kafka高吞吐量之消息压缩

背景
保证kafka高吞吐量的另外一大利器就是消息压缩。就像上图中的压缩饼干。
压缩即空间换时间,通过空间的压缩带来速度的提升,即通过少量的cpu消耗来减少磁盘和网络传输的io。
消息压缩模型
消息格式V1

kafka不会直接操作单条消息,而是直接操作一个消息集合。
消息格式V2:
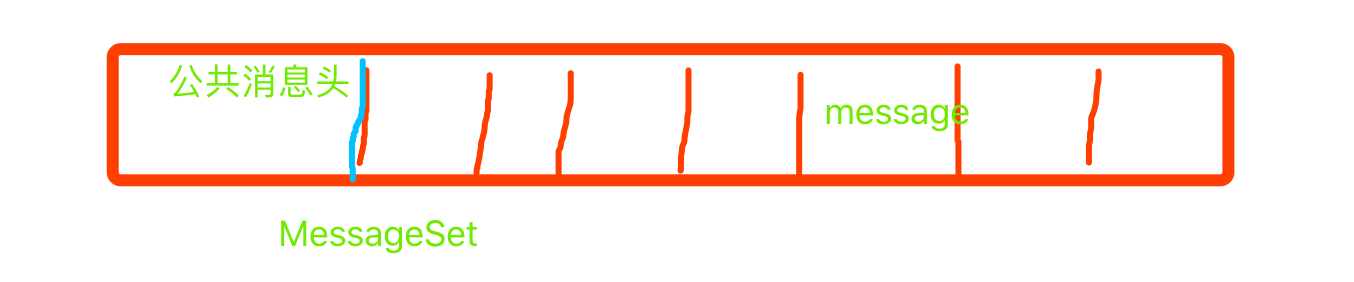
1, 抽取了消息的公共部分放到消息集合中;去掉每条消息的公共部分,减少了总体积。
2,消息的CRC校验由对每一条消息,移动到了对消息集合进行校验,减少了校验次数,节省了cpu;
3, 对单个消息进行压缩,放到消息的body字段 pk 对消息集合整个进行压缩 更好的压缩效果;
压缩过程模型

压缩算法比较
如何衡量一个压缩算法的好坏。

常见的压缩算法对比:
Zstandard 算法(简写为 zstd)。它是 Facebook 开源的一个压缩算法,能够提供超高的压缩比

启用压缩场景
如果cpu负载比较高,不适合启用压缩;
如果带宽不足,而cpu负载不高,最适合启用压缩,节约大量的带宽;
尽量避免消息格式不一致带来的解压缩消耗。
小结
压缩的目的是较少空间占用,带来传输速度的提升,但是需要消耗一定的cpu ;
是一种提高kafka消息吞吐量的有效办法。
本节回顾了新版的kafka是如何对消息进行压缩的,压缩和解压缩的流程是怎样的,
然后对比了常见的4种压缩算法,根据具体的使用场景来选择是否启用压缩,以及选择合适的压缩算法。
然后给出了压缩的配置参数,在producer和borker端都可以使用compression.type来设置。
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。
我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

kafka高吞吐量之消息压缩的更多相关文章
- kafka高吞吐量的分布式发布订阅的消息队列系统
一:kafka介绍kafka(官网地址:http://kafka.apache.org)是一种高吞吐量的分布式发布订阅的消息队列系统,具有高性能和高吞吐率. 1.1 术语介绍BrokerKafka集群 ...
- Kafka — 高吞吐量的分布式发布订阅消息系统【转】
1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有哪两个条件 ...
- kafka 高吞吐量的因素
1.顺序的方式存储数据: 2.批量发送: 3.零拷贝: 来源:咕泡学院
- kafka设计要点之高吞吐量
2345678910111213141516 /** * Delete this log segment from the filesystem. * * @throws KafkaStorageEx ...
- kafka 基础知识梳理-kafka是一种高吞吐量的分布式发布订阅消息系统
一.kafka 简介 今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何及时做到如上两点 ...
- Kafka如何保证高吞吐量
1.顺序读写 kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能 顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写 生产者负责写入 ...
- kafka为什么吞吐量高,怎样保证高可用
1:kafka可以通过多个broker形成集群,来存储大量数据:而且便于横向扩展. 2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向l ...
- 高吞吐量的分布式发布订阅消息系统Kafka--安装及测试
一.Kafka概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因 ...
- Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于2010年贡献给 ...
随机推荐
- 如何删除Python中文本文件的文件内容?
在python中: open('file.txt', 'w').close() 或者,如果你已经打开了一个文件: f = open('file.txt', 'r+') f.truncate(0) # ...
- 在django中如何从零开始搭建一个mock服务
mock概念 mock 就是模拟接口返回的一系列数据,用自定义的数据替换接口实际需要返回的数据,通过自定义的数据来实现对下级接口模块的测试.这里分为两类测试:一类是前端对接口的mock,一类是后端单元 ...
- ios shell打包脚本 xcodebuild
#! /bin/bash project_path=$() project_config=Release output_path=~/Desktop build_scheme=YKTicketsApp ...
- iOS App的启动过程
一.mach-O Executable 可执行文件 Dylib 动态库 Bundle 无法被连接的动态库,只能通过 dlopen() 加载 Image 指的是 Executable,Dylib 或者 ...
- 20175314 《Java程序设计》第十周学习总结
20175314 <Java程序设计>第十周学习总结 教材学习内容总结 进程与线程:一个进程的进行期间可以产生多个线程. Java内置对多线程的支持,计算机只能执行线程中的一个,Java虚 ...
- RocketMQ调研
一.发展历程 早期淘宝内部有两套消息中间件系统:Notify和Napoli. 先有的Notify(至今12历史),后来因有序场景需求,且恰好当时Kafka开源(2011年),所以参照Kafka的设计理 ...
- 利用data文件恢复MySQL数据库
背景:测试服务器 MySQL 数据库不知何种原因宕机,且无法启动,而原先的数据库并没有备份,重新搭建一个新服务器把原data 复制出来 进行恢复 1 尽量把原data复制出来(一个都不要少以防意外 其 ...
- Module Error (/index.js): error: 'HelloWorld' is defined but never used (no-unused-vars) at src\views\A.vue:9:8:
原因:
- jenkins 脱机下 安装插件失败
1.首次进入,提示离线 2.网上给出了绝大部分答案是进入Manage Plugins 中在高级下将升级站点的https换成http,但是都没解决我的问题 还是报错,用了大部分时间查阅 最终才发现问题 ...
- js之:漂浮线
(function initJParticle( $ ){ "use strict"; var createParticlesSandbox, Utils; Utils = {}; ...