Flink Task 并行度
并行的数据流
Flink程序由多个任务(转换/运算符,数据源和接收器)组成,Flink中的程序本质上是并行和分布式的。
在执行期间,流具有一个或多个流分区,并且每个operator具有一个或多个operator*子任务*。
operator子任务彼此独立,并且可以在不同的线程中执行,这些线程又可能在不同的机器或容器上执行。
operator子任务的数量是该特定operator的并行度。
流的并行度始终是其生成operator的并行度。
同一程序的不同operator可能具有不同的并行级别。
示意图:
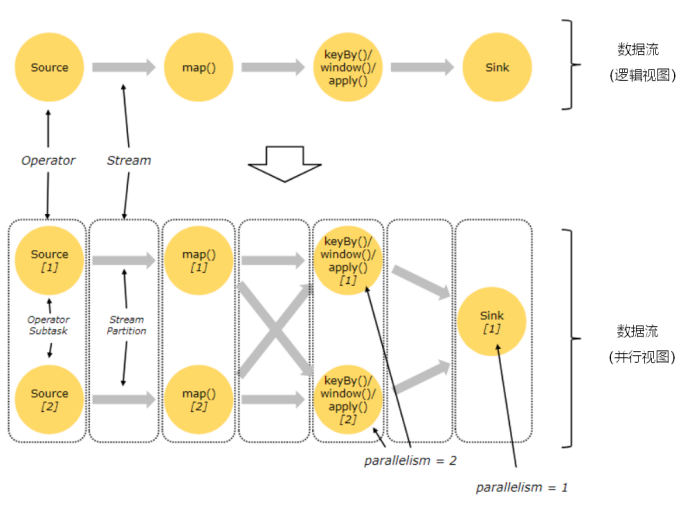
流可以以一对一(或重新分配)模式或以重新分发模式在两个运营商之间传输数据:
- 一对一流
- 如上图中的Source和map运算符之间
- 保留元素的分区和排序
- 这意味着map运算符的subtask [1] 将看到与Source运算符的subtask [1]生成的顺序相同的元素
- 重新分配流
- 在上面的map和keyBy / window之间,以及 keyBy / window和Sink之间重新分配流
- 每个运算符子任务将数据发送到不同的目标子任务, 具体取决于所选的转换。
- 图中是根据 keyby算子进行数据的重新分布。
- 一对一流
任务并行度设置
算子级别
可以通过调用其setParallelism()方法来定义单个运算符,数据源或数据接收器的并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
// 设置并行度
.sum(1).setParallelism(3);
执行环境级别
执行环境级别的并行度是本次任务中所有的操作符,数据源和数据接收器的并行度。
可以通过显式的配置运算符并行度来覆盖执行环境并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3);
客户端级别
- 在向Flink提交作业时,可以在客户端设置并行度,通过使用指定的parallelism参数-p。
- 例如:
- ./bin/flink run -p 10 ../examples/WordCount-java.jar
系统级别
- 通过设置flink_home/conf/flink-conf.yaml 配置文件中的parallelism.default配置项来定义默认并行度。
Flink Task 并行度的更多相关文章
- Flink task之间的数据交换
Flink中的数据交换是围绕着下面的原则设计的: 1.数据交换的控制流(即,为了启动交换而传递的消息)是由接收者发起的,就像原始的MapReduce一样. 2.用于数据交换的数据流,即通过电缆的实际数 ...
- flink solt,并行度
转自:https://www.jianshu.com/p/3598f23031e6 简介 Flink运行时主要角色有两个:JobManager和TaskManager,无论是standalone集群, ...
- spark内核篇-task数与并行度
每一个 spark job 根据 shuffle 划分 stage,每个 stage 形成一个或者多个 taskSet,了解了每个 stage 需要运行多少个 task,有助于我们优化 spark 运 ...
- Flink并行度
并行执行 本节介绍如何在Flink中配置程序的并行执行.FLink程序由多个任务(转换/操作符.数据源和sinks)组成.任务被分成多个并行实例来执行,每个并行实例处理任务的输入数据的子集.任务的并行 ...
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- Flink 靠什么征服饿了么工程师?
Flink 靠什么征服饿了么工程师? 2018-08-13 易伟平 阿里妹导读:本文将为大家展示饿了么大数据平台在实时计算方面所做的工作,以及计算引擎的演变之路,你可以借此了解Storm.Spa ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-split & select(拆分流)
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink on YARN时,如何确定TaskManager数
转自: https://www.jianshu.com/p/5b670d524fa5 答案写在最前面:Job的最大并行度除以每个TaskManager分配的任务槽数. 问题 在Flink 1.5 Re ...
随机推荐
- (十四)登陆注册 逻辑二 前端globalData的使用 和 Storage
我们在点击登录的时候 成功之后跳转到home 一 在全局的app.js里会有一个 globalData 因为还有其他页面也要使用 共有的数据 所有用到 gl ...
- c++中的全排列
next_permutation函数 组合数学中经常用到排列,这里介绍一个计算序列全排列的函数:next_permutation(start,end),和prev_permutation(start, ...
- HDU-1312题解(DFS)
HDU-1312-DFS Written by Void-Walker 2020-02-01 09:09:25 1.题目传送门:http://acm.hdu.edu.cn/showproblem ...
- Link Analysis_2_Application
US Cities Distribution Network 1.1 Task Description Nodes: Cities with attributes (1) location, (2) ...
- 手写MQ框架(四)-使用netty改造梳理
一.背景 书接上文手写MQ框架(三)-客户端实现,前面通过web的形式实现了mq的服务端和客户端,现在计划使用netty来改造一下.前段时间学习了一下netty的使用(https://www.w3cs ...
- php:数据库封装类
<?phpclass DBDA{ public $host="localhost"; public $uid="root"; publi ...
- DataReader和DataAdapter的区别
SqlDataReader是一个向前的指针,本身并不包含数据,调用一次Read()方法它就向前到下一条记录,一个SqlDataReader必须单独占用一个打开的数据库连接. 在使用 SqlDataRe ...
- 洛谷 P4287 [SHOI2011]双倍回文题解
前言 用了一种很奇怪的方法来解,即二分判断回文,再进行某些奇怪的优化.因为这个方法很奇怪,所以希望如果有问题能够 hack 一下. 题解 我们发现,这题中要求的是字符串 \(SS'SS'\),其中 \ ...
- ttf格式文件
TTF(TrueTypeFont):是一种字库名称.TTF文件:是Apple公司和Microsoft公司共同推出的字体文件格式.要使用的下载的字体文件只要把它(*.ttf)放到C:\WINDOWS\F ...
- SciPy 插值
章节 SciPy 介绍 SciPy 安装 SciPy 基础功能 SciPy 特殊函数 SciPy k均值聚类 SciPy 常量 SciPy fftpack(傅里叶变换) SciPy 积分 SciPy ...