MapReduce的工作流程
MapReduce的工作流程
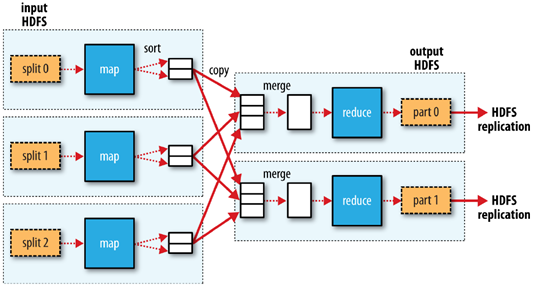
1.客户端将每个block块切片(逻辑切分),每个切片都对应一个map任务,默认一个block块对应一个切片和一个map任务,split包含的信息:分片的元数据信息,包含起始位置,长度,和所在节点列表等
2.map按行读取切片数据,组成键值对,key为当前行在源文件中的字节偏移量,value为读到的字符串
3.map函数对键值对进行计算,输出<key,value,partition(分区号)>格式数据,partition指定该键值对由哪个reducer进行处理。通过分区器,key的hashcode对reducer个数取模。
4.map将kvp写入环形缓冲区内,环形缓冲区默认为100MB,阈值为80%,当环形缓冲区达到80%时,就向磁盘溢写小文件,该小文件先按照分区号排序,区号相同的再按照key进行排序,归并排序。溢写的小文件如果达到三个,则进行归并,归并为大文件,大文件也按照分区和key进行排序,目的是降低中间结果数据量(网络传输),提升运行效率
5.如果map任务处理完毕,则reducer发送http get请求到map主机上下载数据,该过程被称为洗牌shuffle
6.可以设置combinclass(需要算法满足结合律),先在map端对数据进行一个压缩,再进行传输,map任务结束,reduce任务开始
7.reduce会对洗牌获取的数据进行归并,如果有时间,会将归并好的数据落入磁盘(其他数据还在洗牌状态)
8.每个分区对应一个reduce,每个reduce按照key进行分组,每个分组调用一次reduce方法,该方法迭代计算,将结果写到hdfs输出
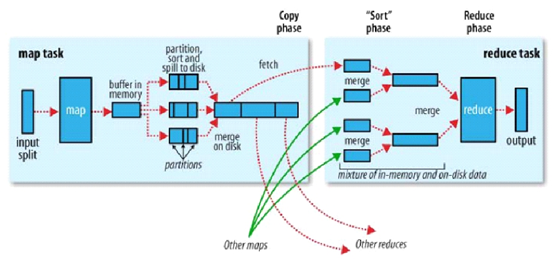
洗牌阶段
1.copy:一个reduce任务需要多个map任务的输出,每个map任务完成时间很可能不同,当只要有一个map任务完成,reduce任务立即开始复制,复制线程数配置mapred-site.xml参数“mapreduce.reduce.shuffle.parallelcopies",默认为5.
2.copy缓冲区:如果map输出相当小,则数据先被复制到reduce所在节点的内存缓冲区大小配置mapred-site.xml参数“mapreduce.reduce.shuffle.input.buffer.percent”,默认0.70),当内存缓冲区大小达到阀值(mapred-site.xml参数“mapreduce.reduce.shuffle.merge.percent”,默认0.66)或内存缓冲区文件数达到阀值(mapred-site.xml参数“mapreduce.reduce.merge.inmem.threshold”,默认1000)时,则合并后溢写磁盘。
3.sort:复制完成所有map输出后,合并map输出文件并归并排序
4.sort的合并:将map输出文件合并,直至≤合并因子(mapred-site.xml参数“mapreduce.task.io.sort.factor”,默认10)。例如,有50个map输出文件,进行5次合并,每次将10各文件合并成一个文件,最后5个文件。
K,V使用自定义数据类型
框架会对键,值序列化,因此键类型和值类型需要实现writable接口
框架会对键进行排序,因此必须实现writableComparable接口
MapReduce的工作流程的更多相关文章
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- MapReduce与Yarn 的详细工作流程分析
MapReduce详细工作流程之Map阶段 如上图所示 首先有一个200M的待处理文件 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片 提交:提交可以提交到本地工作环 ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- Hadoop随笔(一):工作流程的源码
一.几个可能会用到的属性值 1.mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution 这两个 ...
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- yarn工作流程
YARN 是 Hadoop 2.0 中的资源管理系统, 它的基本设计思想是将 MRv1 中的 JobTracker拆分成了两个独立的服务 : 一个全局的资源管理器 ResourceManager 和每 ...
- MapReduce的工作原理
MapReduce简介 MapReduce是一种并行可扩展计算模型,并且有较好的容错性,主要解决海量离线数据的批处理.实现下面目标 ★ 易于编程 ★ 良好的扩展性 ★ 高容错性 MapReduce ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
- Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(二)
本文继<Yarn源码分析之MRAppMaster上MapReduce作业处理总流程(一)>,接着讲述MapReduce作业在MRAppMaster上处理总流程,继上篇讲到作业初始化之后的作 ...
随机推荐
- Activiti的流程实例【ProcessInstance】与执行实例【Execution】
最近,我在做流程引擎Activiti相关的东西,刚开始时的一个知识点困扰了我许久,那就是Activiti的ProcessInstance与Execution的区别,这是一个Activiti的难点,能够 ...
- Python之format字符串格式化
1.字符串连接 >>> a = 'My name is ' + 'Suen' >>> a 'My name is Suen' >>> a = 'M ...
- python 实现多层列表拆分成单层列表
有个多层列表:[1, 2, 3, 4, [5, 6, [7, 8]], ['a', 'b', [2, 4]]],拆分成单层列表 使用内置方法 结果和原列表顺序不同 def split(li): pop ...
- 【线上排查实战】AOP切面执行顺序你真的了解吗
前言 忙,是我这个月的主旋律,也是我频繁鸽文章的接口----蛮三刀把刀 公司这两个月启动了全新的项目,项目排期满满当当,不过该学习还是要学习.这不,给公司搭项目的时候,踩到了一个Spring AOP的 ...
- 如何玩转Python? 一文总结30种Python的窍门和技巧
Python作为2019年必备语言之一,展现了不可替代作用.对于所有的数据科学工作者,如何提高使用Python的效率,这里,总结了30种Python的最佳实践.技巧和窍门.希望这些可以帮助大家在202 ...
- jq animate 的第二写法
俩个参数的写法 例子: $('#div1').animate({num:'auto'},{ duration : 1000, //运动时间 easing : 'linear', //运动形式 ...
- STM32入门系列-STM32时钟系统,自定义系统时钟
在时钟树的讲解中我们知道,通过修改PLLMUL中的倍系数值(2-16)可以改变系统的时钟频率.在库函数中也有对时钟倍频因子配置的函数,如下: void RCC_PLLConfig(uint32_t R ...
- 基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪
原文链接:基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪 一.日志系统 1.日志框架 在每个系统应用中,我们都会使用日志系统,主要是为了记录必要的信息和方便排 ...
- C++ storage allocation + Dynamic memory allocation + setting limits + initializer list (1)
1. 对象的空间在括号开始就已经分配,但是构造在定义对象的时候才会实现,若跳过(譬如goto),到括号结束析构会发生错误,编译会通不过. 2.初始化 1 struct X { int i ; floa ...
- Serilog 源码解析——Sink 的实现
在上一篇中,我们简单地查看了 Serilog 的整体需求和大体结构.从这一篇开始,本文开始涉及 Serilog 内的相关实现,着重解决第一个问题,即 Serilog 向哪里写入日志数据的.(系列目录) ...