http://...的所有标签
soup.select('a[href^="http"]')#标签名为a且href属性以http开头的标签
soup.select('a[href$="http"]')#标签名为a且href属性以pcat结尾的标签
soup.select('a[href*="cnblogs"]')#标签名为a且href属性包含example的标签
#标签名/类名/id/属性 空格[ ] 右符号'>' 相互搭配
遍历
1.下行遍历
| <tag>.contents | 以列表形式返回Tag的所有子节点 |
| <tag>.children | 以迭代形式返回Tag的所有子节点 |
| <tag>.descendants | 以迭代形式返回Tag的所有子孙节点 |
| <tag>.strings | 以迭代形式返回Tag及其所有子孙节点的非属性字符串 |
| <tag>.stripped_strings | 以迭代形式返回Tag去除空白字符后的非属性字符串 |
\c
#contents
e1=soup.ul.contents
print(type(e1))
print(len(e1))
#children
e1=soup.ul.children
for i in e1:
print(i)
#descendants
e1=soup.ul.descendants
for i in e1:
print(i)
#strings
e1=soup.ul.strings
for i in e1:
print(i)
#stripped_strings
e1=soup.ul.stripped_strings
for i in e1:
print(i)
\c
2.上行遍历
| parent | 以列表形式返回tag的所有父亲节点 |
| parents | 以迭代形式返回tag的所有父辈节点 |
\c
3.水平遍历
| next_sibling | 按文档顺序,返回Tag的下一个相邻兄弟节点 |
| previous_sibling | 按文档顺序,返回Tag的上一个相邻兄弟节点 |
| next_siblings | 按文档顺序,返回Tag的后续兄弟节点 |
| previous_siblings | 按文档顺序,返回Tag的前续兄弟节点 |
爬虫初窥day3:BeautifulSoup的更多相关文章
- 爬虫初窥day4:requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 ...
- 爬虫初窥day2:正则
正则在线测试 http://tool.oschina.net/regex https://www.regexpal.com/ http://tool.chinaz.com/regex exp1:筛选所 ...
- 爬虫初窥day1:urllib
模拟“豆瓣”网站的用户登录 # coding:utf-8 import urllib url = 'https://www.douban.com/' data = urllib.parse.urlen ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 1.4 文档 01 初窥 Scrapy
初窥 Scrapy Scrapy 是用于抓取网站并提取结构化数据的应用程序框架,其应用非常广泛,如数据挖掘,信息处理或历史存档. 尽管 Scrapy 最初设计用于网络数据采集(web scraping ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- R语言爬虫初尝试-基于RVEST包学习
注意:这文章是2月份写的,拉勾网早改版了,代码已经失效了,大家意思意思就好,主要看代码的使用方法吧.. 最近一直在用且有维护的另一个爬虫是KINDLE 特价书爬虫,blog地址见此: http://w ...
随机推荐
- 04_web基础(四)之servlet详解
16.17.18.servlet生命周期 javax.servlet.Servlet接口方法:public String getServletInfo():获取Servlet相关信息(作者,版权,版本 ...
- Photoshop Keynote
[Photoshop Keynote] 1.Tab:隐藏.显示所有面板. 2.Sihft+Tab:隐藏.显示右侧面板. 3.F:全屏切换. 4.选择并遮住: 参考:http://www.51shipi ...
- ORA-30926: 无法在源表中获得一组稳定的行ORA-06512: 在 "STG.FP_MO_SPLIT", line 1562 临时
- Oracle常用查看表结构命令(转)
转自:http://www.cnblogs.com/qingsong-do/archive/2011/11/29/2267244.html 获取表: select table_name from us ...
- Redis集群部署及命令
一.简介 redis集群是一个无中心的分布式Redis存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用.可扩展等问题. redis集群提供了以下两个好处: 将数据自动切分(split) ...
- tf.layers.dense()
tf.layers.dense用法 2018年05月30日 19:09:58 o0haidee0o 阅读数:20426 dense:全连接层 相当于添加一个层,即初学的add_layer()函数 ...
- HDU-1074.DoingHomework(撞鸭dp二进制压缩版)
之前做过一道二进制压缩的题目,感觉也不是很难吧,但是由于见少识窄,这道题一看就知道是撞鸭dp,却总是无从下手....最后看了一眼博客,才顿悟,本次做这道题的作用知识让自己更多的认识二进制压缩,并无其它 ...
- ES5之函数的间接调用 ( call、apply )、绑定 ( bind )
call().apply()的第一个实参是函数调用的上下文,在函数体内通过this来获得对它的引用. call()将实参用逗号分隔:apply ()将实参放入数组.类数组对象中. function h ...
- VM虚拟机 安装linux系统
首先需要下载VMware10 和CentOS-6.4,我这边提供了百度网盘,可供下载链接:https://pan.baidu.com/s/1vrJUK167xnB2JInLH890fw 密码:r4jj ...
- 关于django的操作(四)
1,关于form组件的写法 定义错误信息使用error_messages,自定义字段名称用lebal,自定义样式需要使用widget,比方说这个是一个什么样子的输入框,attr用于输入输入框的属性等 ...