Java实现的二叉堆以及堆排序详解
一、前言
二叉堆是一个特殊的堆,其本质是一棵完全二叉树,可用数组来存储数据,如果根节点在数组的下标位置为1,那么当前节点n的左子节点为2n,有子节点在数组中的下标位置为2n+1。二叉堆类型分为最大堆(大顶堆)和最小堆(小顶堆),其分类是根据父节点和子节点的大小来决定的,在二叉堆中父节点总是大于或等于子节点,该二叉堆成为最大堆,相反地称之为最小堆。因此,最大堆父节点键值大于或等于子节点,最小堆父节点键值小于或等于子节点。根据二叉堆的特点,二叉堆可以用来实现排序、有限队列等。堆排序就是利用二叉堆的特性来实现的。二叉堆数据结构如下:
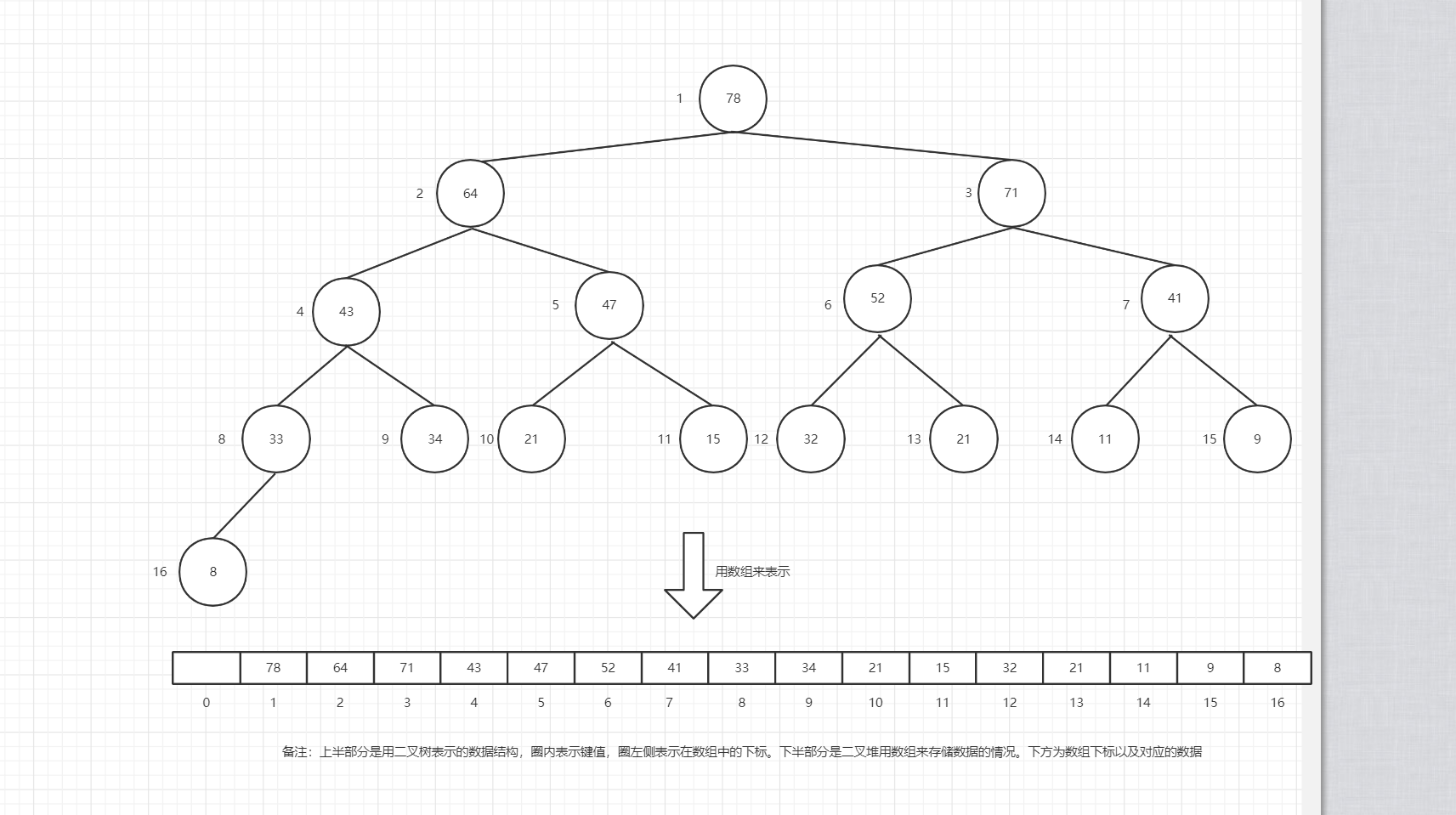
二、相关概念
(一)、树
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。一棵树(tree)是由n(n>0)个元素组成的有限集合,其中:
(二)、二叉树
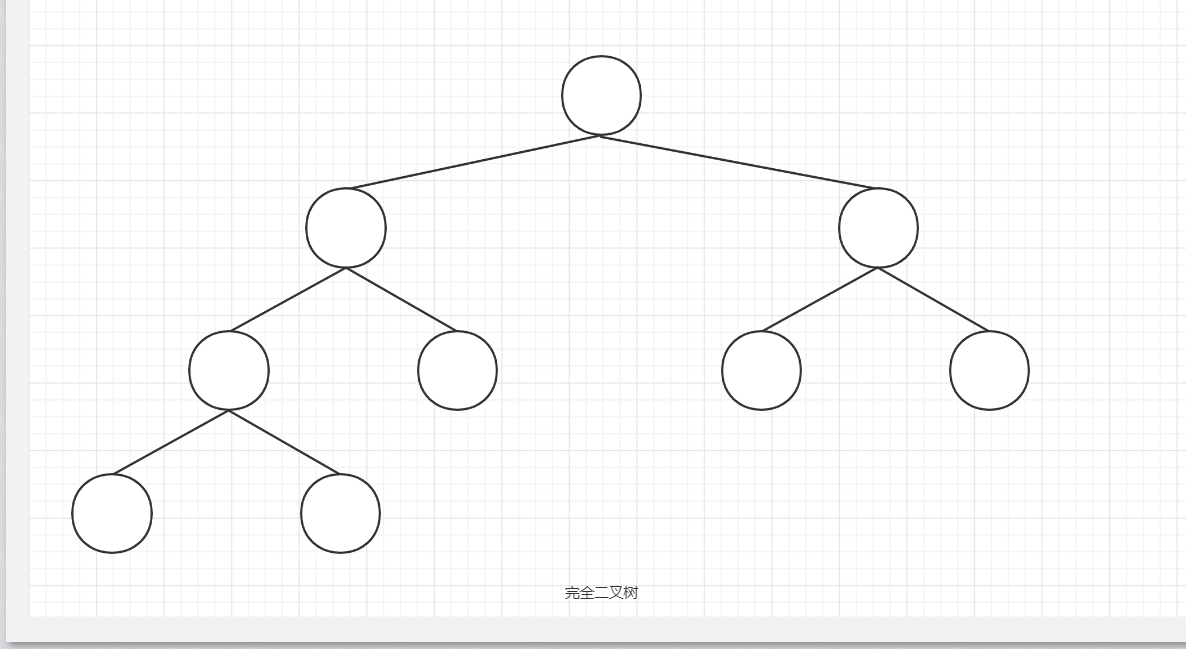
1、完全二叉树
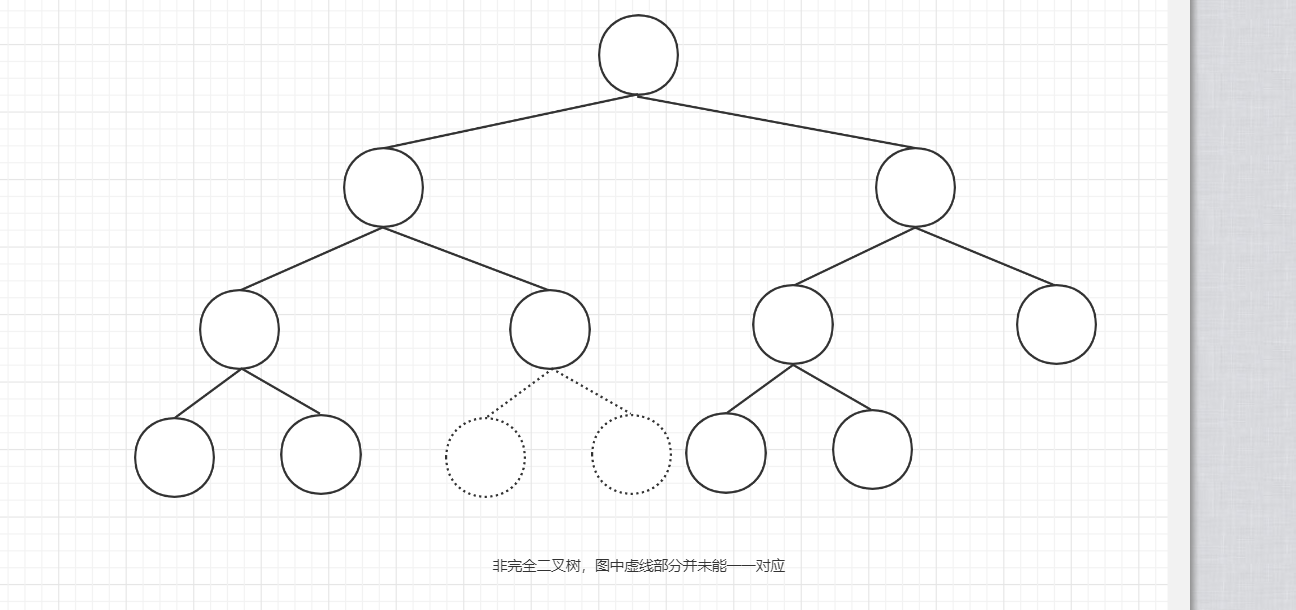
非完全二叉树
三、二叉堆插入节点和删除节点
(一)、插入节点
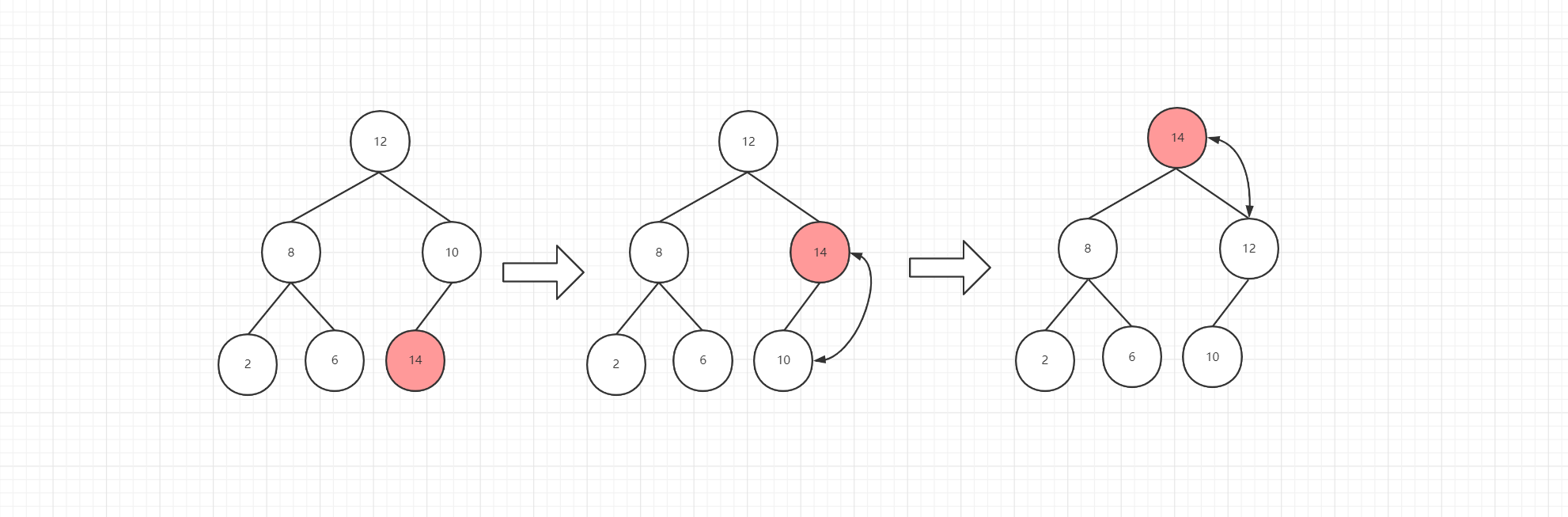
思路:因为二叉堆是用数组来存储数据的,所以每次插入节点时,实际是往数组数据尾部增加数据。但是,如果直接往尾部放数据,有可能破坏【父节点键值大于或等于子节点】的特性,因此,每次插入数据时都需要将二叉堆从新堆化的操作。堆化过程就是插入节点和父节的键值进行比较,如果父节点键值小于插入节点,则需要将两个节点进行交换,然后继续向上比较,直至父节点不小于插入节点或到达根节点。流程图如下:
代码实现如下:
/**
* 插入节点
* @param value 键值
* @return 成功或失败
*/
public boolean put(int value) {
/**
* 数组已满
*/
if (size > capacity) {
return false;
}
//直接将新节点插入到数据尾部
data[size] = value;
//插入节点后不满足二叉堆特性,需要重新堆化
maxHeapify(size++);
return true;
} /**
* 大顶堆堆化
* @param pos 堆化的位置
*/
private void maxHeapify(int pos) {
/**
* parent 堆化位置的父节点;计算公式:父节点=子节点*2
* 向上堆化过程
*/
for (int parent = pos >> 1;parent > 0 && data[parent] < data[pos];pos = parent,parent = parent >> 1) {
swap(parent,pos);
}
} /**
* 数组数据交换
* @param i 下标
* @param j 下标
*/
private void swap(int i,int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
测试结果如下: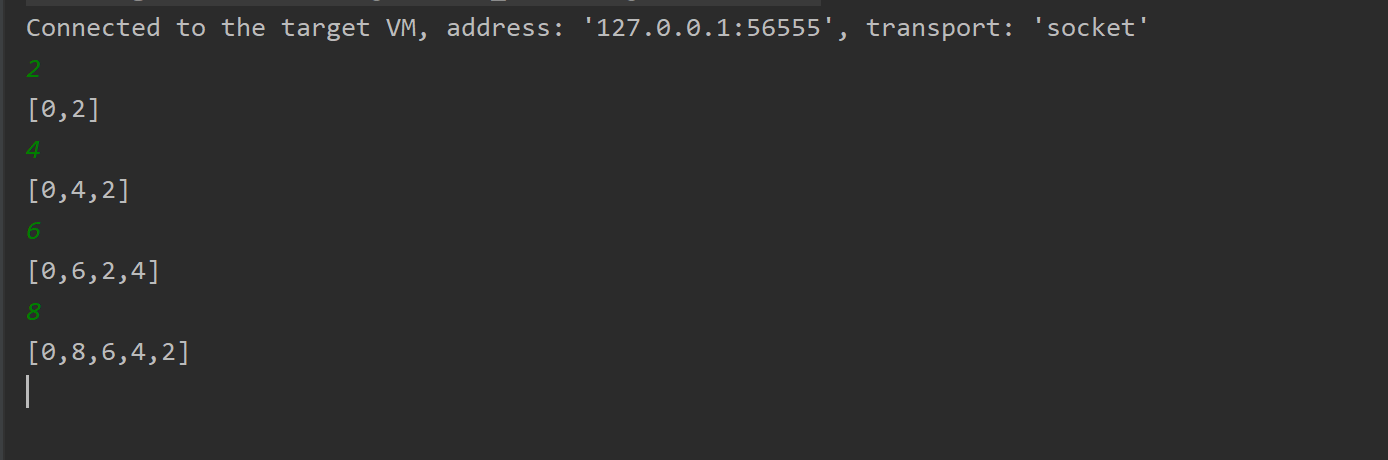
(二)、删除节点
删除节点主要用于堆排序的功能,因为每次删除节点时都是删除堆顶节点(即最大值或最小值),当整个二叉堆删除完成就可以得到一个有序的数组或列表。堆删除节点一般都是删除根节点,根节点被删除后该树就不满足二叉堆的特性,所以需要重新调整堆,使之成为一个真正的二叉堆。调整堆结构有多种方式,我这里说的是一种比较简便,高效的方式。大致的思路:将堆顶节点和最后一个节点交换,然后删除最后一个节点。交换节点键值后就不满足二叉堆的特性了,所以需要重新调整。根节点为父节点,与两个子节点键值进行比较,找到键值最大的节点后交换父节点和该节点的位置。位置交换后以最大值所在节点看作父节点,继续与子节点比较。当父节点均大于子节点或到达叶子节点时,即完成堆化过程。流程图如下: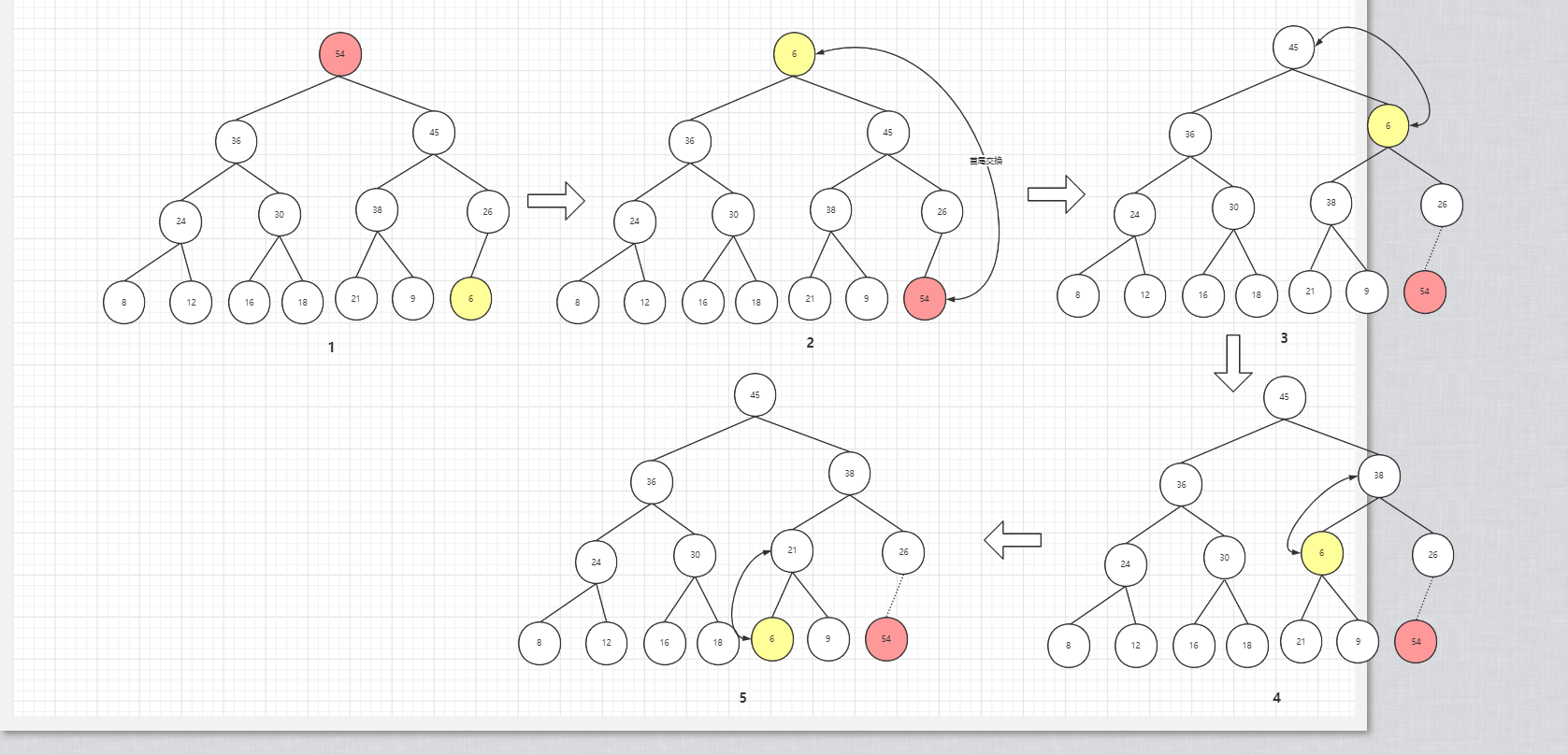
通过上面的4个步骤后就可以将堆顶元删除掉。具体代码实现如下:
/**
* 删除元素
* @return
*/
public int remove() {
int max = data[1];
if (size < 1) {
return -1;
}
swap(1,size);
size--;
shiftDown(1);
return max;
} /**
* 自上而下重新调整二叉堆
* @param pos 开始调整位置
*/
private void shiftDown(int pos) {
int left = pos << 1;
int right = left + 1;
int maxPos = pos;
if (left <= size && data[left] > data[maxPos]) {
maxPos = left;
}
if (right <= size && data[right] > data[maxPos]) {
maxPos = right;
}
if (pos == maxPos) {
return;
}
swap(pos,maxPos);
shiftDown(maxPos);
}
测试结果:
public static void main(String[] args) {
Heap heap = new Heap(5);
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()) {
String next = scanner.next();
if (next.equalsIgnoreCase("r")) {
heap.remove();
}else {
heap.put(Integer.parseInt(next));
}
System.out.println(heap.toString());
}
}
//打印结果
1
[1]
2
[2,1]
3
[3,1,2]
4
[4,3,2,1]
5
[5,4,2,1,3]
r
[4,3,2,1]
r
[3,1,2]
r
[2,1]
r
[1]
r
[]
完成代码:
/**
* @className: Heap
* @description: 堆
* @author: rainple
* @create: 2020-09-01 15:39
**/
public class Heap { /**
* 数组容量
*/
private int capacity;
/**
* 数据大小
*/
private int size;
/**
* 数据
*/
private int[] data; public Heap(int capacity) {
if (capacity <= 0) {
throw new IllegalArgumentException("参数非法");
}
this.capacity = capacity;
data = new int[capacity + 1];
} /**
* 插入节点
* @param value 键值
* @return 成功或失败
*/
public boolean put(int value) {
/**
* 数组已满
*/
if (size + 1 > capacity) {
return false;
}
//直接将新节点插入到数据尾部
data[++size] = value;
//插入节点后不满足二叉堆特性,需要重新堆化
maxHeapify(size);
return true;
} /**
* 大顶堆堆化
* @param pos 堆化的位置
*/
private void maxHeapify(int pos) {
/**
* parent 堆化位置的父节点;计算公式:父节点=子节点*2
* 向上堆化过程
*/
for (int parent = pos >> 1;parent > 0 && data[parent] < data[pos];pos = parent,parent = parent >> 1) {
swap(parent,pos);
}
} /**
* 删除元素
* @return
*/
public int remove() {
int max = data[1];
if (size < 1) {
return -1;
}
swap(1,size);
size--;
shiftDown(1);
return max;
} /**
* 自上而下重新调整二叉堆
* @param pos 开始调整位置
*/
private void shiftDown(int pos) {
int left = pos << 1;
int right = left + 1;
int maxPos = pos;
if (left <= size && data[left] > data[maxPos]) {
maxPos = left;
}
if (right <= size && data[right] > data[maxPos]) {
maxPos = right;
}
if (pos == maxPos) {
return;
}
swap(pos,maxPos);
shiftDown(maxPos);
} /**
* 数组数据交换
* @param i 下标
* @param j 下标
*/
private void swap(int i,int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
} @Override
public String toString() {
if (size == 0) {
return "[]";
}
StringBuilder builder = new StringBuilder("[");
for (int i = 1; i < size + 1; i++) {
builder.append(data[i]).append(",");
}
return builder.deleteCharAt(builder.length() - 1).append("]").toString();
}
}
四、堆排序
(一)、算法实现
堆排序是利用了堆这种数据结构的特性而设计出来的高效的排序算法。算法实现也并不是很难,排序的过程就是将堆顶元素与最后一个元素交换的过程,每次交换后都需要进行一次堆结构使之成为一颗新的二叉堆。其实,排序的过程类似与我们上面讲到的删除节点的过程,每进行一次删除操作,都会将根节点(最大值或最小值)放在当前堆对应的数组的最后一个位置,当所有节点都进行一次删除后即可得到一个有序的数组,如果大顶堆最后数组的正序排序,小顶堆则是倒叙排序。下面我使用图例来演示排序的过程,因为过程中涉及到堆化过程而且上面也演示过了,所以下面只演示初始和结束两个状态: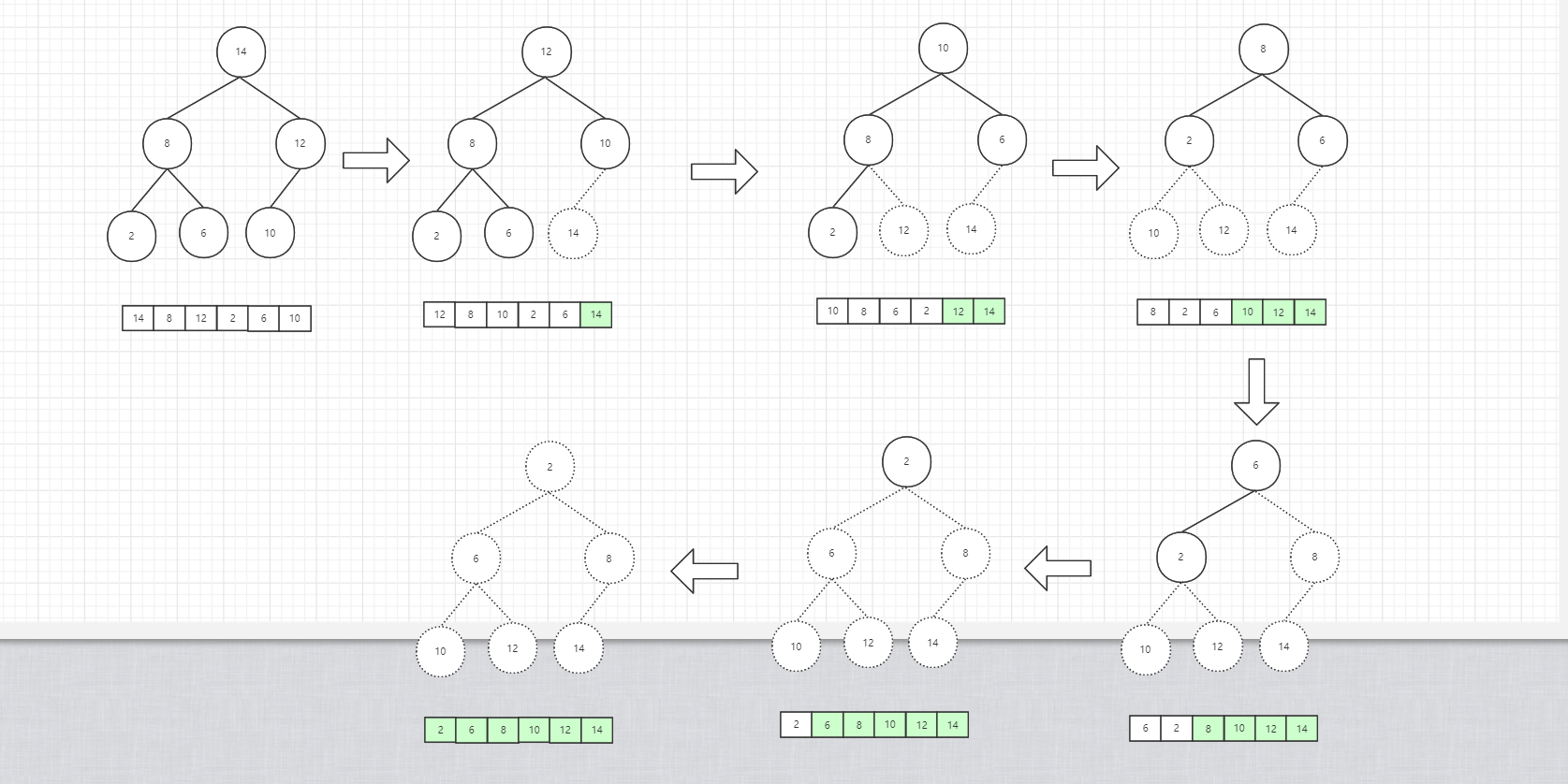
代码实现如下:
public static void sort(int[] data) {
int len = data.length - 1;
//将数组构建成一颗二叉堆
build(data,len);
while (len > 0) {
//数组第一个元素和二叉堆中最后一个元素交换位置
swap(data,0,len);
//堆化
heapify(data,0,--len);
}
}
/**
* 建堆
* @param data 数据
* @param len 长度
*/
private static void build(int[] data,int len){
for (int i = len >> 1;i >= 0;i--) {
heapify(data,i,len);
}
}
/**
* 堆化
* @param data 数据
* @param start 开始位置
* @param end 结束位置
*/
private static void heapify(int[] data,int start,int end){
while (true){
int max = start;
int left = max << 1;
int right = left + 1;
if (left <= end && data[max] < data[left]) {
max = left;
}
if (right <= end && data[max] < data[right]){
max = right;
}
if (max == start) {
break;
}
swap(data,start,max);
start = max;
}
}
/**
* 将data数组中i和j的数据互换
* @param data 数据
* @param i 下标
* @param j 下标
*/
private static void swap(int[] data,int i,int j){
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
(二)、堆排序时间复杂度
堆排序时间复杂度需要计算初始化堆和重建堆的时间复杂度。
初始化堆的复杂度:假如有N个节点,那么高度为H=logN,最后一层每个父节点最多只需要下调1次,倒数第二层最多只需要下调2次,顶点最多需要下调H次,而最后一层父节点共有2^(H-1)个,倒数第二层公有2^(H-2),顶点只有1(2^0)个,所以总共的时间复杂度为s = 1 * 2^(H-1) + 2 * 2^(H-2) + ... + (H-1) * 2^1 + H * 2^0;将H代入后s= 2N - 2 - log2(N),近似的时间复杂度就是O(N)。
重建堆时间复杂度:循环 n -1 次,每次都是从根节点往下循环查找,所以每一次时间是 logn,总时间:logn(n-1) = nlogn - logn
综上所述,堆排序的时间复杂度为 O(nlogn)
(三)、堆排序时间测试
生成100万个随机数进行排序,排序总花费时间为:280毫秒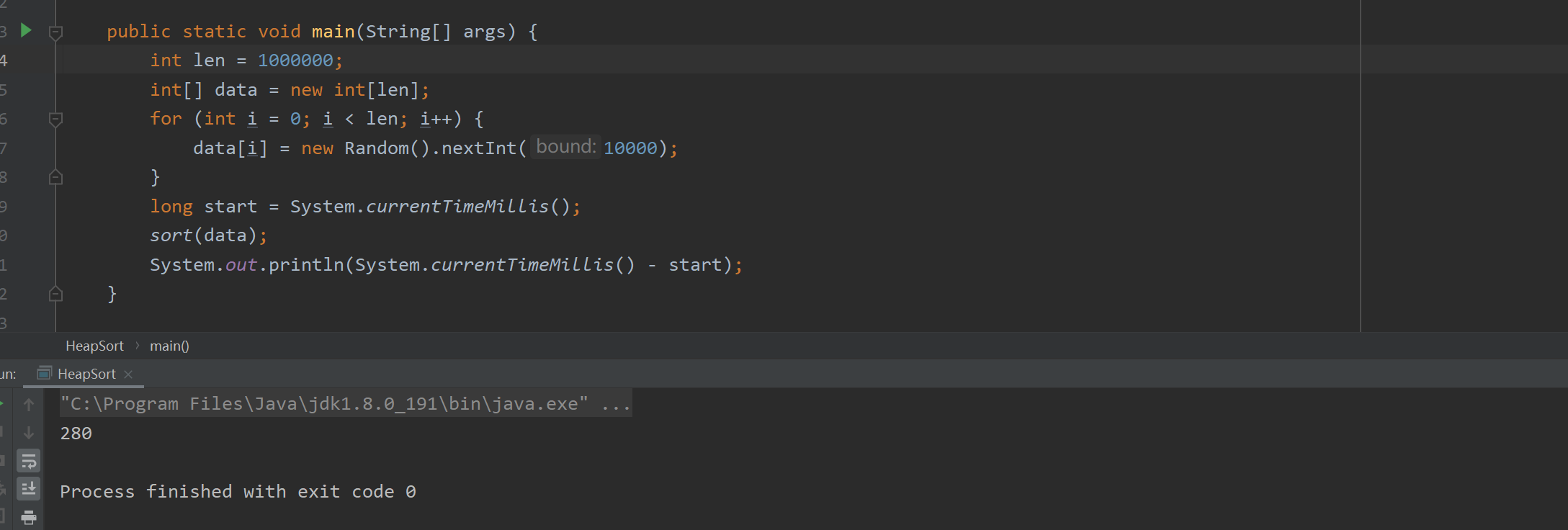
1000万随机数排序平均花费时间大概是3s多。
Java实现的二叉堆以及堆排序详解的更多相关文章
- python下实现二叉堆以及堆排序
python下实现二叉堆以及堆排序 堆是一种特殊的树形结构, 堆中的数据存储满足一定的堆序.堆排序是一种选择排序, 其算法复杂度, 时间复杂度相对于其他的排序算法都有很大的优势. 堆分为大头堆和小头堆 ...
- 二叉堆(三)之 Java的实现
概要 前面分别通过C和C++实现了二叉堆,本章给出二叉堆的Java版本.还是那句话,它们的原理一样,择其一了解即可. 目录1. 二叉堆的介绍2. 二叉堆的图文解析3. 二叉堆的Java实现(完整源码) ...
- 二叉堆(一)之 图文解析 和 C语言的实现
概要 本章介绍二叉堆,二叉堆就是通常我们所说的数据结构中"堆"中的一种.和以往一样,本文会先对二叉堆的理论知识进行简单介绍,然后给出C语言的实现.后续再分别给出C++和Java版本 ...
- 二叉堆(二)之 C++的实现
概要 上一章介绍了堆和二叉堆的基本概念,并通过C语言实现了二叉堆.本章是二叉堆的C++实现. 目录1. 二叉堆的介绍2. 二叉堆的图文解析3. 二叉堆的C++实现(完整源码)4. 二叉堆的C++测试程 ...
- 纯数据结构Java实现(6/11)(二叉堆&优先队列)
堆其实也是树结构(或者说基于树结构),一般可以用堆实现优先队列. 二叉堆 堆可以用于实现其他高层数据结构,比如优先队列 而要实现一个堆,可以借助二叉树,其实现称为: 二叉堆 (使用二叉树表示的堆). ...
- 打印二叉堆(Java实现)
打印二叉堆:利用层级关系 我这里是先将堆排序,然后在sort里执行了打印堆的方法printAsTree() public class MaxHeap<T extends Comparable&l ...
- 二叉堆的构建(Java)
package com.rao.linkList; /** * @author Srao * @className BinaryHeap * @date 2019/12/3 14:14 * @pack ...
- 【425】堆排序方法(二叉堆)优先队列(PQ)
参考:漫画:什么是二叉堆? 大根堆 小根堆 参考:漫画:什么是堆排序? 参考:漫画:什么是优先队列? 参考:[video]视频--第14周10--第8章排序10--8.4选择排序3--堆排序2--堆调 ...
- 二叉堆的介绍和Java实现
一.堆和二叉堆 堆,英文名称Heap,所谓二叉堆(也有直接称二叉堆为堆的),本质上是一个完全二叉树,前面也提到过,如果树接近于完全二叉树或者满二叉树,采用顺序存储代价会小一点,因此常见的二叉堆均是顺序 ...
随机推荐
- Docker管理工具之portainer
参考:https://www.cnblogs.com/frankdeng/p/9686735.html 1. 查询portainer镜像 命令:docker search portainer 实例: ...
- 什么是Cookie、Session、Token?
原文:https://mp.weixin.qq.com/s/pWXhI_ppKhtOP-Xf_SpuDA 来源:后厂村码农 在了解这三个概念之前我们先要了解 HTTP 是无状态的Web服务器,什么是无 ...
- python 把多个list合并为dataframe并输出到csv文件
import pandas as pd a = [1,2,3] b = ['a','b','c'] test = pd.DataFrame({'a_list':a,'b_list':b}) 将两个列表 ...
- python6.1创建类
class Dog(object): type1="宠物"#类变量 #初始化方法 def __init__(self,name,age,color): self.name=name ...
- 我还在生产玩 JDK7,JDK 15 却要来了!|新特性尝鲜
自从 JDK9 之后,每年 3 月与 9 月 JDK 都会发布一个新的版本,而2020 年 9 月即将引来 JDK15. 恰巧 IDEA 每四五个月会升级一个较大的版本,每次升级之后都会支持最新版本 ...
- python深挖65万人的明星贴吧,探究上万个帖子的秘密
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 最近一直在关注百度明星吧,发现很多有趣的帖子,于是我就想用python把这 ...
- 朴素贝叶斯分类器基本代码 && n折交叉优化
自己也是刚刚入门.. 没脸把自己的代码放上去,先用别人的. 加上自己的解析,挺全面的,希望有用. import re import pandas as pd import numpy as np fr ...
- 15、Facade 外观模式
什么是Facade模式 随着系统越来越复杂,我们需要把细节隐藏起来,给客户端提供一个统一的接口.在这种需求下facade模式诞生了.该模式比较简单,我们只需要在系统变得复杂把它运用上来,这样底层跟客户 ...
- day 10 面向对象(=)
1.魔法对象 __str _(self) 使用print(对象)输出的时候,自动调用该方法 return语句 返回一个值 class 类名: del _str ...
- 使用Axure设计基于中继器的左侧导航菜单
实现效果: 使用组件: 设计详解: 一.设计外层菜单 1.拖一个矩形,在属性栏中命名cd1,设置宽高为200*45,背景色#393D49,双击设置按钮名称为“默认展开”,字体大小16,字体颜色#C2C ...