作业3-k均值算法
4. 作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5).想想k均值算法中以用来做什么
答:
(1)
第一轮:13、10、5

第二轮:13、9、4

(2)
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
#导入数据
iris = load_iris()
data = iris.data # 数据值
data.shape # 可知数据的总数和属性个数
n = len(data) # 数据集样本个数
m = data.shape[1] # 数据的属性个数
# 类中心个数(1-5)
k = 3
dist = np.zeros([n, k+1]) # k+1是最后一列要归类
# 选中心
center = data[:k, :] # k为3所以是前三行所有属性
centerNew = np.zeros([k, m]) # 初始化新的类中心
while True:
# 求距离
for i in range(n):
for j in range(k):
dist[i, j] = np.sqrt(sum((data[i, :]-center[j, :])**2)) # 求欧式距离
# 归类
dist[i, k] = np.argmin(dist[i, :k])
for i in range(k):
index = dist[:, k] == i
centerNew[i, :] = data[index, :].mean(axis=0)
# 判定结果
if np.all((center == centerNew)):
break
else:
center = centerNew
print("聚类结果:\n", dist[:, k])
# print(data[:,k])
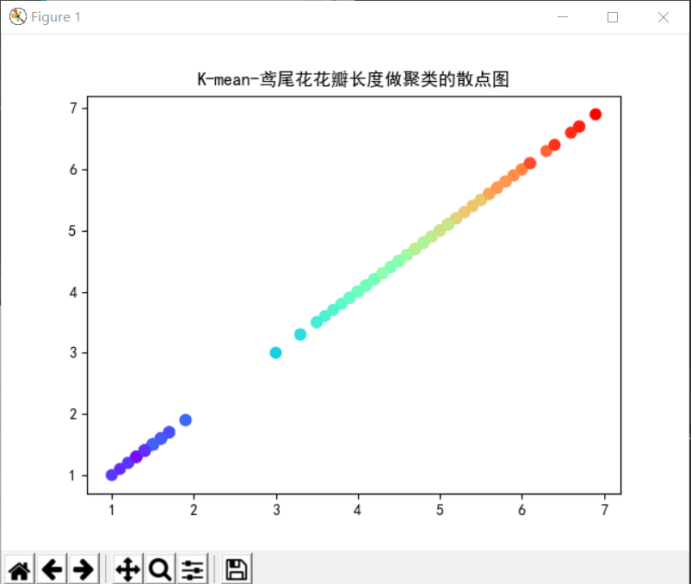
plt.scatter(data[:,2], data[:,2], c=dist[:,2], s=50, cmap='rainbow')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("K-mean-鸢尾花花瓣长度做聚类的散点图")
plt.show()
(3)
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
# print(iris)
X = iris.data[:, 2] # 第三列为花瓣长度
X = X.reshape(-1, 1) # 令新数组列为1
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
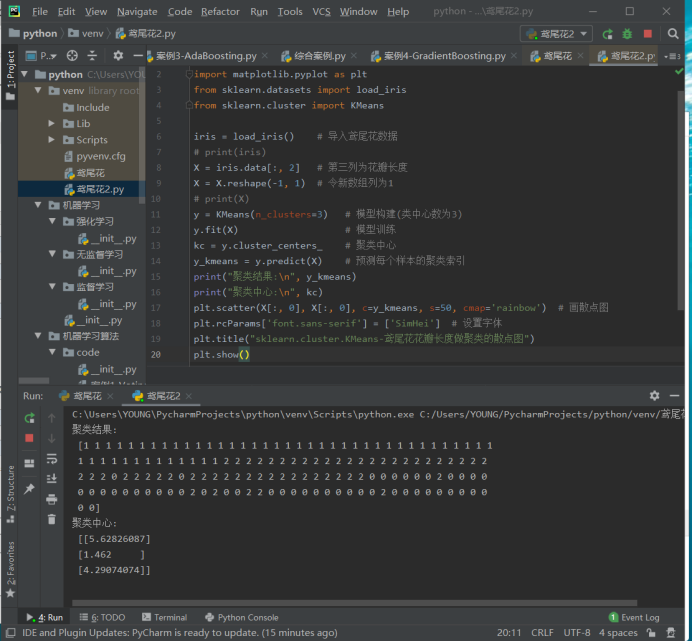
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 0], X[:, 0], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("sklearn.cluster.KMeans-鸢尾花花瓣长度做聚类的散点图")
plt.show()

(4)
# 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
X = iris.data # 鸢尾花完整数据
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
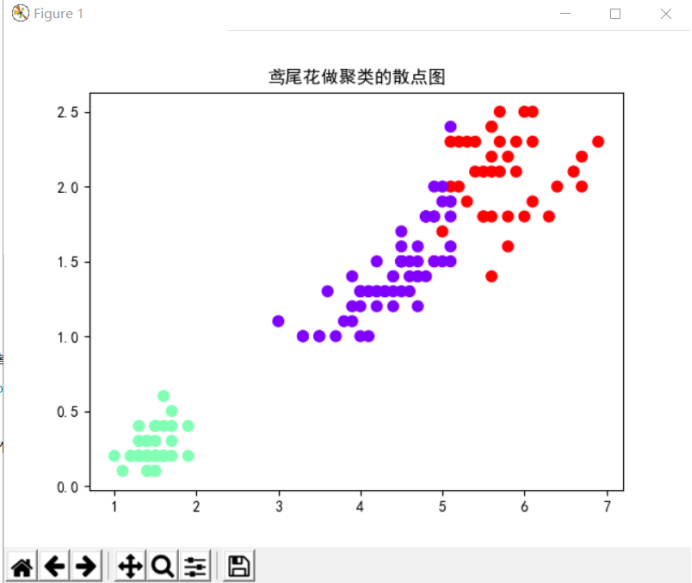
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 2], X[:, 3], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("鸢尾花做聚类的散点图")
plt.show()
(5)可以通过k均值算法进行库存分类,例如按销售活动分组库存或者按制造指标对库存进行分组,也可以用来识别不同类型的癌症特征。
作业3-k均值算法的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- windows server 2016 远程桌面mstsc DPI(更改文本、应用和其他项目大小) 设置
windows server 2016 远程桌面mstsc DPI 设置 在高分辨率机器2K,4K,8K,登入使用window远程桌面mstsc时,登入后虽然分辨率变成了和cilent一样分辨率 但是 ...
- 7.Metasploit后渗透
Metasploit 高阶之后渗透 01信息收集 应用场景: 后渗透的第一步,更多地了解靶机信息,为后续攻击做准备. 02进程迁移 应用场景: 如果反弹的meterpreter会话是对方打开了一个你预 ...
- JavaScript五子棋第二版
这是博主做的一个移动端五子棋小游戏,请使用手机体验.由于希望能有迭代开发的感觉,所以暂时只支持双人对战且无其他提示及对战界面,只有胜利提示,悔棋.对战双方显示.人机对战.集成TS(用于学习).和局 ...
- H5的新特性
https://blog.csdn.net/weixin_42441117/article/details/80705203 1.h5新语义元素(有利于代码可读性和SEO)2.本地存储 h5提供 ...
- 在.NET Core中检查证书的到期日期
在 NUnit 测试中,我需要检查证书的有效期. 下面的代码片段可用于使用自定义证书验证回调检查任何证书属性. 所有你需要做的就是在回调中读取你感兴趣的属性,这样你就可以在之后检查它们. DateTi ...
- C语言 文件操作(六)
一.fseek() int fseek(FILE * stream, long offset, int whence); 1.参数stream 为已打开的文件指针. 2.参数offset 是偏移量,该 ...
- Ceph学习笔记(4)- OSD
前言 OSD是一个抽象的概念,对应一个本地块设备(一块盘或一个raid组) 传统NAS和SAN存储是赋予底层物理磁盘一些CPU.内存等,使其成为一个对象存储设备(OSD),可以独立进行磁盘空间分配.I ...
- hive常用函数六
cast 函数: 类型转换函数,cast(kbcount as int); case when: 条件判断,case when kbcount is not null and cast(kbcount ...
- python3(二十一) pip
先确保安装了windows的Python的pip 出现上图说明安装了,命令未找到则没有安装 安装一个图形处理的第三方库 Anaconda安装第三方库 我们经常需要用到很多第三方库,如MySQL驱动程序 ...
- lr事务
事务:transaction(性能里面的定义:客户机对服务器发送请求,服务器做出反应的过程) 用于模拟用户的一个相对完整的业务操作过程:如登录,查询,交易等操作(每次http请求不会用来作为一个事务) ...