MapReduce的工作原理
MapReduce简介
MapReduce有哪些角色?各自的作用是什么?
MapReduce程序执行流程
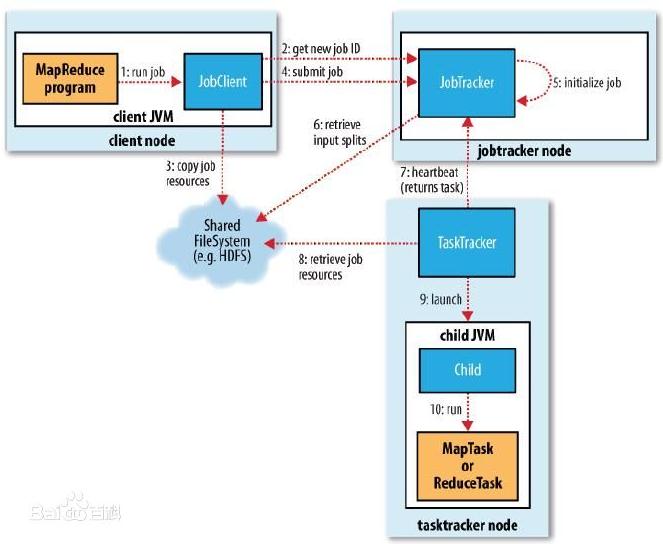
MapReduce工作原理
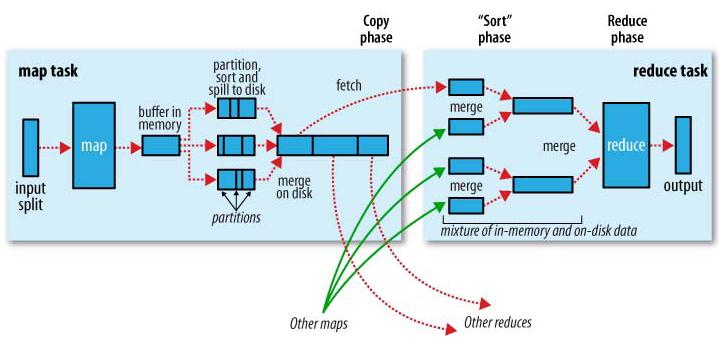
reduce task
MapReduce中Shuffle过程


MapReduce编程主要组件
针对MapReduce的缺点,YARN解决了什么?
MapReduce的工作原理的更多相关文章
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- 【hadoop】细读MapReduce的工作原理
前言:中秋节有事外加休息了一天,今天晚上重新拾起Hadoop,但感觉自己有点烦躁,不知后续怎么选择学习Hadoop的方法. 干脆打开电脑,决定: 1.先将Hadoop的MapReduce和Yarn基本 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
随机推荐
- docker中的镜像中运行Django项目
首先要在镜像中 安装python3 以及 django2.0.4 目前我用的是这两个版本. 进入镜像 创建项目 进入项目中修改setting文件 将引号和星号添加进括号中 ALLOWED_HOSTS ...
- Harbor修改/data目录位置
由于harbor默认数据存储位置在/data目录,且修改配置文件操作较为复杂,故这里使用软连接的方式将/data目录文件夹内容映射到/app目录下. ln -s /app/harbor/data/ d ...
- Mac 装Sequel pro 连接 Mysql 8.0 失败、登录不了、loading问题
最近都没更新博客,零零散散的笔记也都没整理,so 觉得还是不放上来了. 高兴的是入手了期待好久的水果机,开始了各种捣鼓,好想大撸一下代码啊.... 回到正轨,刚装了mysql8.0, 想装下mysql ...
- 学习 razor pages 指南
这是一个系列,我打算把此人的系列翻译一下,学习技术的同时,顺便提高一下英文水平. 原文地址:https://www.learnrazorpages.com/ 前言 欢迎来学习 razor pages ...
- 对于JavaBean+Servlet+SqlServer的代码总结和打包调用
日期:2019.3.24 博客期:049 星期日 说起来我已经说过很多次前台的应用技术了呢!这一次我是要将这一部分打包,做成配套的制作工具: 当前我已经打包成功,想要下载的同学可以进入我的GitHub ...
- appium 与 selenium python解决python 'WebElement' object does not support indexing 报错问题问题
再用selenium编写测试脚本时,发现出现python 'WebElement' object does not support indexing 报错问题问题,再找一些解决方法时,发现Appium ...
- python-数据类型之题型
1.让用户输入任意字符串,获取字符串之后并计算其中有多少个数字. total = 0 text = input("请输入内容") a = 0 while a <len(tex ...
- leetcode python最长回文子串
回文的意思是正着念和倒着念一样,如:上海自来水来自海上,雾锁山头山锁雾,天连水尾水连天 给定一个字符串 s,找到 s 中最长的回文子串.你可以假设 s 的最大长度为 1000. 示例 1: 输入: & ...
- android---EditText的多行输入框
<EditText android:id="@+id/edt_order_note_text" android:layout_width="match_parent ...
- [3]第二章 C++编程简介
(本资料均从 internet 上进行收录整理,若要转载,请与原作者联系) 2.1 机器语言.汇编语言和高级语言 程序员用各种编程语言编写指令,有些是计算机直接理解的,有些则需要中间翻译(tranl ...