2019-ICLR-DARTS: Differentiable Architecture Search-论文阅读
DARTS
2019-ICLR-DARTS Differentiable Architecture Search
- Hanxiao Liu、Karen Simonyan、Yiming Yang
- GitHub:2.8k stars
- Citation:557
Motivation
Current NAS method:
- Computationally expensive: 2000/3000 GPU days
- Discrete search space, leads to a large number of architecture evaluations required.
Contribution
- Differentiable NAS method based on gradient decent.
- Both CNN(CV) and RNN(NLP).
- SOTA results on CIFAR-10 and PTB.
- Efficiency: (2000 GPU days VS 4 GPU days)
- Transferable: cifar10 to ImageNet, (PTB to WikiText-2).
Method
Search Space
Search for a cell as the building block of the final architecture.
The learned cell could either be stacked to form a CNN or recursively connected to form a RNN.
A cell is a DAG consisting of an ordered sequence of N nodes.
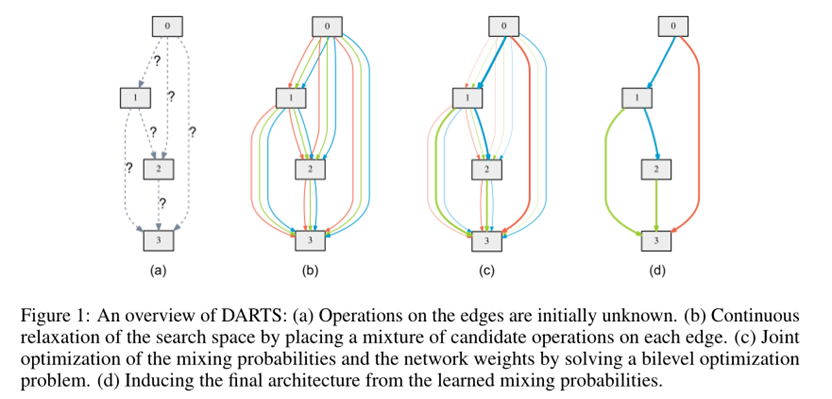
\(\bar{o}^{(i, j)}(x)=\sum_{o \in \mathcal{O}} \frac{\exp \left(\alpha_{o}^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)} o(x)\)
\(x^{(j)}=\sum_{i<j} o^{(i, j)}\left(x^{(i)}\right)\)


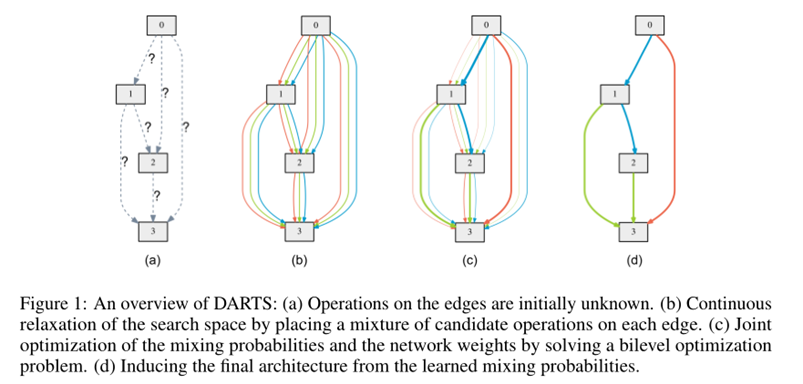
Optimization Target
Our goal is to jointly learn the architecture α and the weights w within all the mixed operations (e.g. weights of the convolution filters).
\(\min _{\alpha} \mathcal{L}_{v a l}\left(w^{*}(\alpha), \alpha\right)\) ......(3)
s.t. \(\quad w^{*}(\alpha)=\operatorname{argmin}_{w} \mathcal{L}_{\text {train}}(w, \alpha)\) .......(4)
The idea is to approximate w∗(α) by adapting w using only a single training step, without solving the inner optimization (equation 4) completely by training until convergence.
\(\nabla_{\alpha} \mathcal{L}_{v a l}\left(w^{*}(\alpha), \alpha\right)\) ......(5)
\(\approx \nabla_{\alpha} \mathcal{L}_{v a l}\left(w-\xi \nabla_{w} \mathcal{L}_{t r a i n}(w, \alpha), \alpha\right)\) ......(6)
- When ξ = 0, the second-order derivative in equation 7 will disappear.
- ξ = 0 as the first-order approximation,
- ξ > 0 as the second-order approximation.






Discrete Arch
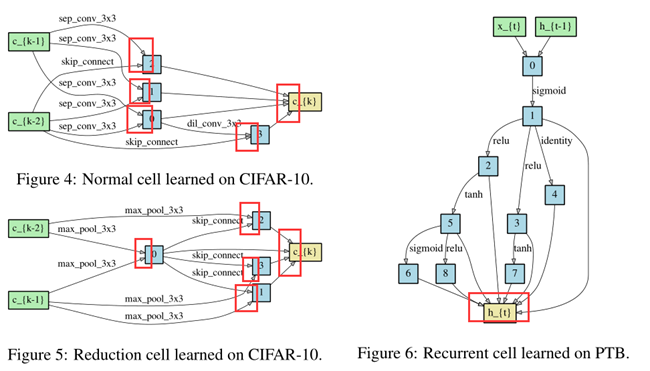
To form each node in the discrete architecture, we retain the top-k strongest operations (from distinct nodes) among all non-zero candidate operations collected from all the previous nodes.
we use k = 2 for convolutional cells and k = 1 for recurrent cellsThe strength of an operation is defined as \(\frac{\exp \left(\alpha_{o}^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)}\)
Experiments
We include the following operations in O:
- 3 × 3 and 5 × 5 separable convolutions,
- 3 × 3 and 5 × 5 dilated separable convolutions,
- 3 × 3 max pooling,
- 3 × 3 average pooling,
- identity (skip connection?)
- zero.
All operations are of
- stride one (if applicable)
- the feature maps are padded to preserve their spatial resolution.
We use the
- ReLU-Conv-BN order for convolutional operations,
- Each separable convolution is always applied twice
- Our convolutional cell consists of N = 7 nodes, the output node is defined as the depthwise concatenation of all the intermediate nodes (input nodes excluded).
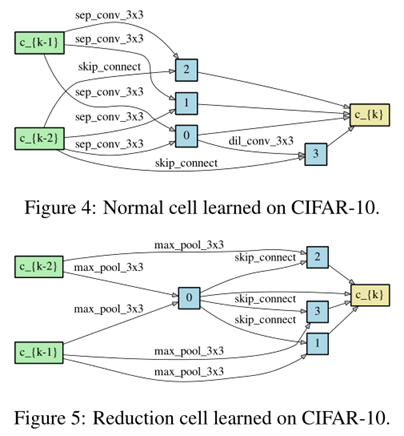
The first and second nodes of cell k are set equal to the outputs of cell k−2 and cell k−1
Cells located at the 1/3 and 2/3 of the total depth of the network are reduction cells, in which all the operations adjacent to the input nodes are of stride two.
The architecture encoding therefore is (αnormal, αreduce),
where αnormal is shared by all the normal cells
and αreduce is shared by all the reduction cells.
To determine the architecture for final evaluation, we run DARTS four times with different random seeds and pick the best cell based on its validation performance obtained by training from scratch for a short period (100 epochs on CIFAR-10 and 300 epochs on PTB).
This is particularly important for recurrent cells, as the optimization outcomes can be initialization-sensitive (Fig. 3)
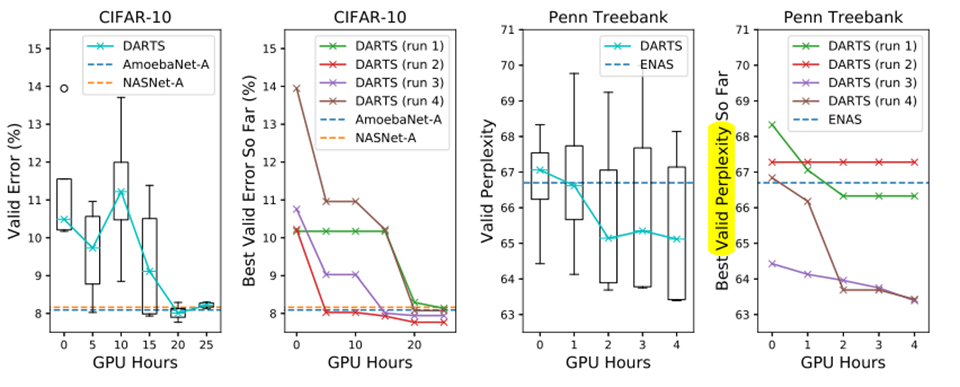
Arch Evaluation
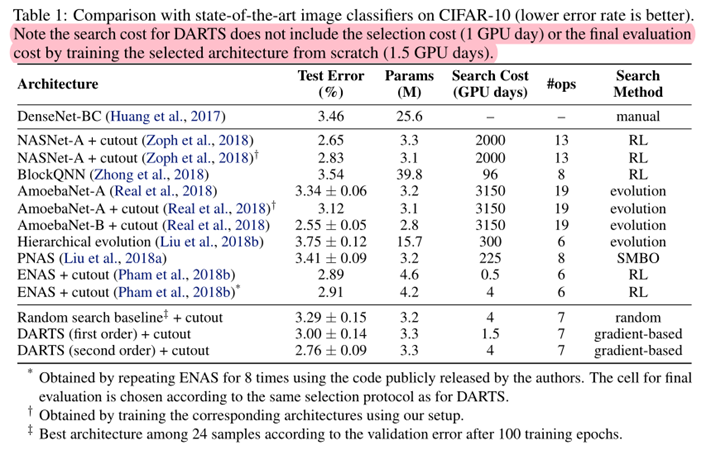
- To evaluate the selected architecture, we randomly initialize its weights (weights learned during the search process are discarded), train it from scratch, and report its performance on the test set.
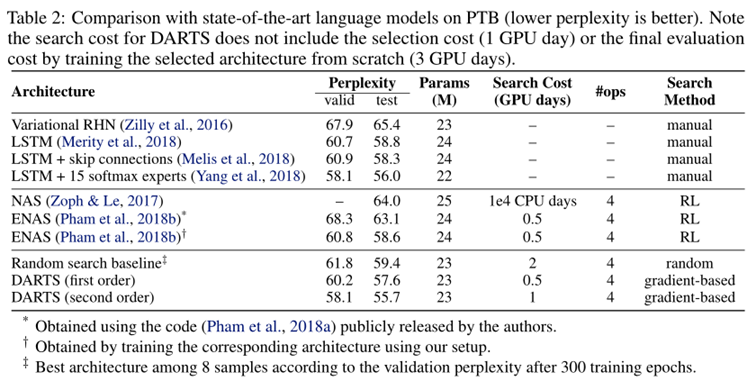
- To evaluate the selected architecture, we randomly initialize its weights (weights learned during the search process are discarded), train it from scratch, and report its performance on the test set.
Result Analysis
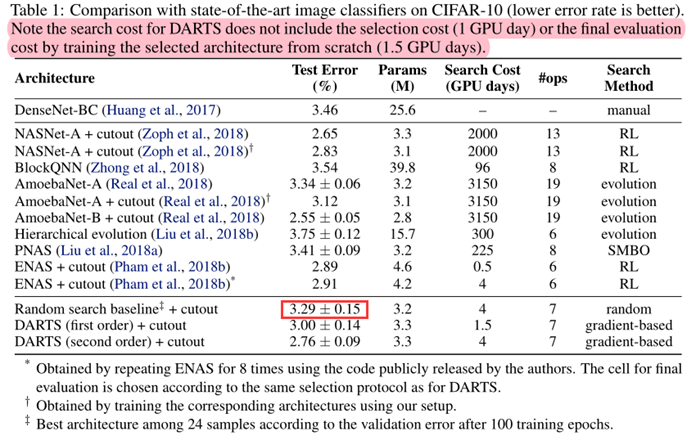
- DARTS achieved comparable results with the state of the art while using three orders of magnitude less computation resources.
- (i.e. 1.5 or 4 GPU days vs 2000 GPU days for NASNet and 3150 GPU days for AmoebaNet)
- The longer search time is due to the fact that we have repeated the search process four times for cell selection. This practice is less important for convolutional cells however, because the performance of discovered architectures does not strongly depend on initialization (Fig. 3).
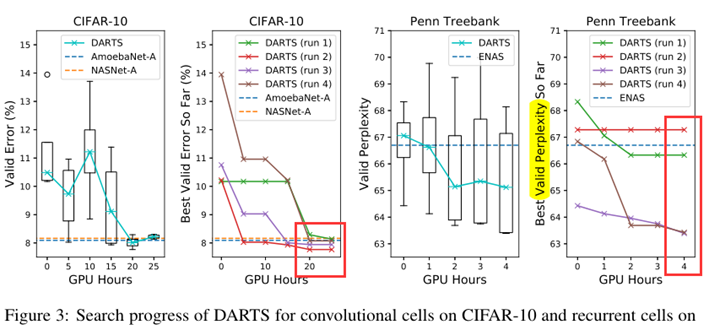
- It is also interesting to note that random search is competitive for both convolutional and recurrent models, which reflects the importance of the search space design.
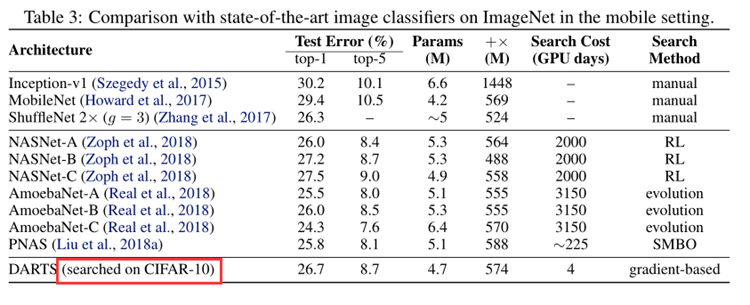
Results in Table 3 show that the cell learned on CIFAR-10 is indeed transferable to ImageNet.
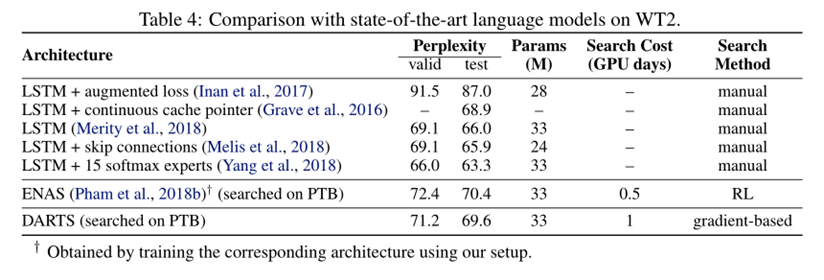
The weaker transferability between PTB and WT2 (as compared to that between CIFAR-10 and ImageNet) could be explained by the relatively small size of the source dataset (PTB) for architecture search.
The issue of transferability could potentially be circumvented by directly optimizing the architecture on the task of interest.
Conclusion
- We presented DARTS, a simple yet efficient NAS algorithm for both CNN and RNN.
- SOTA
- efficiency improvement by several orders of magnitude.
Improve
- discrepancies between the continuous architecture encoding and the derived discrete architecture. (softmax…)
- It would also be interesting to investigate performance-aware architecture derivation schemes based on the shared parameters learned during the search process.
Appendix
2019-ICLR-DARTS: Differentiable Architecture Search-论文阅读的更多相关文章
- 论文笔记:DARTS: Differentiable Architecture Search
DARTS: Differentiable Architecture Search 2019-03-19 10:04:26accepted by ICLR 2019 Paper:https://arx ...
- 论文笔记系列-DARTS: Differentiable Architecture Search
Summary 我的理解就是原本节点和节点之间操作是离散的,因为就是从若干个操作中选择某一个,而作者试图使用softmax和relaxation(松弛化)将操作连续化,所以模型结构搜索的任务就转变成了 ...
- 论文笔记:Progressive Differentiable Architecture Search:Bridging the Depth Gap between Search and Evaluation
Progressive Differentiable Architecture Search:Bridging the Depth Gap between Search and Evaluation ...
- 2019-ICCV-PDARTS-Progressive Differentiable Architecture Search Bridging the Depth Gap Between Search and Evaluation-论文阅读
P-DARTS 2019-ICCV-Progressive Differentiable Architecture Search Bridging the Depth Gap Between Sear ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- Research Guide for Neural Architecture Search
Research Guide for Neural Architecture Search 2019-09-19 09:29:04 This blog is from: https://heartbe ...
- 小米造最强超分辨率算法 | Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search
本篇是基于 NAS 的图像超分辨率的文章,知名学术性自媒体 Paperweekly 在该文公布后迅速跟进,发表分析称「属于目前很火的 AutoML / Neural Architecture Sear ...
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 论文笔记:Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation
Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation2019-03-18 14:4 ...
随机推荐
- 最短路径树:Dijstra算法
一.背景 全文根据<算法-第四版>,Dijkstra算法.我们把问题抽象为2步:1.数据结构抽象 2.实现 二.算法分析 2.1 数据结构 顶点+边->图.注意:Dijkstra ...
- 洛谷p1149
一道很有意思的题目嘞. 这道题目看起来,用搜索似乎无疑了. 我想了这样一个办法(看了很多博客似乎都没用这种方法),可能是觉得太麻烦了吧: 1.我们先把0到9的数字排列,找出排列消耗火柴等于0的序列.这 ...
- 对已经创建的docker container设置开机自启动
首先显示出所有的容器 docker ps -a #显示所有容器 设置已经建立的容器的开机自启动方法 docker update --restart=always <container ID 根据 ...
- 异常: java.lang.ClassNotFoundException: org.springframework.web.util.IntrospectorCleanupListener
如果出现这个错误信息,如果你的项目是Maven结构的,那么一般都是你的项目的Maven Dependencies没有添加到项目的编译路径下 解决办法: ①选中项目->右键Properties-& ...
- Coursera课程笔记----Write Professional Emails in English----Week 2
Let's Start Writing (Week 2) Write Effective Subject Lines be BRIEF 50 characters or less = 5-7 word ...
- boost在Qt中的使用
一.说明 理论上,Qt和boost是同等级别的C++库,如果使用Qt,一般不会需要再用boost,但是偶尔也会有特殊情况,比如,第三方库依赖等等.本文主要介绍boost在windows Qt(MinG ...
- 微信小程序使用GoEasy实现websocket实时通讯
不需要下载安装,便可以在微信好友.微信群之间快速的转发,用户只需要扫码或者在微信里点击,就可以立即运行,有着近似APP的用户体验,使得微信小程序成为全民热爱的好东西~ 同时因为微信小程序使用的是Jav ...
- 【OracleDB】 01 概述和基本操作
实例概念: Oracle有一个特殊的概念 Oracle数据库 = 数据库 + Oracle文件系统 + Oracle实例 实例处理Oracle的请求,调用文件系统 然后返回结果响应给客户端 单实例和多 ...
- 正则表达式在java中的用法
/** * 测试正则表达式的基本用法 Pattern 和 Matcher * @author 小帆敲代码 * */public class Demo01 { public static void m ...
- [zoj3627]模拟吧
思路:情况只可能是2种,两个人一直向一边走,或者有一个人折回来,对于后一种,枚举折回来的位置就行了.不过要注意两个方向都要处理下. #pragma comment(linker, "/STA ...