MapReduce的工作流程
MapReduce的工作流程
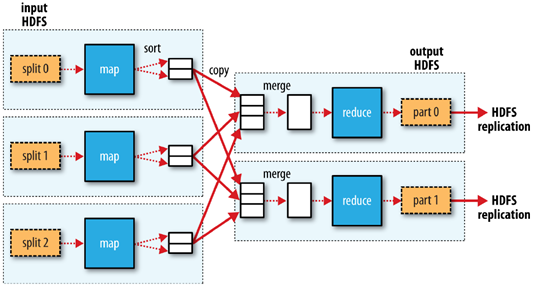
1.客户端将每个block块切片(逻辑切分),每个切片都对应一个map任务,默认一个block块对应一个切片和一个map任务,split包含的信息:分片的元数据信息,包含起始位置,长度,和所在节点列表等
2.map按行读取切片数据,组成键值对,key为当前行在源文件中的字节偏移量,value为读到的字符串
3.map函数对键值对进行计算,输出<key,value,partition(分区号)>格式数据,partition指定该键值对由哪个reducer进行处理。通过分区器,key的hashcode对reducer个数取模。
4.map将kvp写入环形缓冲区内,环形缓冲区默认为100MB,阈值为80%,当环形缓冲区达到80%时,就向磁盘溢写小文件,该小文件先按照分区号排序,区号相同的再按照key进行排序,归并排序。溢写的小文件如果达到三个,则进行归并,归并为大文件,大文件也按照分区和key进行排序,目的是降低中间结果数据量(网络传输),提升运行效率
5.如果map任务处理完毕,则reducer发送http get请求到map主机上下载数据,该过程被称为洗牌shuffle
6.可以设置combinclass(需要算法满足结合律),先在map端对数据进行一个压缩,再进行传输,map任务结束,reduce任务开始
7.reduce会对洗牌获取的数据进行归并,如果有时间,会将归并好的数据落入磁盘(其他数据还在洗牌状态)
8.每个分区对应一个reduce,每个reduce按照key进行分组,每个分组调用一次reduce方法,该方法迭代计算,将结果写到hdfs输出
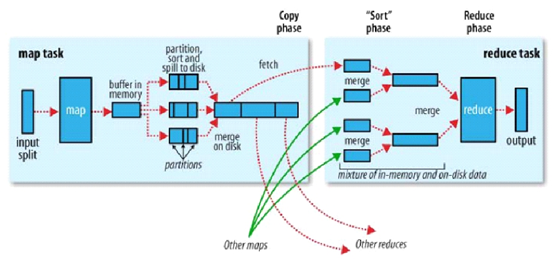
洗牌阶段
1.copy:一个reduce任务需要多个map任务的输出,每个map任务完成时间很可能不同,当只要有一个map任务完成,reduce任务立即开始复制,复制线程数配置mapred-site.xml参数“mapreduce.reduce.shuffle.parallelcopies",默认为5.
2.copy缓冲区:如果map输出相当小,则数据先被复制到reduce所在节点的内存缓冲区大小配置mapred-site.xml参数“mapreduce.reduce.shuffle.input.buffer.percent”,默认0.70),当内存缓冲区大小达到阀值(mapred-site.xml参数“mapreduce.reduce.shuffle.merge.percent”,默认0.66)或内存缓冲区文件数达到阀值(mapred-site.xml参数“mapreduce.reduce.merge.inmem.threshold”,默认1000)时,则合并后溢写磁盘。
3.sort:复制完成所有map输出后,合并map输出文件并归并排序
4.sort的合并:将map输出文件合并,直至≤合并因子(mapred-site.xml参数“mapreduce.task.io.sort.factor”,默认10)。例如,有50个map输出文件,进行5次合并,每次将10各文件合并成一个文件,最后5个文件。
K,V使用自定义数据类型
框架会对键,值序列化,因此键类型和值类型需要实现writable接口
框架会对键进行排序,因此必须实现writableComparable接口
MapReduce的工作流程的更多相关文章
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- MapReduce与Yarn 的详细工作流程分析
MapReduce详细工作流程之Map阶段 如上图所示 首先有一个200M的待处理文件 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片 提交:提交可以提交到本地工作环 ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- Hadoop随笔(一):工作流程的源码
一.几个可能会用到的属性值 1.mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution 这两个 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- yarn工作流程
YARN 是 Hadoop 2.0 中的资源管理系统, 它的基本设计思想是将 MRv1 中的 JobTracker拆分成了两个独立的服务 : 一个全局的资源管理器 ResourceManager 和每 ...
- MapReduce的工作原理
MapReduce简介 MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理.实现下面目标 ★ 易于编程 ★ 良好的扩展性 ★ 高容错性 MapReduce ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(二)
本文继<Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)>,接着讲述MapReduce作业在MRAppMaster上处理总流程,继上篇讲到作业初始化之后的作 ...
随机推荐
- C#数据结构-队列
队列作为线性表的另一个数据结构,只允许在表的前端进行删除操作,而在表的后端进行插入操作,和栈一样,队列是一种操作受限制的线性表. 先来看下用法: Queue queue = new Queue(); ...
- influxdb集群部署
环境准备 influxdb enterprise运行条件最低需要三个meta nodes节点以及两个data nodes Meta nodes之间使用TCP和Raft一致性协议通信,默认端口为8089 ...
- Jmeter入门(3)- Jmeter录制脚本
一. 录制web端 1. Badboy的介绍和安装 1.1 使用第三方工具Badboy来录制. 免费的web自动化测试工具 一个浏览器模拟工具 主要进行脚本的录制和回访,和对录制脚本进行调试,可以将脚 ...
- 去重想到set,排序想到Arrays.sort
package test; import java.util.Arrays; import java.util.Scanner; import java.util.Set; import java.u ...
- ubuntu18.04下的off-by-null:hitcon_2018_children_tcache
又没做出来,先说说自己的思路 因为是off-by-null,所以准备构造重叠的chunk,但是发现程序里有memset,给构造prev size造成重大问题 所以来详细记录一下做题过程 先逆向,IDA ...
- Nexus3常用功能备忘
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- javascript常见面试题之一:数组的冒泡排序;
var arr=[32,2,7,78,90,10]; //外层循环控制轮数: for (var i = 0; i < arr.length; i++) { //内层循环控制次数: for (va ...
- SpringBoot原理发现(一)
说明: 本系列基于SpringBoot 2.2.9.RELEASE 版本,对SpringBoot的原理进行分析,一共分为四节: SpringBoot原理发现(一):创建Hello World,对pom ...
- spark求相同key的最大值
需求: 求相同key的最大值 [("a", 3), ("a", 2), ("a", 5), ("b", 5), ...
- Java基础系列-单例的7种写法
原创文章,转载请标注出处:https://www.cnblogs.com/V1haoge/p/10755322.html 一.概述 Java中单例有7种写法,这个是在面试中经常被问到的内容,而且有时候 ...