ElasticSearch教程——分片、扩容以及容错机制(转学习使用)
一、Primary shard和replica shard机制
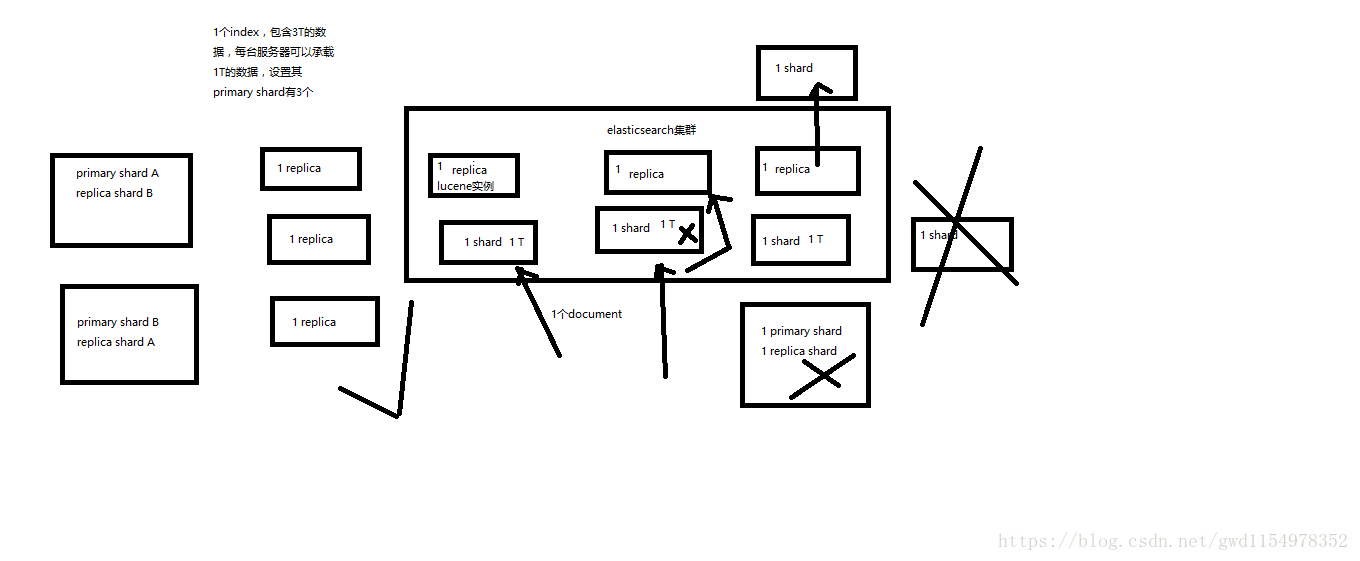
1、index包含多个shard;
2、每个shard都是一个最小的工作单元,承载部分的数据,Lucene实例,完整的简历索引和处理请求的能力;
3、增减节点时,shard会自动在nodes中负载均衡;
4、primary shard和replica shard,每一个document只会存在某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard中;
5、replica shard是primary shard的副本,负责容错,以及承担读请求负载(通常情况下可以让primary shard负责写,replica shard负责读,来实现读写分离)
6、primary shard的数量在创建的时候就固定了,replica shard的数量可以随时修改;
7、primary shard的默认数量是5,replica shard是1,默认有10个shard;其中5个primary shard以及5个replica shard;
8、primary shard和replica shard不能和自己的replica shard 放在一个节点中(这样规定是为避免节点宕机的时候,primary shard和replica shard数据都都丢失,起不到容错的作用),但是可以和其他的primary shard的replica shard放在同一个节点中;
三、性能扩容
就像上面说的primary shard 在创建的时候就已经固定了,不可以再修改。也就是说如果我在创建的时候设置了primary shard是3(6个shard,3 primary,3 replica),最多扩容到6台机器,每个shard可以占用单台服务器的所有资源,性能最好。那如果我们的超出了上面所说的扩容极限了怎么办呢?primary shard不是不能修改么?
是的,primary shard 在创建后是不能修改的,但是replica shard可以添加啊,我们可以创建9个shard(3primary,6 replica),将服务器扩容到9台机器,吞吐量会大大增加,是3台服务器的三倍,当然为了提高容错率也可以在此基础上在每台服务器上部署多个shard(primary和replica不能在同一台服务器上)
四、容量扩容
上述的扩容指的是性能上的扩容(即高可用),但是在实际生活中可能会面临需要内存上扩容,他的极限就是每个primary shard部署单台服务器(3个primary shard分别部署3台服务器),所以在创建的时候自己要注意创建primary shard的数量,如果内存上问题还是不能解决,那么就需要通过扩容磁盘和定期清理数据来解决内存问题了
五、容错机制
master node宕机后,会自动重新选举master,此时为red;
replica容错:新master是将replica提升为primary shard,此时为yellow(因为replica被升级为primary了,此时replica并不齐全);
重启宕机node,master copy replica到该node,但是该node使用原有的shard并同步宕机后的修改(即仅同步宕机后丢失的数据),此时为green;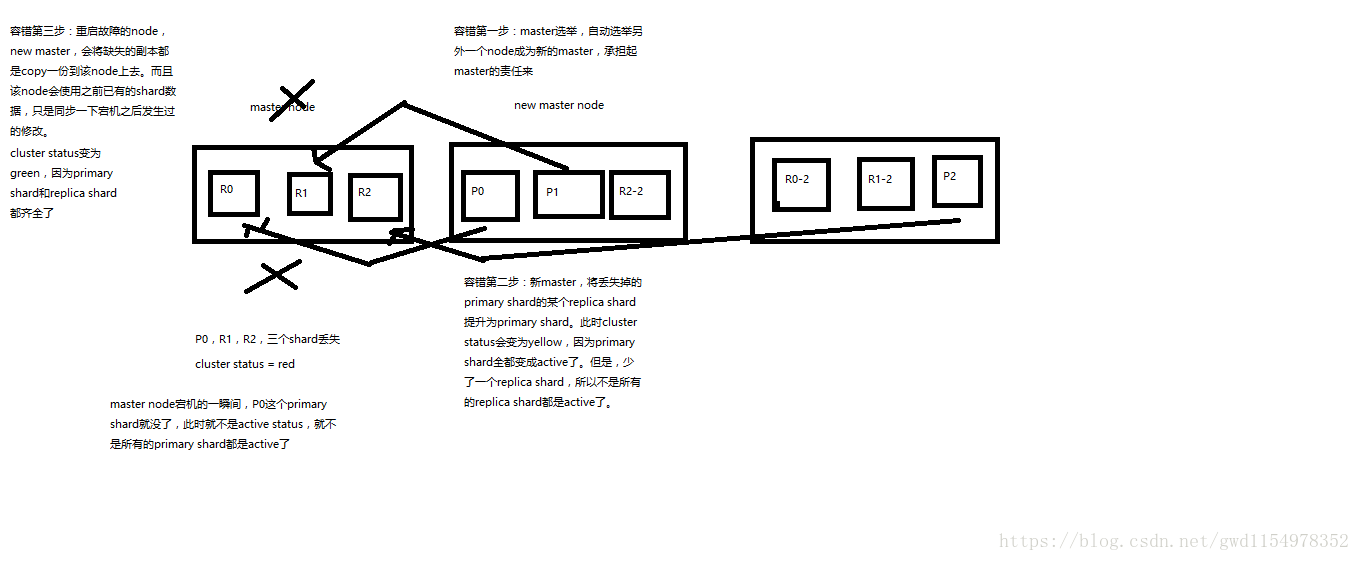
!
ElasticSearch教程——分片、扩容以及容错机制(转学习使用)的更多相关文章
- Elasticsearch由浅入深(二)ES基础分布式架构、横向扩容、容错机制
Elasticsearch的基础分布式架构 Elasticsearch对复杂分布式机制的透明隐藏特性 Elasticsearch是一套分布式系统,分布式是为了应对大数据量. Elasticsearch ...
- Elasticsearch 横向扩容以及容错机制
写在前面的话:读书破万卷,编码如有神-------------------------------------------------------------------- 参考内容: <Ela ...
- ElasticSearch教程——filter与query对比(转学习使用)
一.数据准备 PUT /company/employee/2 { "address": { "country": "china", &quo ...
- Elasticsearch和HDFS 容错机制 备忘
1.Elasticsearch 横向扩容以及容错机制http://www.bubuko.com/infodetail-2499254.html 2.HDFS容错机制详解https://www.cnbl ...
- (转)ElasticSearch教程——汇总篇
https://blog.csdn.net/gwd1154978352/article/details/82781731 环境搭建篇 ElasticSearch教程——安装 ElasticSearch ...
- ElasticSearch 分布式及容错机制
1 ElasticSearch分布式基础 1.1 ES分布式机制 分布式机制:Elasticsearch是一套分布式的系统,分布式是为了应对大数据量.它的特性就是对复杂的分布式机制隐藏掉. 分片机制: ...
- elasticsearch从入门到出门-08-Elasticsearch容错机制:master选举,replica容错,数据恢复
假如: 9 shard,3 node Elasticsearch容错机制:master选举,replica容错,数据恢复 最佳分配情况: 这样分配之后,不管其中哪个node 宕机这个es 依然可以提供 ...
- 第二章·Elasticsearch内部分片及分片处理机制介绍
一.副本分片介绍 什么是副本分片? 副本分片的主要目的就是为了故障转移,如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色. 在索引写入时,副本分片做着与主分片相同的工作.新文档首先被索引 ...
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
随机推荐
- 第15.29节 PyQt(Python+Qt)入门学习:containers容器类部件QScrollArea滚动区域详解
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 Scroll Area提供了一个呈现在其他部件上的可滚动区域视图,滚动区域用于显示框架内的 ...
- 第二十章、QTableView与QStandardItemModel开发实战:展示Excel文件内容
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 在前面<第十九章.Model/View开发:QTableView的功能及属性> ...
- Python基础知识学习随笔
Python学习随笔:PyCharm的错误检测使用及调整配置减少错误数量 Python学习随笔:获取当前主机名和用户名的方法 博客地址:https://blog.csdn.net/LaoYuanPyt ...
- flask注册蓝图报错
记录下这个我找了两天的坑... take no arguments() 这两天一直学习flask的时候,我把注册的蓝图,写成注册的form表单的 举个栗子 class TetsView(view.Me ...
- Java程序员需要了解的底层知识(一)
硬件基础知识 - Java相关硬件 汇编语言的执行过程(时钟发生器 寄存器 程序计数器) 计算机启动过程 进程线程纤程的基本概念面试高频 - 纤程的实现 内存管理 进程管理与线程管理(进程与线程 ...
- sql server的bcp指令
有时需要允许bcp指令 -- 允许配置高级选项EXEC sp_configure 'show advanced options', 1GO-- 重新配置RECONFIGUREGO-- 启用xp_cmd ...
- Docker(一):Docker安装
简介 Docker是dotcloud公司开源的一款产品,主要基于PAAS平台为开发者提供服务.是解决运行环境和配置问题软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术. Docker组件 ...
- Spark性能调优篇八之shuffle调优
1 task的内存缓冲调节参数 2 reduce端聚合内存占比 spark.shuffle.file.buffer map task的内存缓冲调节参数,默认是3 ...
- 记一次 oracle 数据库在宕机后的恢复
系统:redhat 6.6 oracle版本: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production 问题描述: ...
- 最新 obs-studio vs2019 开发环境搭建 代码编译
距离上一篇文章很久了,重新开始记录 OBS 开发相关情况,第一步就是环境搭建,第二步是构建 OBS-Studio VS 2019 开发环境搭建 下载软件和资源 软件安装没有特别说明的,下载安装即可. ...