Flink-v1.12官方网站翻译-P013-Timely Stream Processing
及时的流处理

介绍
及时流处理是有状态流处理的一种扩展,其中时间在计算中起着一定的作用。其中,当你做时间序列分析时,当做基于某些时间段(通常称为窗口)的聚合时,或者当你做事件处理时,事件发生的时间很重要时,都是这种情况。
在下面的章节中,我们将着重介绍一些您在使用及时Flink应用时应该考虑的主题。
时间概念:事件时间和处理时间
当在流程序中提到时间时(例如定义窗口),可以提到不同的时间概念。
- 处理时间。处理时间指的是正在执行相应操作的机器的系统时间。
当流程序在处理时间上运行时,所有基于时间的操作(如时间窗口)将使用运行各操作的机器的系统时钟。一个小时的处理时间窗口将包括在系统时钟指示整小时的时间之间到达特定操作者的所有记录。例如,如果一个应用程序在上午9:15开始运行,则第一个小时处理时间窗口将包括上午9:15到10:00之间处理的事件,下一个窗口将包括上午10:00到11:00之间处理的事件,以此类推。
处理时间是最简单的时间概念,不需要流和机器之间的协调。它提供了最好的性能和最低的延迟。然而,在分布式和异步环境中,处理时间并不能提供确定性,因为它很容易受到记录到达系统的速度(例如从消息队列)、记录在系统内部的操作员之间流动的速度以及中断(计划性的或其他)的影响。
- 事件时间。事件时间是指每个事件在其生产设备上发生的时间。这个时间通常在记录进入Flink之前就被嵌入到记录中,该事件时间戳可以从每个记录中提取出来。在事件时间中,时间的进展取决于数据,而不是任何挂钟。事件时间程序必须指定如何生成事件时间水印,这是事件时间中信号进度的机制。这个水印机制将在后面的章节中描述,下面。
在一个完美的世界里,事件时间处理将产生完全一致和确定的结果,不管事件何时到达,或它们的顺序如何。然而,除非已知事件是按顺序到达的(通过时间戳),否则事件时间处理在等待失序事件时就会产生一些延迟。由于只能在有限的时间内等待,这就对事件时间应用的确定性施加了限制。
假设所有的数据都已经到达,事件时间操作将按照预期的方式进行,即使在处理失序或迟到的事件时,或者在重新处理历史数据时,也能产生正确和一致的结果。例如,每小时事件时间窗口将包含所有携带事件时间戳的记录,这些记录属于该小时,无论它们到达的顺序如何,也无论它们何时被处理。(更多信息请参见晚期事件一节。)请注意,有时事件时间程序在实时处理实时数据时,会使用一些处理时间操作,以保证其及时进行。

事件时间和水印
注:Flink实现了Dataflow模型中的许多技术。关于事件时间和水印的介绍,可以看看下面的文章。
- Tyler Akidau的《流媒体101》。
- 数据流模型文件
一个支持事件时间的流处理器需要一种方法来测量事件时间的进度。例如,当事件时间已经超过一小时结束时,需要通知建立小时窗口的窗口操作员,以便操作员可以关闭正在进行的窗口。
事件时间的进展可以独立于处理时间(由挂钟测量)。例如,在一个程序中,操作者的当前事件时间可能略微落后于处理时间(考虑到接收事件的延迟),而两者以相同的速度进行。另一方面,另一个流程序可能通过快进一些已经缓冲在Kafka主题(或另一个消息队列)中的历史数据,只用几秒钟的处理时间就可以完成几周的事件时间的进展。
Flink中衡量事件时间进度的机制是水印。水印作为数据流的一部分流动,并携带一个时间戳t,一个Watermark(t)声明该数据流中的事件时间已经达到了时间t,也就是说该数据流中不应该再有时间戳t'<=t的元素(即事件的时间戳大于或等于水印)。
下图显示了一个带有(逻辑)时间戳的事件流,以及水印的内联流。在这个例子中,事件是按顺序排列的(相对于它们的时间戳),这意味着水印只是流中的周期性标记。
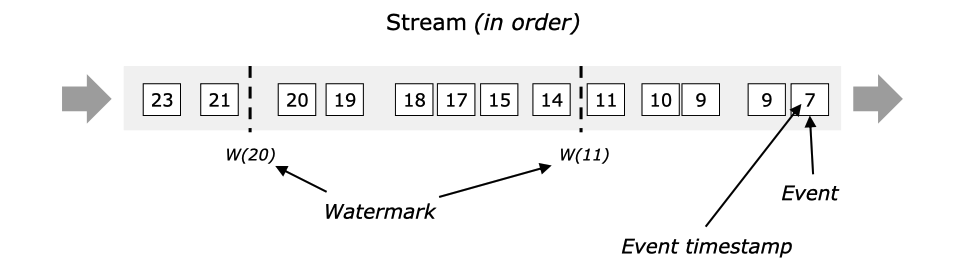
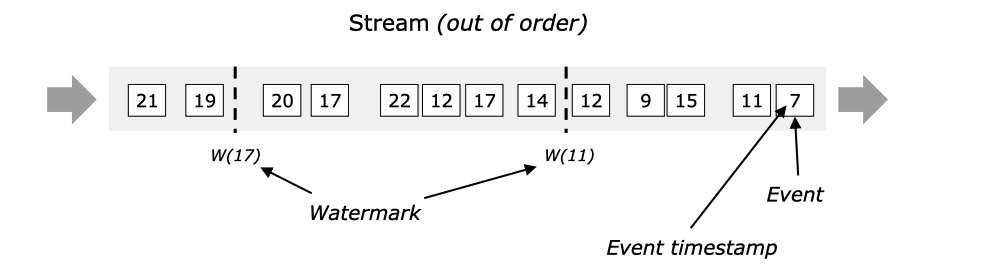
水印对于无序流来说是至关重要的,如下图所示,在这种情况下,事件不是按照时间戳来排序的。一般来说,水印是一种声明,即在流中的那一点上,所有事件在某个时间戳之前都应该已经到达。一旦水印到达操作者,操作者可以将其内部事件时间时钟提前到水印的值。
请注意,事件时间是由一个新创建的流元素(或元素)从产生它们的事件或从触发创建这些元素的水印继承的。
并行流的水印
水印是在源函数处或直接在源函数后生成的。源函数的每个并行子任务通常都会独立地生成其水印。这些水印定义了该特定并行源的事件时间。
当水印流经流程序时,它们会在它们到达的操作符处提前事件时间。每当一个操作者提前其事件时间时,它就会在下游为其后续操作者生成一个新的水印。
有些运算符会消耗多个输入流;例如,一个联合,或者在keyBy(...)或partition(...)函数之后的运算符。这种运算符的当前事件时间是其输入流事件时间的最小值。当它的输入流更新它们的事件时间时,该运算符也会更新。
下图显示了事件和水印在并行流中流动的例子,以及运算符跟踪事件时间的例子。

延时
某些元素有可能会违反水印条件,也就是说,即使在水印(t)发生后,也会有更多时间戳t'<=t的元素发生。事实上,在许多现实世界的设置中,某些元素可以任意延迟,这使得无法指定某个事件时间戳的所有元素在什么时候发生。此外,即使延迟时间可以被限定,但延迟水印的时间过长往往是不可取的,因为它对事件时间窗口的评估造成过多的延迟。
出于这个原因,流媒体程序可能会显式地期望一些迟到的元素。晚期元素是指在系统的事件时间时钟(由水印发出的信号)已经过了晚期元素的时间戳之后到达的元素。有关如何在事件时间窗口中处理迟到元素的更多信息,请参见允许迟到。
窗口
聚合事件(如计数、求和)在流上的工作方式与批处理中的工作方式不同。例如,不可能对一个流中的所有元素进行计数,因为流一般是无限的(无边界的)。相反,流上的聚合(计数、求和等)是由窗口来限定范围的,比如 "过去5分钟的计数",或者 "过去100个元素的总和"。
窗口可以是时间驱动的(例如:每30秒),也可以是数据驱动的(例如:每100个元素)。人们通常会区分不同类型的窗口,如翻滚窗口(无重叠)、滑动窗口(有重叠)和会话窗口(以不活动的间隙为点)。

请查看这篇博客文章,了解更多的窗口示例,或查看DataStream API的窗口文档。
Flink-v1.12官方网站翻译-P013-Timely Stream Processing的更多相关文章
- Flink-v1.12官方网站翻译-P008-Streaming Analytics
流式分析 事件时间和水印 介绍 Flink明确支持三种不同的时间概念. 事件时间:事件发生的时间,由产生(或存储)该事件的设备记录的时间 摄取时间:Flink在摄取事件时记录的时间戳. 处理时间:您的 ...
- Flink-v1.12官方网站翻译-P022-Working with State
有状态程序 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 带键值的数据流 如果要使用键控状态,首 ...
- Flink-v1.12官方网站翻译-P021-State & Fault Tolerance-overview
状态和容错 在本节中,您将了解Flink为编写有状态程序提供的API.请看一下Stateful Stream Processing来了解有状态流处理背后的概念. 下一步去哪里? Working wit ...
- Flink-v1.12官方网站翻译-P010-Fault Tolerance via State Snapshots
通过状态快照进行容错 状态后台 Flink管理的键控状态是一种碎片化的.键/值存储,每项键控状态的工作副本都被保存在负责该键的任务管理员的本地某处.操作员的状态也被保存在需要它的机器的本地.Flink ...
- Flink-v1.12官方网站翻译-P007-Data Pipelines & ETL
数据管道和ETL 对于Apache Flink来说,一个非常常见的用例是实现ETL(提取.转换.加载)管道,从一个或多个源中获取数据,进行一些转换和/或丰富,然后将结果存储在某个地方.在这一节中,我们 ...
- Flink-v1.12官方网站翻译-P005-Learn Flink: Hands-on Training
学习Flink:实践培训 本次培训的目标和范围 本培训介绍了Apache Flink,包括足够的内容让你开始编写可扩展的流式ETL,分析和事件驱动的应用程序,同时省略了很多(最终重要的)细节.本书的重 ...
- Flink-v1.12官方网站翻译-P025-Queryable State Beta
可查询的状态 注意:可查询状态的客户端API目前处于不断发展的状态,对所提供接口的稳定性不做保证.在即将到来的Flink版本中,客户端的API很可能会有突破性的变化. 简而言之,该功能将Flink的托 ...
- Flink-v1.12官方网站翻译-P002-Fraud Detection with the DataStream API
使用DataStream API进行欺诈检测 Apache Flink提供了一个DataStream API,用于构建强大的.有状态的流式应用.它提供了对状态和时间的精细控制,这使得高级事件驱动系统的 ...
- Flink-v1.12官方网站翻译-P015-Glossary
术语表 Flink Application Cluster Flink应用集群是一个专用的Flink集群,它只执行一个Flink应用的Flink作业.Flink集群的寿命与Flink应用的寿命绑定. ...
- Flink-v1.12官方网站翻译-P004-Flink Operations Playground
Flink操作训练场 在各种环境中部署和操作Apache Flink的方法有很多.无论这种多样性如何,Flink集群的基本构件保持不变,类似的操作原则也适用. 在这个操场上,你将学习如何管理和运行Fl ...
随机推荐
- [ABP教程]第四章 集成测试
Web应用程序开发教程 - 第三章: 集成测试 //[doc-params] { "UI": ["MVC","NG"], "DB& ...
- DHCP.md
DHCP 主配置文件 从 /usr/share/doc/dhcp 复制 dhcpd.conf.sample 到/etc/dhcp下 ...
- PHP SDK短信接口
/** * sdk 短信接口 * @param $tel 手机号 * @param $content 短信内容 * @return bool */ public function telSDK($te ...
- Python作业---内置数据类型
实验2 内置数据类型 实验性质:验证性 一.实验目的 1.掌握内置函数.列表.切片.元组的基本操作: 2.掌握字典.集合和列表表达式的基本操作. 二.实验预备知识 1.掌握Python内置函数的基/本 ...
- .NET 云原生架构师训练营(模块二 基础巩固 敏捷开发)--学习笔记
2.7.1 敏捷开发 敏捷介绍 敏捷的起源 敏捷软件开发宣言 敏捷开发十二原则 生命周期对比 敏捷开发的特点 敏捷的发展 敏捷的核心 敏捷的起源 2001年,17个老头子在一起一边滑雪,一边讨论工作, ...
- selenium自动化 | 借助百度AI开放平台识别验证码登录职教云
#通过借助百度AI开放平台识别验证码登录职教云 from PIL import Image from aip import AipOcr import unittest # driver.get(zj ...
- Desired_Capabilities配置
appium服务器初始化参数 最全: https://github.com/appium/appium/blob/master/docs/cn/writing-running-appium/caps. ...
- CPNDet:粗暴地给CenterNet加入two-stage精调,更快更强 | ECCV 2020
本文为CenterNet作者发表的,论文提出anchor-free/two-stage目标检测算法CPN,使用关键点提取候选框再使用两阶段分类器进行预测.论文整体思路很简单,但CPN的准确率和推理速度 ...
- 深入理解Redis之简单动态字符串
目录 SDS SDS与C字符串的区别 SDS获取字符串长度复杂度为O(1),C字符串为O(N) SDS杜绝了缓存区溢出 减少修改字符串时带来的内存重分配次数 二进制安全 Redis没有直接使用C语言传 ...
- SDUST数据结构 - chap3 栈和队列
一.判断题: 二.选择题: 三.编程题: 7-1 一元多项式求导: 输入样例: 3 4 -5 2 6 1 -2 0 输出样例: 12 3 -10 1 6 0 代码: #include<bits/ ...