Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
注意:Kafka并没有遵循JMS规范,它只提供了发布和订阅通讯方式!!!!!
kafka中文官网:http://kafka.apachecn.org/quickstart.html
Kafka用在日志里面比较多 大数据里面的
MQ的思想: 解耦合 流量削峰 异步通信
kafka优点:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作,我之前在课题里用到Spark Streaming 作为消费者过滤数据。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka依赖Zookeeper,kafka把集群的节点信息 全部存放在Zookeeper节点!!!!!
应用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr或者Spark Streaming等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
关键名词解释:
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。 broker就是节点,单机的kafka服务器
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发,kafka服务器存放 主题。kafka集群,相当于把topic进行拆分,拆分到不同的分区进行存放。类似于数据库存放数据量比较大的情况下,表进行拆分。查询时候进行分表查询。
massage: Kafka中最基本的传递对象。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列,就是分区的概念,相当于把topic存放到不同的物理机器上存储起来。topic消息进行拆分,均摊存放到不同的
集群中的kafka服务器上。 每个partition其实是有顺序的。
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer : 生产者,生产message发送到topic
Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费
Consumer Group:消费者组,一个Consumer Group包含多个consumer。在同一个组可以收到消息
Offset:偏移量,理解为消息partition中的索引即可。 消息在partition的索引的位置
需要理解存储策略:
1)kafka以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,有多个segment组成。
2)每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3)每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4)发布者发到某个topic的消息会被均匀的分布到多个partition上(或根据用户指定的路由规则进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
生产者发送消息原理:

Kafka高可用集群原理:
kafka 是topic为主的,kafka必须集群,核心就是集群,才能体现分区的优势!
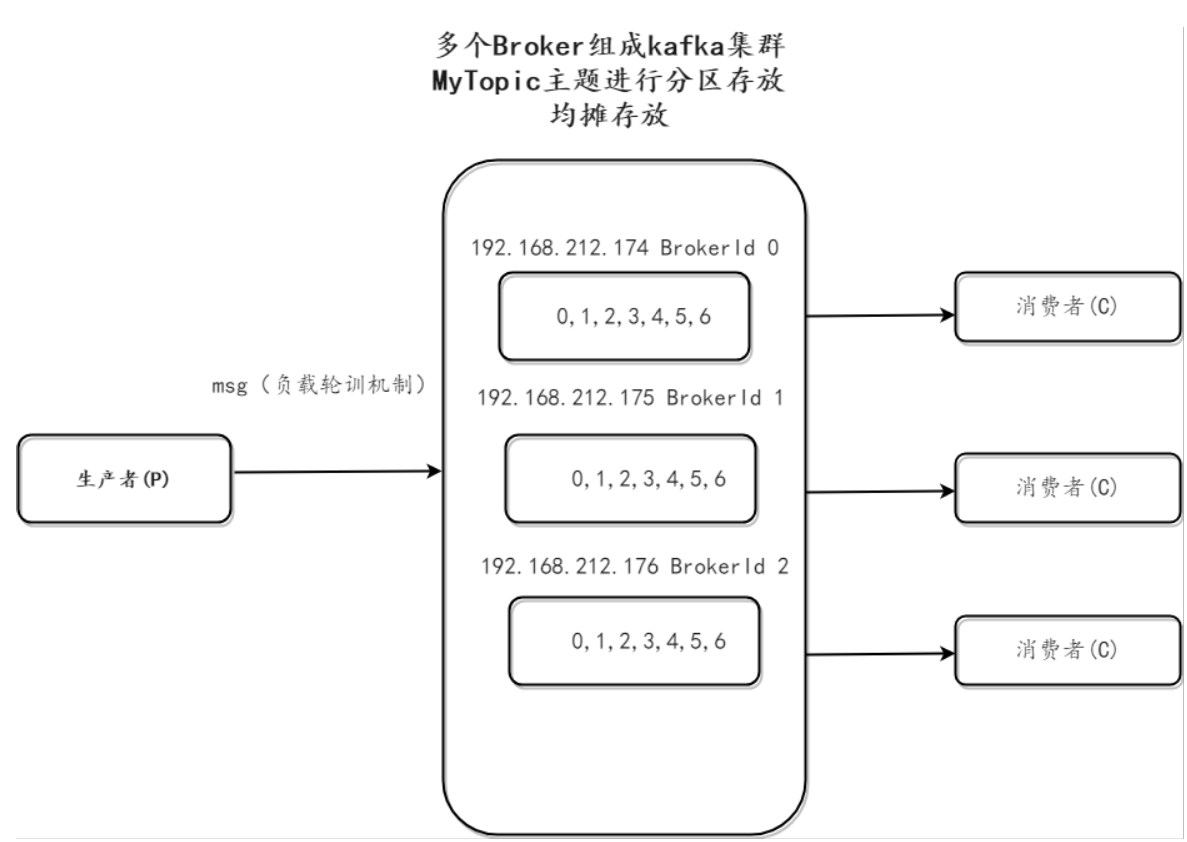
集群环境下 生产者投递消息 到哪个Broker?
(Tomcat 通过Nginx 集合起来的思想深入人心)
集群的目的就是分担单台的压力,kafaka采用了 负载轮训的机制
数据库里面 单表 有1亿条数据 查询很慢的 。所以分表,比如按照月份进行分,或者根据其他的业务来进行分。
下图三个Broke topic进行分区存放,在创建topic时候,轮训去指定分区。BrokerId区分之
0,1,2,34,5,6为offset 每个分区中的offset是独立的,互不影响的
三个broker,有三个消费者是比较合理的~
Zookeeper 节点专门存放topic 信息。 kafka 的broker的信息存放在zk节点
Kafka高可用环境搭建的更多相关文章
- haproxy + rabbitmq + keepalived的高可用环境搭建
一.rabbitmq的搭建:参考rabbimq的安装及集群设置 二.安装和配置haproxy 1.安装haproxyyum install haproxy 2.安装rsysloga. 检查rsyslo ...
- hadoop学习笔记(八):hadoop2.x的高可用环境搭建
本文原创,转载请注明作者及原文链接 高可用集群的搭建: 几个集群的启动顺序问题: 1.先启动zookeeper --->zkServer.sh start 2.启动journalNodes集群 ...
- 大数据学习(07)——Hadoop3.3高可用环境搭建
前面用了五篇文章来介绍Hadoop的相关模块,理论学完还得操作一把才能加深理解.这一篇我会花相当长的时间从环境搭建开始,到怎么在使用Hadoop,逐步介绍Hadoop的使用. 本篇分这么几段内容: 规 ...
- hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者 所用到的命令的总结: yarn:启动start-yarn.sh 停止stop-yarn.sh zk :zkServer.start ;:zkServer. ...
- Eureka高可用环境搭建
1.创建govern-center 子工程 包结构:com.dehigher.govern.center 2.pom文件 (1)父工程pom,用于依赖版本管理 <dependencyManage ...
- Redis Cluster 集群三主三从高可用环境搭建
前言 Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用. Window环境下载地址:https://github.com/tporadowski/redis ...
- KEEPALIVED+LVS+MYCAT实现MYSQL高可用环境搭建
一.安装keepalived和ipvsadm 注意:ipvsadm并不是lvs,它只是lvs的配置工具. 为了方便起见,在这里我们使用yum的安装方式 分别在10.18.1.140和10.18.1.1 ...
- 阶段5 3.微服务项目【学成在线】_day09 课程预览 Eureka Feign_03-Eureka注册中心-搭建Eureka高可用环境
1.3.2.2 高可用环境搭建 Eureka Server 高可用环境需要部署两个Eureka server,它们互相向对方注册.如果在本机启动两个Eureka需要 注意两个Eureka Server ...
- 使用KeepAlived搭建MySQL高可用环境
使用KeepAlived搭建MySQL的高可用环境.首先搭建MySQL的主从复制在Master开启binlog,创建复制帐号,然后在Slave输入命令 2016年7月25日 配置安装技巧: ...
随机推荐
- 微信小程序结构分析
1.Console页面:控制台信息页两个作用: (1)开发直接输入代码并且进行调试: (2)显示小程序的错误输出: 2.Sources页面:源文件调试信息页,用于显示当前项目的脚本文件. 3.Netw ...
- linux之shell之if、while、for语句介绍
一.基本判断条件 1)逻辑运算符 -a expr1 -a expr2 逻辑与 -o expr1 -o expr2 逻辑或 ! !expr1 ...
- 排序算法 c实现
c语言实现插入排序.冒泡排序.选择排序.快速排序.堆排序.归并排序.希尔排序示例,需要的朋友可以参考下 实现以下排序 插入排序O(n^2) 冒泡排序 O(n^2) 选择排序 O(n^2) 快速 ...
- nginx发布的nginScript
nginx发布的nginScript 背景 2015年9月,nginx宣布支持类JavaScript语言.这意味着开发者可以更轻松.自由的控制全球最优秀的HTTP及反向代理服务器,并在此之上可以衍生出 ...
- DataTable数据导出到Excel,并发送到客户端进行下载
本代码实现思路是:页面显示和导出分开,导出的数据和用于页面显示的是同一查询数据方式,所以也是同样的数据,只是在导出数据时从数据库重新捞了一次数据.此导出数据方式会先将数据保存到Excel中,然后将创建 ...
- Toeplitz matrix
w https://en.wikipedia.org/wiki/Toeplitz_matrix Proof of Stolz-Cesaro theorem | planetmath.org http ...
- 使用QFuture类监控异步计算的结果
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Amnes1a/article/details/65630701在Qt中,为我们提供了好几种使用线程的 ...
- Linux源码包安装和脚本安装
能够先 vi INSTALL 看看安装过程. 1.源码包安装 2.脚本安装
- node.js, node-debug, node-inspector, npm 等等的使用问题解决
1.node-debug的error: /home/hzh/hzh/soft/softy/node-v6.10.0-linux-x64/lib/node_modules/node-inspector/ ...
- CentOS7更改网卡名称为eth0
#!/bin/bash # Author: fansik # Date: 2017年 09月 19日 星期二 :: CST sed -i 's@rhgb@rhgb net.ifnames=0@g' / ...