作业3-k均值算法
4. 作业:
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
4). 鸢尾花完整数据做聚类并用散点图显示.
5).想想k均值算法中以用来做什么
答:
(1)
第一轮:13、10、5

第二轮:13、9、4

(2)
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import numpy as np
#导入数据
iris = load_iris()
data = iris.data # 数据值
data.shape # 可知数据的总数和属性个数
n = len(data) # 数据集样本个数
m = data.shape[1] # 数据的属性个数
# 类中心个数(1-5)
k = 3
dist = np.zeros([n, k+1]) # k+1是最后一列要归类
# 选中心
center = data[:k, :] # k为3所以是前三行所有属性
centerNew = np.zeros([k, m]) # 初始化新的类中心
while True:
# 求距离
for i in range(n):
for j in range(k):
dist[i, j] = np.sqrt(sum((data[i, :]-center[j, :])**2)) # 求欧式距离
# 归类
dist[i, k] = np.argmin(dist[i, :k])
for i in range(k):
index = dist[:, k] == i
centerNew[i, :] = data[index, :].mean(axis=0)
# 判定结果
if np.all((center == centerNew)):
break
else:
center = centerNew
print("聚类结果:\n", dist[:, k])
# print(data[:,k])
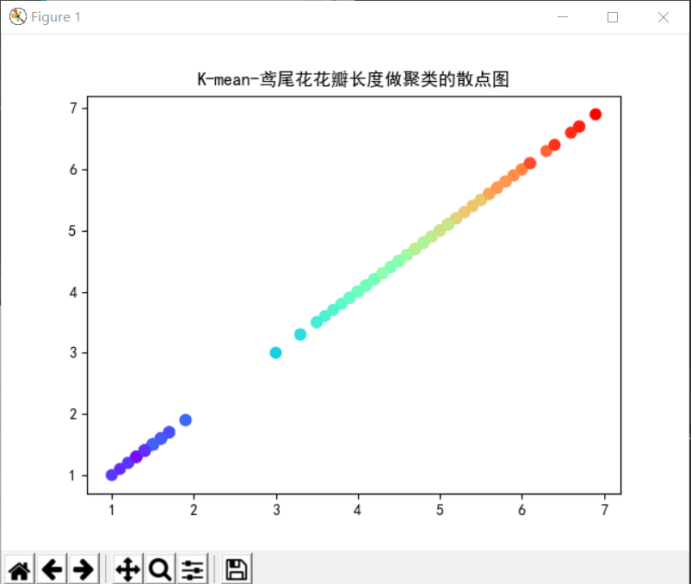
plt.scatter(data[:,2], data[:,2], c=dist[:,2], s=50, cmap='rainbow')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("K-mean-鸢尾花花瓣长度做聚类的散点图")
plt.show()
(3)
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
# print(iris)
X = iris.data[:, 2] # 第三列为花瓣长度
X = X.reshape(-1, 1) # 令新数组列为1
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
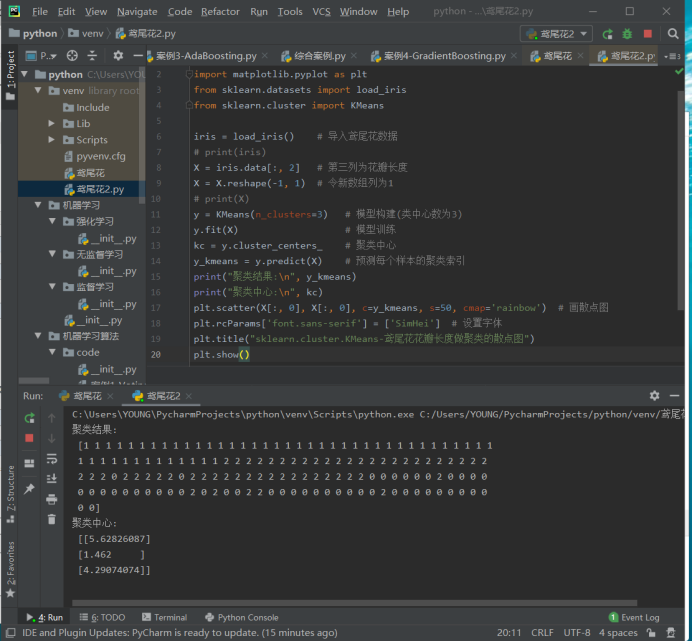
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 0], X[:, 0], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("sklearn.cluster.KMeans-鸢尾花花瓣长度做聚类的散点图")
plt.show()

(4)
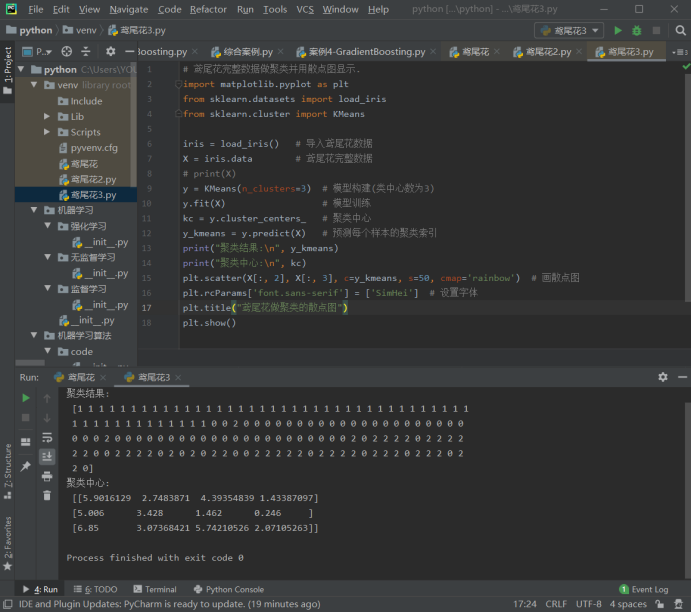
# 鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans iris = load_iris() # 导入鸢尾花数据
X = iris.data # 鸢尾花完整数据
# print(X)
y = KMeans(n_clusters=3) # 模型构建(类中心数为3)
y.fit(X) # 模型训练
kc = y.cluster_centers_ # 聚类中心
y_kmeans = y.predict(X) # 预测每个样本的聚类索引
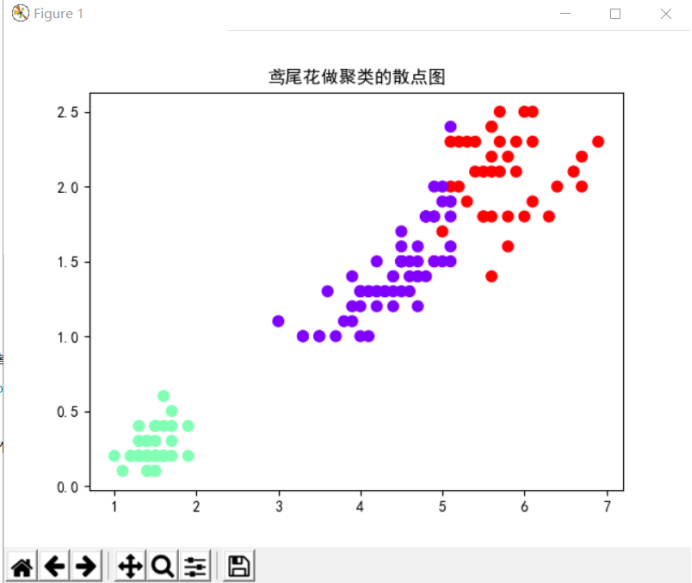
print("聚类结果:\n", y_kmeans)
print("聚类中心:\n", kc)
plt.scatter(X[:, 2], X[:, 3], c=y_kmeans, s=50, cmap='rainbow') # 画散点图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体
plt.title("鸢尾花做聚类的散点图")
plt.show()
(5)可以通过k均值算法进行库存分类,例如按销售活动分组库存或者按制造指标对库存进行分组,也可以用来识别不同类型的癌症特征。
作业3-k均值算法的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- spark Bisecting k-means(二分K均值算法)
Bisecting k-means(二分K均值算法) 二分k均值(bisecting k-means)是一种层次聚类方法,算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二.之后选择能最大程 ...
随机推荐
- E 比赛评分
时间限制 : - MS 空间限制 : - KB 评测说明 : 1s,128m 问题描述 Lj最近参加一个选秀比赛,有N个评委参加了这次评分,N是奇数.评委编号为1到N.每位评委给Lj的分数是 ...
- 老技术新谈,Java应用监控利器JMX(3)
各位坐稳扶好,我们要开车了.不过在开车之前,我们还是例行回顾一下上期分享的要点. 上期我们深入的聊了聊 JMX,把 JMX 的架构了解了七七八八,最后通过代码实战,解决系列疑问,实现远程动态修改应用参 ...
- div实现富文本编辑框
ocument.execCommand()方法处理Html数据时常用语法格式如下:document.execCommand(sCommand[,交互方式, 动态参数]) 其中:sCommand为指令参 ...
- mysql物理结构
MySQL是通过文件系统对数据和索引进行存储的. MySQL从物理结构上可以分为日志文件和数据索引文件. MySQL在Linux中的数据索引文件和日志文件都在/var/lib/mysql目录下. 日志 ...
- 基于 HTML5 WebGL 的 水泥工厂可视化系统
前言 如今的制造行业,基于数据进行生产策略制定与管理已经成为一种趋势,特别是 工业4.0 的浪潮下,数据战略已经成为很多制造企业的优先战略,而数据可视化以更直观的方式,帮助指导决策,成为数据分析传递信 ...
- Linux基础篇,文本数据的比较与排序:sort、uniq、comm、diff
一.sort sort命令用于将文本文件内容以行排序 sort [选项参数] [-o<输出文件>] [-t<分隔字符>] [+<起始栏位> -<结束栏位> ...
- 数据结构-Python 列表(List)
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现 一.列表常用方法 1.创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可. eg:list1 = ['1', ' ...
- python中汉字转数字
#!/usr/bin/env python # -*- coding: utf-8 -*- common_used_numerals_tmp ={'零':0, '一':1, '二':2, '三':3, ...
- Atlas运行时资源不足报错 -bash: fork: retry: 资源暂时不可用 Out of system resources
目的:运行Atlas并使用Azkaban执行操作任务 环境:Centos 6 内存大小:12G 启动下面的任务后还剩内存将近5G 问题: 当mysql_to_hdfs_db和其他job同时运行时集群很 ...
- ASP.NET Core中配置监听URLs的五种方式
原文: 5 ways to set the URLs for an ASP.NET Core app 作者: Andrew Lock 译者: Lamond Lu 默认情况下,ASP. NET Core ...