Java集合:ArrayList (JDK1.8 源码解读)
ArrayList
ArrayList几乎是每个java开发者最常用也是最熟悉的集合,看到ArrayList这个名字就知道,它必然是以数组方式实现的集合
关注点
说一下ArrayList的几个特点,也是面试喜欢问的几个点:
1.是否允许为空:是
2.是否允许重复数据:是
3.是否有序:是
4.是否线程安全:否
主要声明
看一下ArrayList的声明:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
ArrayList继承自AbstractList,并且实现了List接口(还实现了RandomAccess、Cloneable、Serializable),List接口又继承自顶层集合接口Cellection,实现了List接口就代表它是一个有序的集合
再看一下ArrayList声明的主要变量:
// 默认容量
private static final int DEFAULT_CAPACITY = 10; // 一个空的数组
private static final Object[] EMPTY_ELEMENTDATA = {}; // 默认容量的空数组,搞这么多空数组干嘛?|_・)
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // ArrayList的核心,elemenData就是底层的数组
transient Object[] elementData; // 数组所包含的元素数量
private int size;
这里做一下几个主要变量的说明:
1.DEFAULT_CAPACITY 并不是ArrayList的初始大小,只是默认大小
2.EMPTY_ELEMENTDATA和DEFAULTCAPACITY_EMPTY_ELEMENTDATA 就是两个空的对象数组,后面会在构造方法里面用到
3.ArrayList是基于数组的一个实现,elementData就是底层的数组
4.size数组所包含的元素的数量,ArrayList的size()方法返回的就是这个size的值
看完这些,我们来写个例子实际操作一下:
public static void main(String[] args)
{
List<String> list = new ArrayList<>();
//List<String> list = new ArrayList<>(10);
list.add("111");
list.add("222");
}
构造方法
1.无参构造器
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;// this(10) jdk1.6写法
}
直接把声明的空数组丢给elementData,也就是说ArrayList在jdk1.8中初始化的时候大小是0,并不是10,这和jdk1.6有区别
2.带初始化容量大小的构造器,上面例子中注释掉的代码的用法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
传递一个int类型的参数initialCapacity作为ArrayList的初始化大小,如果initialCapacity大于0,则声明一个initialCapacity大小的对象数组给elementData赋值,如果initialCapacity为0就把声明的空对象数组给elementData,如果小于0你懂的
3. 还有一种构造器例子中未展示的 public ArrayList(Collection<? extends E> c) 传一个集合进去,也比较简单就是把集合转成数组赋值给elementData
添加元素
照着例子继续往下看,添加元素的时候,ArrayList会做什么,看看add的源码:
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
第二行代码是扩容用的我们先不管,直接看第三行,第三行告诉我们再调用add方法往集合里面添加元素的时候只是给对象数组加了一个元素而已,画图来说明一下

扩容
new ArrayList()的时候构造方法只给了一个DEFAULTCAPACITY_EMPTY_ELEMENTDATA声明的空对象数组,为什么例子的add方法的第三行还能执行往elementData里面添加元素,那么扩容就出现了
看第七行的ensureCapacityInternal(int minCapacity)方法(注:size表示数组内元素个数,那么我要往数组添加一个元素,minCapacity就是数组执行添加时最小需要的容量),执行add("111"),ArrayList的size初始值为0,那么minCapacity的值就为1,看第8行此时elementData是不是就是那个空的对象数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA,
继续往下,把minCapacity赋值为minCapacity和默认容量两者的最大值,minCapacity的值就成了10,然后minCapacity最小容量和数组长度去比较,数组的长度已经不能满足添加元素后的最小容量,数组就会去执行扩容的grow(minCapacity)方法进行数组扩容,所以ArrayList触发扩容的条件就是数组长度不够了或者说数组已经装满了,看一下grow方法具体:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
简单的说一下,第三行:新的数组长度=原数组长度 + 原数组长度的一半,这里使用的位运算>>1 ,oldCapacity是偶数就是一半,基数就是(oldCapacity-1)/2,因为长度必须得是整数,jdk1.6中使用的是 newCapacity = (oldCapacity * 3)/2 + 1,所以当别人问你ArrayList每次扩容多少时,你可以说扩容了二分之一的大小
问题:至于为什么要扩容二分之一?
可以看第八行代码,当确定了新数组长度之后,会把旧的elementData复制到一个新的长度为newCapacity的数组中去然后赋值给原来的elementData数组,如图
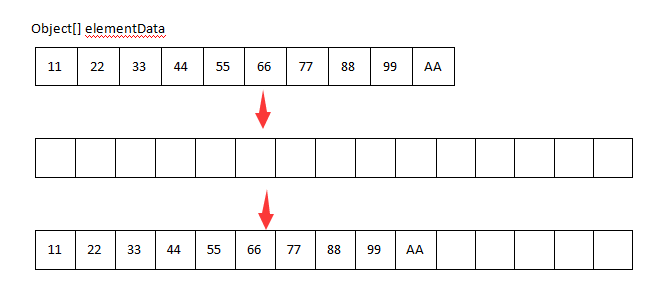
1.如果扩容的太少,则必须频繁的进行扩容操作,频繁的复制数组这必然会降低效率
2.如果扩容的太多,数组内就会有很多空闲的位置,就会造成空间上的浪费
所以JDK的开发人员必定是经过考量和权衡才会决定扩容的大小
插入元素
ArrayList在进行插入操作的时候也是使用的add方法,举个例子:
List<String> list = new ArrayList<>();
list.add("11");
list.add("33");
list.add("44");
list.add("55");
list.add(2,"22");//插入元素
第六行便是往ArrayList里面插入元素,看一下list.add(2,"22")执行的操作:
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
先检查插入的下标是否小于0或者大于数组内元素的个数,如果不在这个范围内抛出数组下标越界IndexOutOfBoundsException
判断下标合法性之后和添加元素一样判断是否需要扩容,然后按照下标指定的位置,把elementData数组内从指定位置开始的所有元素利用System.arraycopy方法做一个整体复制,向后移动一个位置,并且为指定下标位置插入对应的元素,画图表示一下这个过程:
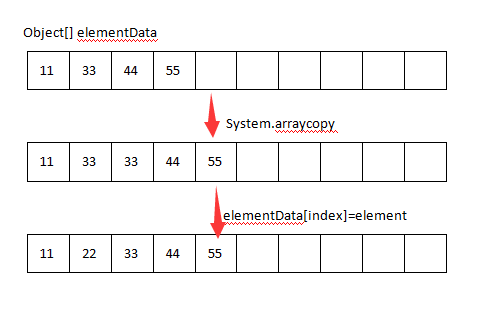
删除元素
ArrayList提供了两种删除元素的方法:
1.通过指定下标删除
2.通过指定元素删除
先看第一种:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
同样的先检查指定下标的合法性,是否在可删除范围内,记录要删除的元素,return的时候返回删除的元素,然后获取需要复制的数组长度,除非你指定删除的位置就是数组的最后一个元素,否则就是同样的套路,复制指定下标+1位置开始的元素,向前移动一个位置,并且给数组元素最后一个元素赋值null,让GC来回收它,来个图表示一下:
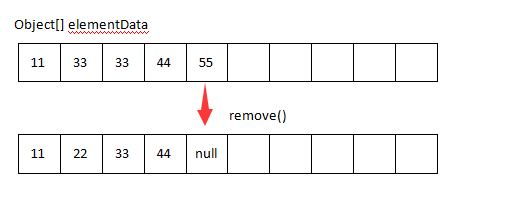
再来看第二种按照元素删除:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
遍历数组寻找匹配的元素,只不过元素为null的时候使用的==判断其他类型都使用equals方法判断,如果匹配了就执行fastRemove,fastRemove干了啥呢?
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
这不就是按照下标删除的操作吗?所以这两种删除方式的差别就是第一种返回被删除的元素,第二种删除匹配元素返回true,没有匹配元素返回false
到这里ArrayList的基本操作就讲完了,总结一下:
ArrayList的优点:
1.ArrayList层是数组实现的,支持随机访问,并且实现了RandomAccess接口,所以查找数据非常快
2.顺序添加非常快,只是往数组尾部添加了一个元素
3.从尾部删除也非常方便,只是把最后一个元素变成了null,等待GC回收
ArrayList的缺点:
1.如果从中间插入元素或者删除元素会涉及到数组元素的复制,如果复制的元素太多非常耗费性能
2.ArrayList的底层数组是个动态数组,大小会随着元素的增加而进行扩容,扩容涉及到数组元素的复制,会消耗性能和空间,所以如果在使用ArrayList的时候能确定或者大概知道数据量大小,在new ArrayList的时候请一个合理的初始化大小,避免频繁扩容
总的来说ArrayList适合顺序添加,随机访问的使用场景
ArrayList和Vector的区别
ArrayList里面的方法都不是线程同步的,所以ArrayList的线程是不安全的,在多线程情况下会有线程安全问题,可以使用Collections.synchronizedList方法把你的ArrayList变成一个线程安全的List
List<String> synchronizedList = Collections.synchronizedList(list);
还有一种方法就是使用Vector,Vector和ArrayList的实现方式几乎一样,只不过Vector的大部分public方法都是加了synchronized,ArrayList和Vector主要有两个区别:
1.Vector线程安全
2.Vector可以指定增长因子,扩容的时候原数组会增加增长因子个大小,如果增长因子缺省那么就会增加一倍的大小
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
Java集合:ArrayList (JDK1.8 源码解读)的更多相关文章
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- 【源码阅读】Java集合之二 - LinkedList源码深度解读
Java 源码阅读的第一步是Collection框架源码,这也是面试基础中的基础: 针对Collection的源码阅读写一个系列的文章; 本文是第二篇LinkedList. ---@pdai JDK版 ...
- Java集合系列:-----------03ArrayList源码分析
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- Java集合系列[3]----HashMap源码分析
前面我们已经分析了ArrayList和LinkedList这两个集合,我们知道ArrayList是基于数组实现的,LinkedList是基于链表实现的.它们各自有自己的优劣势,例如ArrayList在 ...
- Java集合 - List介绍及源码解析
(源码版本为 JDK 8) 集合类在java.util包中,类型大体可以分为3种:Set.List.Map. JAVA 集合关系(简图) (图片来源网络) List集合和Set集合都是继承Collec ...
- HashMap底层原理及jdk1.8源码解读
一.前言 写在前面:小编码字收集资料花了一天的时间整理出来,对你有帮助一键三连走一波哈,谢谢啦!! HashMap在我们日常开发中可谓经常遇到,HashMap 源码和底层原理在现在面试中是必问的.所以 ...
- 【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io ...
随机推荐
- 常用的python标准库
os : 操作系统接口 sys: 命令行操作 re : 正则模块 math : 数学模块 time,timedate: 日期模块 random: 随机数模块 threading: 线程 ...
- vue 听说你很会传值?
前置 大小 vue 项目都离不开组件通讯, 在这里总结一下vue组件通讯方式并列出, 都是简单的例子. 适合像我这样的小白.如有错误,欢迎指正. 温馨提示: 下文没有列出 vuex, vuex 也是重 ...
- Java 运行时数据区
写在前面 本文描述的有关于 JVM 的运行时数据区是基于 HotSpot 虚拟机. 概述 JVM 在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域.这些区域都有各自的用途,以 ...
- I - 动物狂想曲 HDU - 6252(差分约束)
I - 动物狂想曲 HDU - 6252 雷格西桑和路易桑是好朋友,在同一家公司工作.他们总是一起乘地铁去上班.他们的路线上有N个地铁站,编号从1到N.1站是他们的家,N站是公司. 有一天,雷格西桑起 ...
- D3属性大全
https://www.cnblogs.com/bester-ace/articles/10948793.html https://www.cnblogs.com/qingmingsang/artic ...
- UnboundLocalError,探讨Python中的绑定
绑定 将python闭包之前,先梳理一下闭包中的绑定操作. 先看看2个相关的错误 NameError 和UnboundLocalError When a name is not found at al ...
- java仿win7计算器布局
代码: package calculator; import javax.swing.*; import java.awt.*; import java.awt.event.*; public cla ...
- Vulnhub bulldog靶机渗透
配置 VM运行kali,桥接模式设置virtualbox. vbox运行靶机,host-only网络. 信息搜集 nmap -sP 192.168.56.0/24 或者 arp-scan -l #主机 ...
- spring使用jdbc
对于其中的一些内容 @Repository(value="userDao") 该注解是告诉Spring,让Spring创建一个名字叫“userDao”的UserDaoImpl实例. ...
- 2017蓝桥杯杨辉三角(C++C组)
题目: 杨辉三角也叫帕斯卡三角,在很多数量关系中可以看到,十分重要.第0行: 1第1行: 1 1第2行: 1 2 1第3行: 1 3 ...