rocketMq 消息偏移量 Offset
消息偏移量 Offset
 queue0 offset 0 0-20 offset 4 20-40
queue0 offset 0 0-20 offset 4 20-40
纠错:每条消息的tag对应的HashCode.
 queue1 offset 1 0-20 offset 5 20-40
queue1 offset 1 0-20 offset 5 20-40
queue2 offset 2 0-20 offset 6 20-40
queue3 offset 3 0-20 offset 7 20-40
概念
- message queue 是无限长的数组,一条消息进来下标就会涨1,下标就是 offset,消息在某个 MessageQueue 里的位置,通过 offset 的值可以定位到这条消息,或者指示 Consumer 从这条消息开始向后处理。
- message queue 中的 maxOffset 表示消息的最大 offset,maxOffset 并不是最新的那条消息的 offset,而是最新消息的 offset+1,minOffset 则是现存在的最小 offset。
- fileReserveTime=48 默认消息存储48小时后,消费会被物理地从磁盘删除,message queue 的 minOffset 也就对应增长。所以比 minOffset 还要小的那些消息已经不在 broker上了,就无法被消费
类型(父类是OffsetStore):
- 本地文件类型
- DefaultMQPushConsumer 的 BROADCASTING 广播模式,各个 Consumer 没有互相干扰,使用 LocalFileOffsetStore,把 Offset 存储在本地
- Broker 代存储类型
- DefaultMQPushConsumer 的 CLUSTERING 集群模式,由 Broker 端存储和控制 Offset 的值,使用 RemoteBrokerOffsetStore
作用
- 主要是记录消息的偏移量,有多个消费者进行消费
- 集群模式下采用 RemoteBrokerOffsetStore,broker 控制 offset 的值
- 广播模式下采用 LocalFileOffsetStore,消费端存储
建议采用 pushConsumer,RocketMQ 自动维护 OffsetStore,如果用另外一种 pullConsumer 需要自己进行维护 OffsetStore
消息存储 CommitLog
消息存储是由 ConsumeQueue 和 CommitLog 配合完成
- ConsumeQueue 是逻辑队列,CommitLog 是真正存储消息文件的,ConsumeQueue 存储的是指向物理存储的地址。Topic 下的每个 message queue 都有对应的 ConsumeQueue 文件,内容也会被持久化到磁盘。默认地址:store/consumequeue/{topicName}/{queueid}/fileName
- CommitLog:存储消息真正内容的文件。
- 生成规则:
- 每个文件的默认1G =1024 * 1024 * 1024,commitlog 的文件名 fileName,名字长度为20位,左边补零,剩余为起始偏移量;比如 00000000000000000000 代表了第一个文件,起始偏移量为0,文件大小为1G=1 073 741 824 Byte;当这个文件满了,第二个文件名字为00000000001073741824,起始偏移量为1073741824,消息存储的时候会顺序写入文件,当文件满了则写入下一个文件。
- 判断消息存储在哪个 CommitLog 上
- 例如 1073742827 为物理偏移量,则其对应的相对偏移量为 1003 = 1073742827 - 1073741824,并且该偏移量位于第二个 CommitLog。
- 生成规则:
Broker 里面一个 Topic 里面有多个 MesssageQueue,每个 MessageQueue 对应一个 ConsumeQueue,ConsumeQueue 里面记录的是消息在 CommitLog 里面的物理存储地址。
IndexFile 消息索引文件
ConsumerQueue是通过偏移量offset去CommitLog文件中查找消息,但实际工作应用中,我们想查找某条具体的消息,并不知道offset值,那该怎么办呢?那IndexFile作用就来了。
IndexFile是消息索引文件,如果一个生产者发送的消息包含key值的话,会使用IndexFile存储消息索引,主要用于使用key来查询消息。文件的内容结构如图
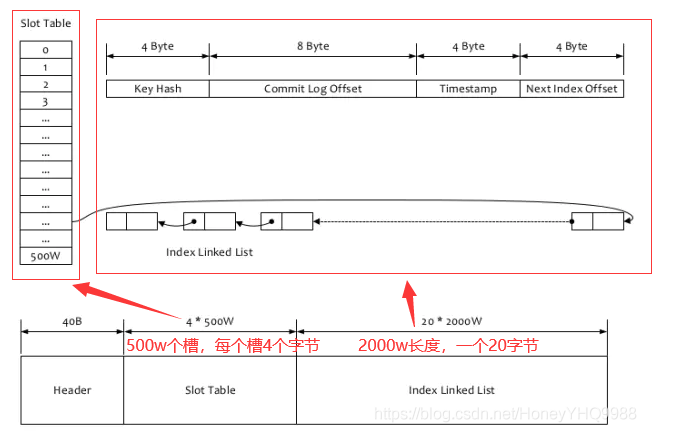
在Broker端,通过Key来计算Hash槽的位置,从而找到Index索引数据。从Index索引中拿到消息的物理偏移量,最后根据这个物理偏移量,直接到CommitLog文件中去找就可以了。另外说明下,通过IndexFile来查找消息的方法不影响RocketMQ的正常生产-消费流程,它只是查询定位消息的方法而已。
rocketMq 消息偏移量 Offset的更多相关文章
- RocketMQ之十:RocketMQ消息接收源码
1. 简介 1.1.接收消息 RebalanceService:均衡消息队列服务,负责通过MQClientInstance分配当前 Consumer 可消费的消息队列( MessageQueue ). ...
- RocketMQ(消息重发、重复消费、事务、消息模式)
分布式开放消息系统(RocketMQ)的原理与实践 RocketMQ基础:https://github.com/apache/rocketmq/tree/rocketmq-all-4.5.1/docs ...
- RocketMQ消息轨迹-设计篇
目录 1.消息轨迹数据格式 2.记录消息轨迹 3.如何存储消息轨迹数据 @(本节目录) RocketMQ消息轨迹主要包含两篇文章:设计篇与源码分析篇,本节将详细介绍RocketMQ消息轨迹-设计相关. ...
- 源码分析RocketMQ消息轨迹
目录 1.发送消息轨迹流程 1.1 DefaultMQProducer构造函数 1.2 SendMessageTraceHookImpl钩子函数 1.3 TraceDispatcher实现原理 2. ...
- RocketMQ消息丢失解决方案:同步刷盘+手动提交
前言 之前我们一起了解了使用RocketMQ事务消息解决生产者发送消息时消息丢失的问题,但使用了事务消息后消息就一定不会丢失了吗,肯定是不能保证的. 因为虽然我们解决了生产者发送消息时候的消息丢失问题 ...
- 从源码分析RocketMq消息的存储原理
rocketmq在存储消息的时候,最终是通过mmap映射成磁盘文件进行存储的,本文就消息的存储流程作一个整理.源码版本是4.9.2 主要的存储组件有如下4个: CommitLog:存储的业务层,接收& ...
- 一张图进阶 RocketMQ - 消息发送
前 言 三此君看了好几本书,看了很多遍源码整理的 一张图进阶 RocketMQ 图片链接,关于 RocketMQ 你只需要记住这张图!觉得不错的话,记得点赞关注哦. [重要]视频在 B 站同步更新,欢 ...
- RocketMq消息队列使用
最近在看消息队列框架 ,alibaba的RocketMQ单机支持1万以上的持久化队列,支持诸多特性, 目前RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,bin ...
- jacascript 偏移量offset、客户区client
前言:这是笔者学习之后自己的理解与整理.如果有错误或者疑问的地方,请大家指正,我会持续更新! 偏移量 偏移量(offset dimension)是 javascript 中的一个重要的概念.涉及到偏移 ...
随机推荐
- jmeter压测mysql数据库
jmeter连接并压测mysql数据库,之前一直想用jmeter一下测试mysql数据库的性能,今天偶然看到一篇博客,于是乎开始自己动手实践. 一.准备工作 1.安装好mysql数据库,可以安装在本地 ...
- 完全图的最短Hamilton路径——状压dp
题意:给出一张含有n(n<20)个点的完全图,求从0号节点到第n-1号节点的最短Hamilton路径.Hamilton路径是指不重不漏地经过每一个点的路径. 算法进阶上的一道状压例题,复杂度为O ...
- 关于uniapp无法navigateTo跳转的解决办法
今天在分包时突然无法跳转了,记个笔记 场景: 位于tabbar页面(主包)的子组件跳转到分包页面时,无法跳转 尝试办法: 使用uniapp原生跳转 uni.navigateTo({ url:'xxxx ...
- LinuxKernel(一)
首先,回顾一下基础的宏操作: C语言宏 #与## #的作用是字符串化:在一个宏中的参数前面使用一个#,预处理器会把这个参数转换为一个字符数组 #define ERROR_LOG(info) fprin ...
- mininet + opendaylight环境配置
环境配置 ubuntu18.04 镜像 mininet2.2.2 apt-get install mininet 但这种安装只是TLS版本的mininet,与最新版本在功能上有所差距. 控制器(ope ...
- unittest框架中读取有特殊符号的配置文件内容的方法-configparser的RawConfigParser类应用
在搭建Unittest框架中,出现了一个问题,配置文件.ini中,出现了特殊字符如何处理? 通过 1.configparser的第三方库对应的ConfigParser类,无法完成对特殊字符的读取: # ...
- model基础操作
url.py from django.contrib import admin from django.urls import path,include from app1.views import ...
- 深度优先遍历&广度优先遍历
二叉树的前序遍历,中序遍历,后序遍历 树的遍历: 先根遍历--访问根结点,按照从左至右顺序先根遍历根结点的每一颗子树. 后根遍历--按照从左至右顺序后根遍历根结点的每一颗子树,访问根结点. 先根:AB ...
- 对称加密之---AES加密
工作中常会需要让数据传输前进行加密处理.这次用到的是AES加密.AES加密中,需要注意到坑还是挺多的.对AES也进行了一番了解,发现里面的东西真的是注意的太多了.今天只是整理了一种简单的加密格式,工作 ...
- 音视频处理基础知识扫盲:数字视频YUV像素表示法以及视频帧和编解码概念介绍
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一. ...