DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks
1、Introduction
DL解决VO问题:End-to-End VO with RCNN

2、Network structure
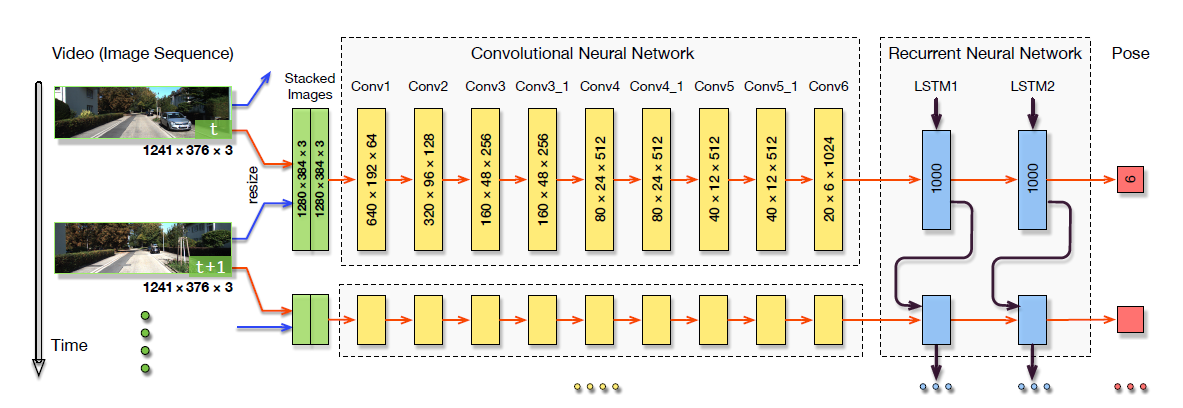
a.CNN based Feature Extraction
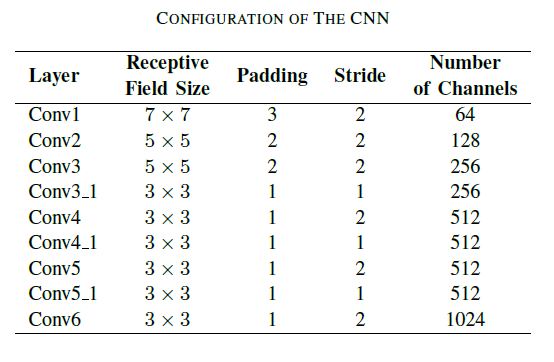
论文使用KITTI数据集。
CNN部分有9个卷积层,除了Conv6,其他的卷积层后都连接1层ReLU,则共有17层。
b、RNN based Sequential Modelling
RNN is different from CNN in that it maintains memory of its hidden states over time and has feedback loops among them, which enables its current hidden state to be a function of the previous ones.
Given a convolutional feature xk at time k, a RNN updates at time step k by
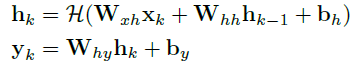
hk and yk are the hidden state and output at time k respectively.
W terms denote corresponding weight matrices.
b terms denote bias vectors.
H is an element-wise nonlinear activation function.
LSTM
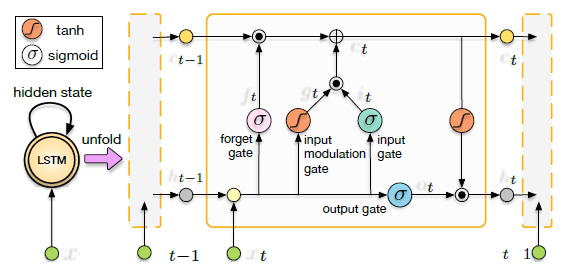
Folded and unfolded LSTMs and internal structure of its unit.

 is element-wise product of two vectors.
is element-wise product of two vectors.
σ is sigmoid non-linearity.
tanh is hyperbolic tangent non-linearity.
W terms denote corresponding weight matrices.
b terms denote bias vectors.
ik, f k, gk, ck and ok are input gate, forget gate, input modulation gate, memory cell and output gate.
Each of the LSTM layers has 1000 hidden states.
3、损失函数及优化
The conditional probability of the poses Yt = (y1, . . . , yt) given a sequence of monocular RGB images Xt = (x1, . . . , xt) up to time t.
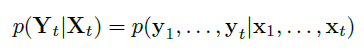
Optimal parameters :
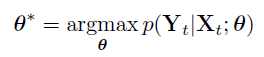
The hyperparameters of the DNNs:

(pk, φk) is the ground truth pose.
(pˆk, φˆk) is the estimated ground truth pose.
κ (100 in the experiments) is a scale factor to balance the weights of positions and orientations.
N is the number of samples.
The orientation φ is represented by Euler angles rather than quaternion since quaternion is subject to an extra unit constraint which hinders the optimisation problem of DL.
DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks的更多相关文章
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- 论文笔记之:Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking CVPR 2016 本文提出了一种新的CNN 框架来处理 ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
- Convolutional Neural Networks for Visual Recognition 1
Introduction 这是斯坦福计算机视觉大牛李菲菲最新开设的一门关于deep learning在计算机视觉领域的相关应用的课程.这个课程重点介绍了deep learning里的一种比较流行的模型 ...
- cs231n spring 2017 lecture1 Introduction to Convolutional Neural Networks for Visual Recognition 听课笔记
1. 生物学家做实验发现脑皮层对简单的结构比如角.边有反应,而通过复杂的神经元传递,这些简单的结构最终帮助生物体有了更复杂的视觉系统.1970年David Marr提出的视觉处理流程遵循这样的原则,拿 ...
- Stanford CS231n - Convolutional Neural Networks for Visual Recognition
网易云课堂上有汉化的视频:http://study.163.com/course/courseLearn.htm?courseId=1003223001#/learn/video?lessonId=1 ...
- CS231n: Convolutional Neural Networks for Visual Recognition
https://zhuanlan.zhihu.com/p/28522637 https://zhuanlan.zhihu.com/p/21930884 mark
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Robust Online Visual Tracking with a Single Convolutional Neural Network
Abstract:这篇论文有三个贡献,第一提出了新颖的简化的结构损失函数,能保持尽量多的训练样本,通过适应模型输出的不确定性来减少跟踪误差累积风险. 第二是增强了普通的SGD,采用了暂时的选择策略来进 ...
随机推荐
- HashMap等集合初始化时应制定初始化大小
阿里巴巴开发规范中,推荐用户在初始化HashMap时,应指定集合初始值大小. 一.原因 这个不用多想,肯定是效率问题,那为什么会造成效率问题呢? 当我们new一个HashMap没有对其容量进行初始化的 ...
- C# DataTable与Excel读取与导出
/// <summary> /// Excel->DataTable /// </summary> /// <param name="filePath&q ...
- Vue中token的实现
在学习vue的过程中,正好项目中做的web系统对安全性有要求 转载自https://www.jianshu.com/p/d1a3fb71eb99 总:通过axios,vuex,及自定义的方法实现.以下 ...
- 什么?你正在学web自动化测试?那这些Selenium的基本操作你了解过吗?
在自动化测试中,我们都知道是通过定位元素来实现的,那么有时候我们定位元素定位不到是为什么呢? 1.页面出现了iframe 2.出现了新的窗口,没有实现句柄的切换 3.三种等待方式,没有选择其中之一来使 ...
- 技术小菜比入坑 LinkedList,i 了 i 了
先看再点赞,给自己一点思考的时间,思考过后请毫不犹豫微信搜索[沉默王二],关注这个长发飘飘却靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有技术大佬整理 ...
- react实战 : react 与 canvas
有一个需求是这样的. 一个组件里若干个区块.区块数量不定. 区块里面是一个正六边形组件,而这个用 SVG 和 canvas 都可以.我选择 canvas. 所以就变成了在 react 中使用 canv ...
- LESS实战::not与:hover混合使用
举个例子,有个HTML是这样的. <div class="item light">A</div> <div class="item" ...
- vue : 在vuex里写一个数组首尾元素互换的方法
不着急上代码,先想几个问题. vuex里怎么写方法? mutation里写vuex方法,组件中用commit调用. 数组首尾元素怎么互换? arr.splice(0, 0, arr[arr.lengt ...
- JavaScript数组在指定某个元素前或后添加元素
//原数组 var s = [['g','g'],['h','h'],['i','i']]; //要添加的元素 var s1 = ['a','b','c']; //要添加的元素 var s2 = [' ...
- CCNA - Part10 数据包的通信过程
这篇文章主要是对数据包在同网段和不同网段的转发流程梳理,使用 ping 命令进行实际抓包测试. 网关的概念: 对于像 PC 等终端设备来说,通过交换机可以实现同网段的通信.但如果想要给其他网段发生数据 ...