elastic-job分布式调度与zookeeper的简单应用
一、对分布式调度的理解
调度—>定时任务,分布式调度—>在分布式集群环境下定时任务这件事
Elastic-job(当当⽹开源的分布式调度框架)
1 定时任务的场景
定时任务形式:每隔⼀定时间/特定某⼀时刻执⾏ 例如:
订单审核、出库 订单超时⾃动取消、⽀付退款 礼券同步、⽣成、发放作业 物流信息推送、抓取作业、退换货处理作业
数据积压监控、⽇志监控、服务可⽤性探测作业 定时备份数据
⾦融系统每天的定时结算 数据归档、清理作业 报表、离线数据分析作业
2 什么是分布式调度
什么是分布式任务调度?有两层含义
1)运⾏在分布式集群环境下的调度任务(同⼀个定时任务程序部署多份,只应该有⼀个定时任务在执
⾏)
2)分布式调度—>定时任务的分布式—>定时任务的拆分(即为把⼀个⼤的作业任务拆分为多个⼩的作 业任务,同时执⾏)
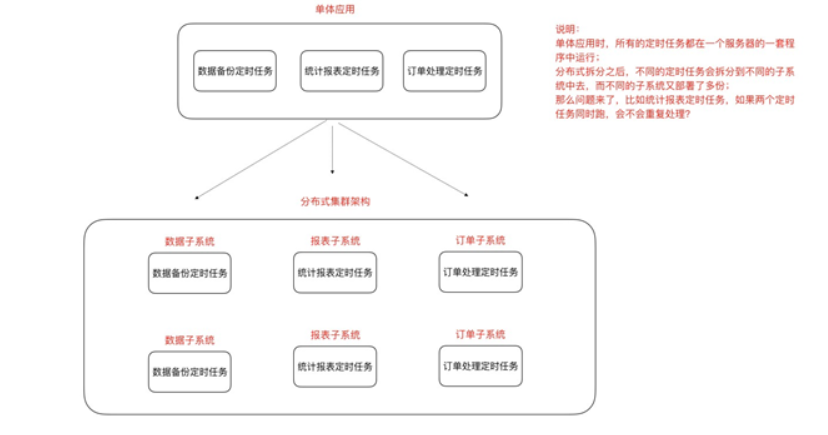
3、分布式调度Elastic-Job与zookeeperk
特点优点
轻量级去中⼼化
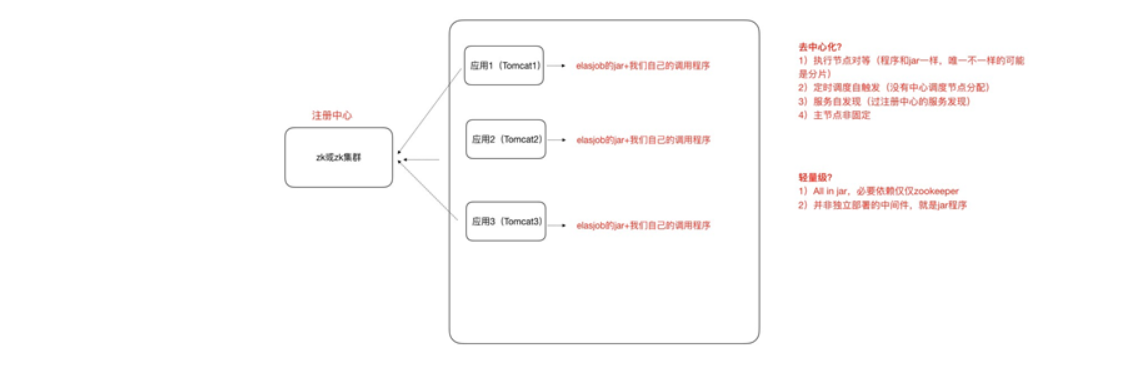
2、任务分⽚
1、ElasticJob可以把作业分为多个的task(每⼀个task就是⼀个任务分⽚),每⼀个task交给具体的⼀个机器2、实例去处理(⼀个机器实例是可以处理多个task的),但是具体每个task 执⾏什么逻辑由我们⾃⼰来指定。
3、默认是平均去分,可以定制。分⽚项也是⼀个JOB配置,修改配置,重新分⽚,在下⼀次定时运⾏之前会重新调⽤分⽚算法
结果就是:哪台机器运⾏哪⼀个⼀⽚,这个结果存储到zookeeperk中的,主节点会把分⽚给分好 放到注册中⼼去,然后执⾏节点从注册中⼼获取信息(执⾏节点在定时任务开启的时候获取相应的分⽚
2)如果所有的节点挂掉值剩下⼀个节点,所有分⽚都会指向剩下的⼀个节点,这也是ElasticJob的⾼可
⽤。
3、 弹性扩容

总结:
分布式调度ElasticJob目的是解决某一个job节点的服务器压力(一个人做,和一堆人分工去做的)利用zookeeperk 轻量级去中⼼、任务分⽚、弹性扩容 三大特点,实现分片分工。快速有效、协调完成工作。不会出现分片重复工作的情况。
二、准备验证环境
1、安装zookeeper
https://www.cnblogs.com/aGboke/p/12904932.html
zooInspector的使用: https://www.cnblogs.com/lwcode6/p/11586537.html
elastic-job:https://github.com/elasticjob
2、搭建maven项目、引入
<!--数据库驱动jar-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<!--任务调度框架quartz-->
<!--org.quartz-scheduler/quartz -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency> <!--elastic-job-lite-core-->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>elastic-job-lite-core</artifactId>
<version>2.1.5</version>
</dependency>
3、测试代码
package com.lagou.job; import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.dangdang.ddframe.job.config.JobCoreConfiguration;
import com.dangdang.ddframe.job.config.simple.SimpleJobConfiguration;
import com.dangdang.ddframe.job.lite.api.JobScheduler;
import com.dangdang.ddframe.job.lite.config.LiteJobConfiguration;
import com.dangdang.ddframe.job.reg.base.CoordinatorRegistryCenter;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperConfiguration;
import com.dangdang.ddframe.job.reg.zookeeper.ZookeeperRegistryCenter; import java.util.List;
import java.util.Map; /**
* @author Mrwg
* @date 2020/5/15
* @description
*/
public class BackupJob implements SimpleJob { @Override
public void execute(ShardingContext shardingContext){
/*
从resume数据表查找1条未归档的数据,将其归档到resume_bak
表,并更新状态为已归档(不删除原数据)
*/
// 查询出⼀条数据
String selectSql = "select * from resume where state='未归档' limit 1";
List<Map<String, Object>> list = JdbcUtil.executeQuery(selectSql);
if (list == null || list.size() == 0) {
return;
}
Map<String, Object> stringObjectMap = list.get(0);
long id = (long) stringObjectMap.get("id");
String name = (String) stringObjectMap.get("name");
String education = (String) stringObjectMap.get("education");
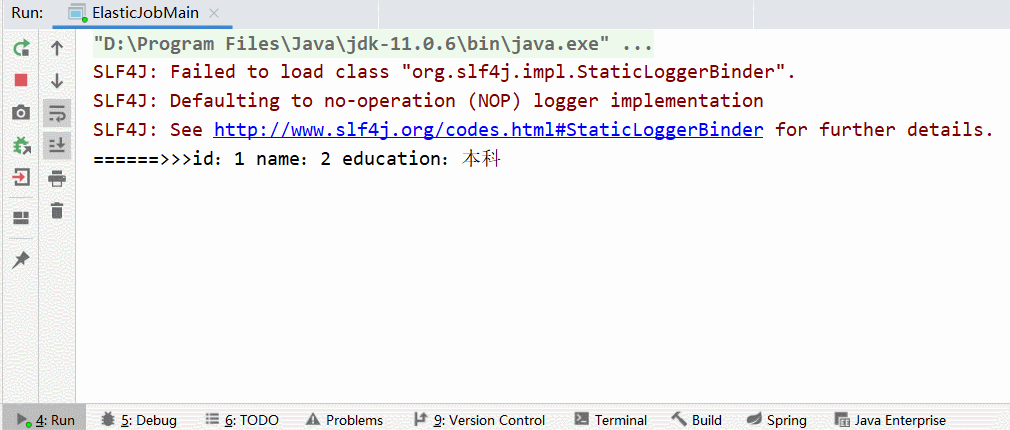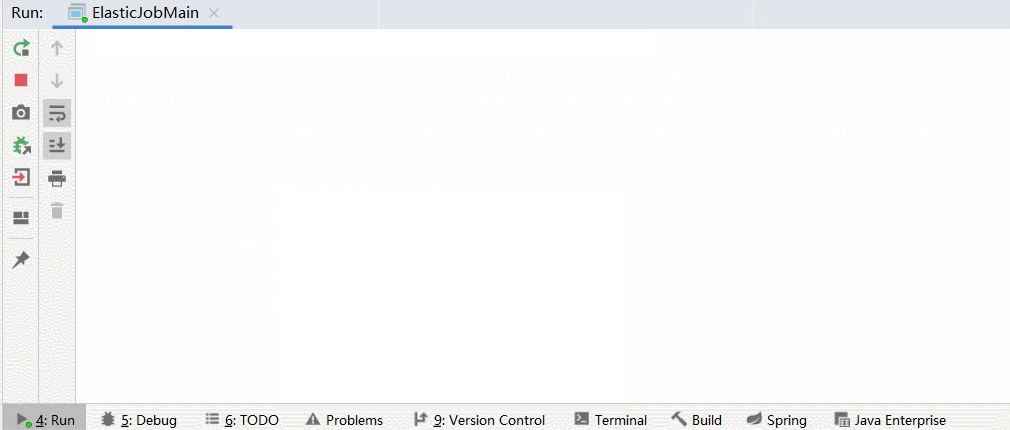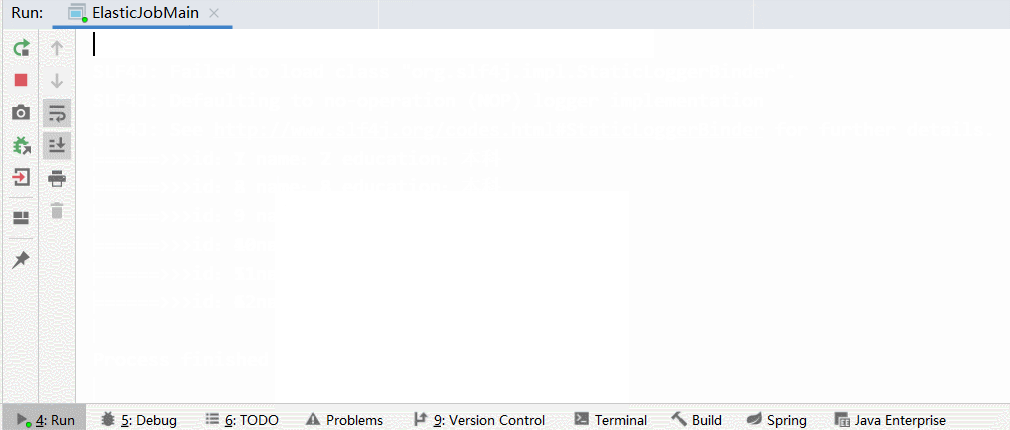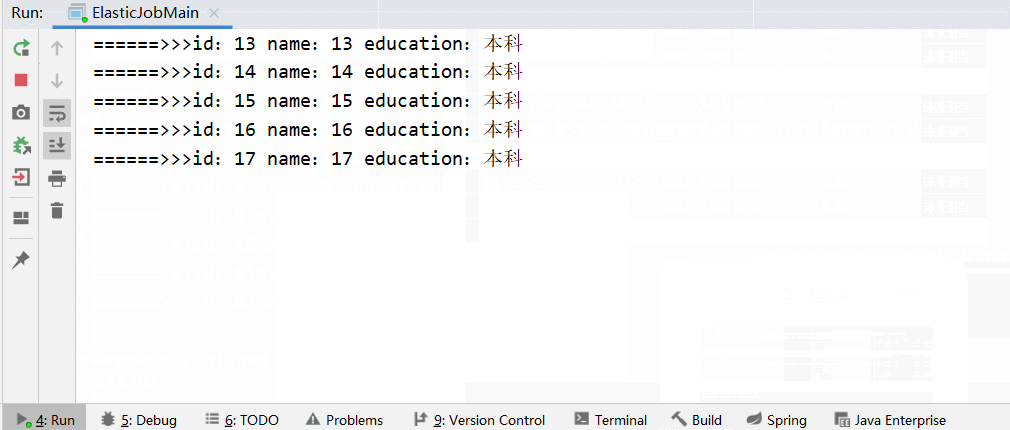
// 打印出这条记录
System.out.println("======>>>id:" + id + " name:" + name + " education:" + education);
// 更改状态
String updateSql = "update resume set state='已归档' where id=?";
JdbcUtil.executeUpdate(updateSql, id);
// 归档这条记录
String insertSql = "insert into resume_bak select * from resume where id=?";
JdbcUtil.executeUpdate(insertSql, id);
} public static void main(String[] args) { //配置分布式Zookeeper分布式协调中心
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration("ip:2181", "elastic-job");
CoordinatorRegistryCenter coordinatorRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
coordinatorRegistryCenter.init(); //配置任务 每秒运行一次
JobCoreConfiguration jobCoreConfiguration =
JobCoreConfiguration.newBuilder("archive-job", "1 * * * * ?", 1).build();
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, BackupJob.class.getName());
//启动任务
new JobScheduler(coordinatorRegistryCenter, LiteJobConfiguration.newBuilder(simpleJobConfiguration).build()).init(); }
}
package com.lagou.job; import java.sql.*;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; /**
* @author Mrwg
* @date 2020/5/15
* @description
*/
public class JdbcUtil {
//url
private static String url = "jdbc:mysql://localhost:3306/test?characterEncoding=utf8&useSSL=false";
//user
private static String user = "";
//password
private static String password = "";
//驱动程序类
private static String driver = "com.mysql.jdbc.Driver"; static {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} public static Connection getConnection() {
try {
return DriverManager.getConnection(url, user, password);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
} public static void close(ResultSet rs, PreparedStatement ps,
Connection con) {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (con != null) {
try {
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
}
} public static void executeUpdate(String sql, Object... obj) {
Connection con = getConnection();
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);
for (int i = 0; i < obj.length; i++) {
ps.setObject(i + 1, obj[i]);
}
ps.executeUpdate();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(null, ps, con);
}
} public static List<Map<String, Object>> executeQuery(String
sql, Object... obj) {
Connection con = getConnection();
ResultSet rs = null;
PreparedStatement ps = null;
try {
ps = con.prepareStatement(sql);
for (int i = 0; i < obj.length; i++) {
ps.setObject(i + 1, obj[i]);
}
rs = ps.executeQuery();
List<Map<String, Object>> list = new ArrayList<>();
int count = rs.getMetaData().getColumnCount();
while (rs.next()) {
Map<String, Object> map = new HashMap<String,
Object>();
for (int i = 0; i < count; i++) {
Object ob = rs.getObject(i + 1);
String key = rs.getMetaData().getColumnName(i
+ 1);
map.put(key, ob);
}
list.add(map);
}
return list;
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(rs, ps, con);
}
return null; }
}
JdbcUtil
CREATE TABLE `resume` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`sex` varchar(255) DEFAULT NULL,
`phone` varchar(255) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
`education` varchar(255) DEFAULT NULL,
`state` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
create table resume_bak like resume;
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (1, '2', 'girl', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (2, '2', 'girl2', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (3, '3', 'girl3', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (4, '4', 'girl4', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (5, '5', 'girl5', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (6, '6', 'girl6', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (7, '7', 'girl7', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (8, '8', 'girl8', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (9, '9', 'girl9', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (10, '10', 'girl10', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (11, '11', 'girl11', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (12, '12', 'girl12', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (13, '13', 'girl13', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (14, '14', 'girl14', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (15, '15', 'girl15', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (16, '16', 'girl16', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (17, '17', 'girl17', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (18, '18', 'girl18', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (19, '19', 'girl19', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (20, '20', 'girl20', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (21, '21', 'girl21', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (22, '22', 'girl22', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (23, '23', 'girl23', '18801240649', '北京', '本科', '已归档');
INSERT INTO `test`.`resume`(`id`, `name`, `sex`, `phone`, `address`, `education`, `state`) VALUES (24, '24', 'girl24', '18801240649', '北京', '本科', '已归档');
sql脚本
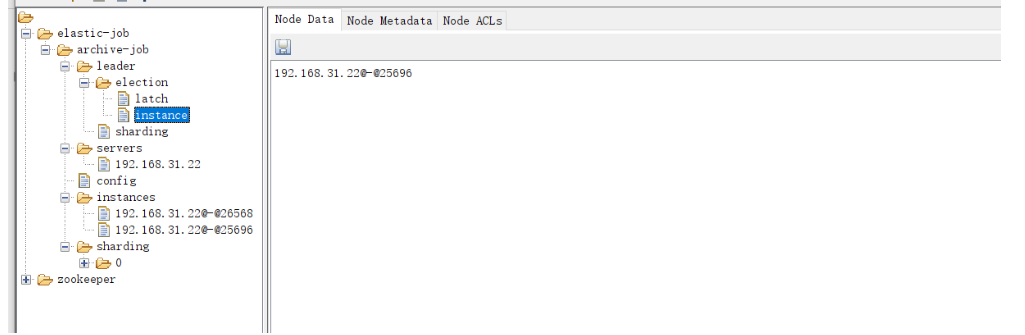
4、启动main()方法 ,zooInspector 链接 zookeeper
1、启动一个实列
当前定时任务,全部在当前实列下执行,启动俩个实列,zk会重新计算分片和竞争机制,来确定那台机器运行当前任务。(一般情况下第二个实列会拿到领导权),当我们把俩个实列,
其中一个停掉,第一个实列会继续接着运行未完成的任务。 如下下边gif所示。运行速度受当前网络、机器硬件影响。

2、启动俩个实列
3、调整分片数量
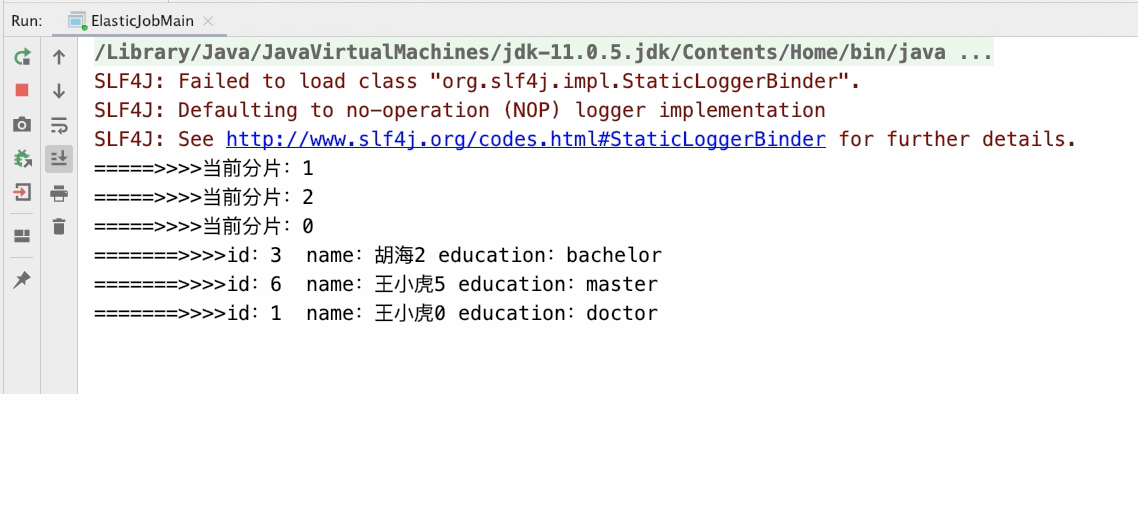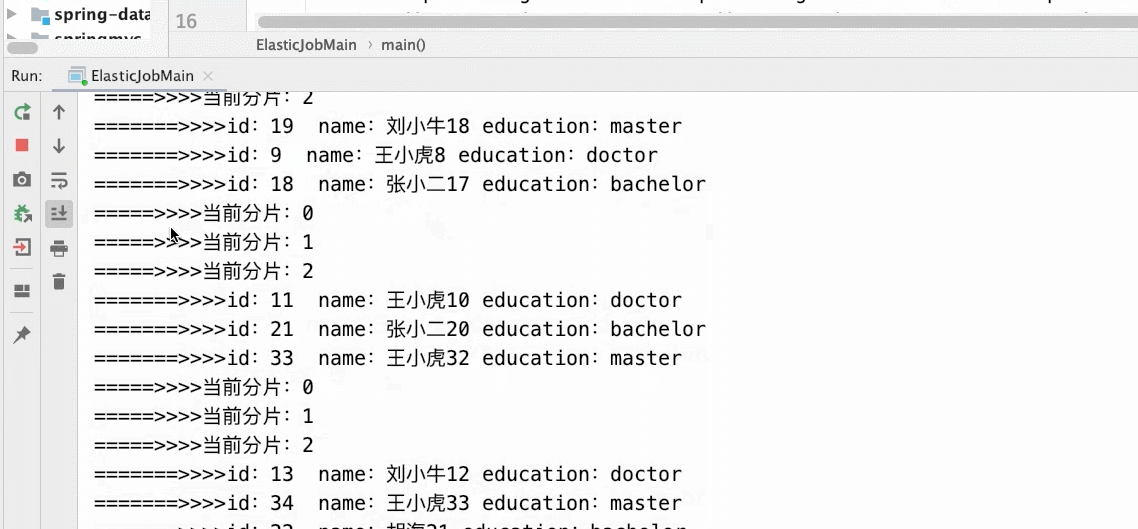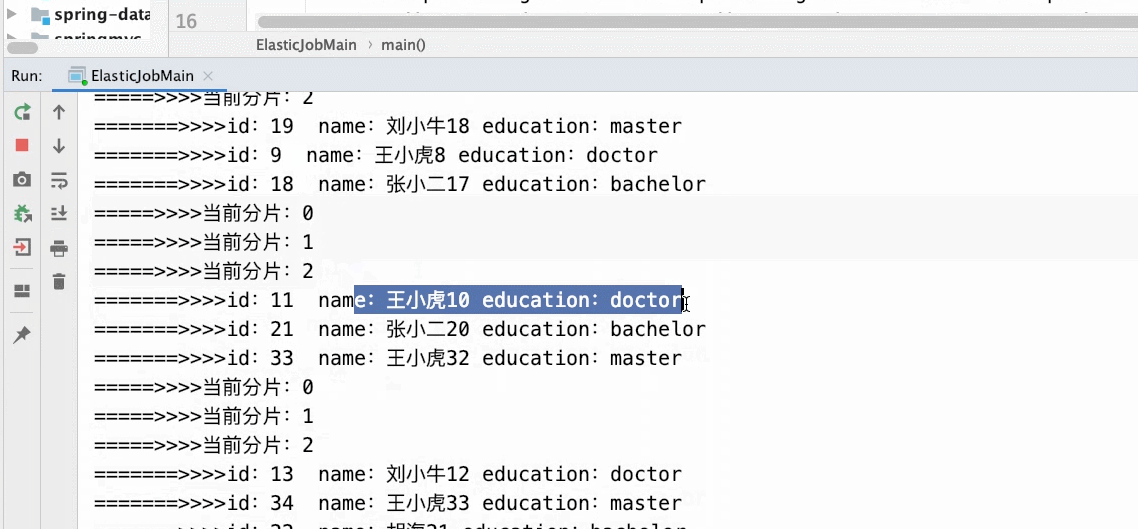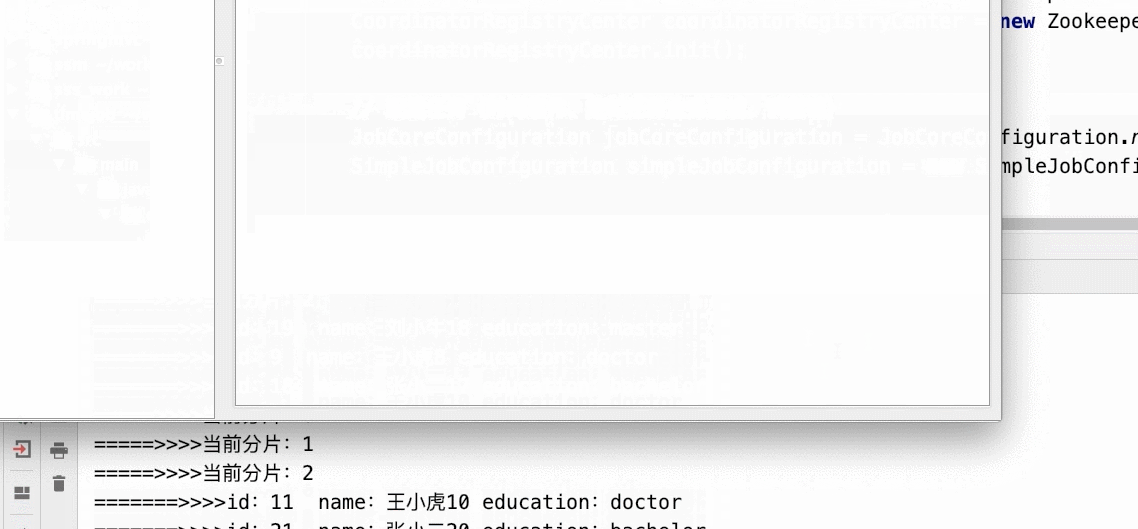
- 3个分片,启动1个main()方法(如下所示gif)
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration.newBuilder("archive-job", "1 * * * * ?", 3).build();// 任务名称 执行时间 分片数
- 3个分片2个main()
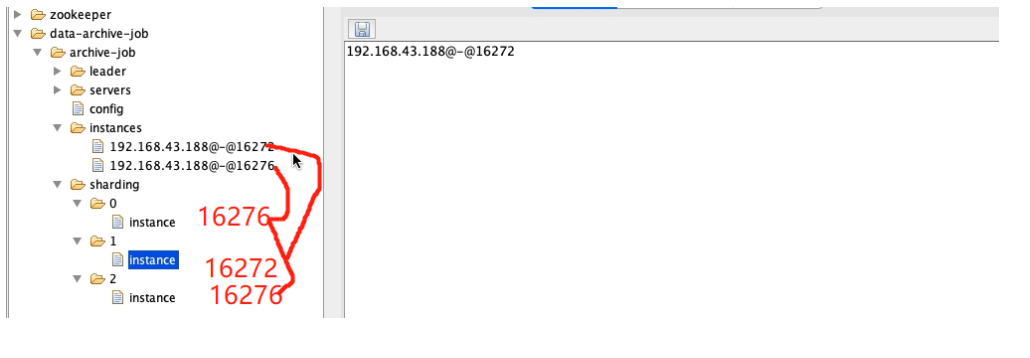
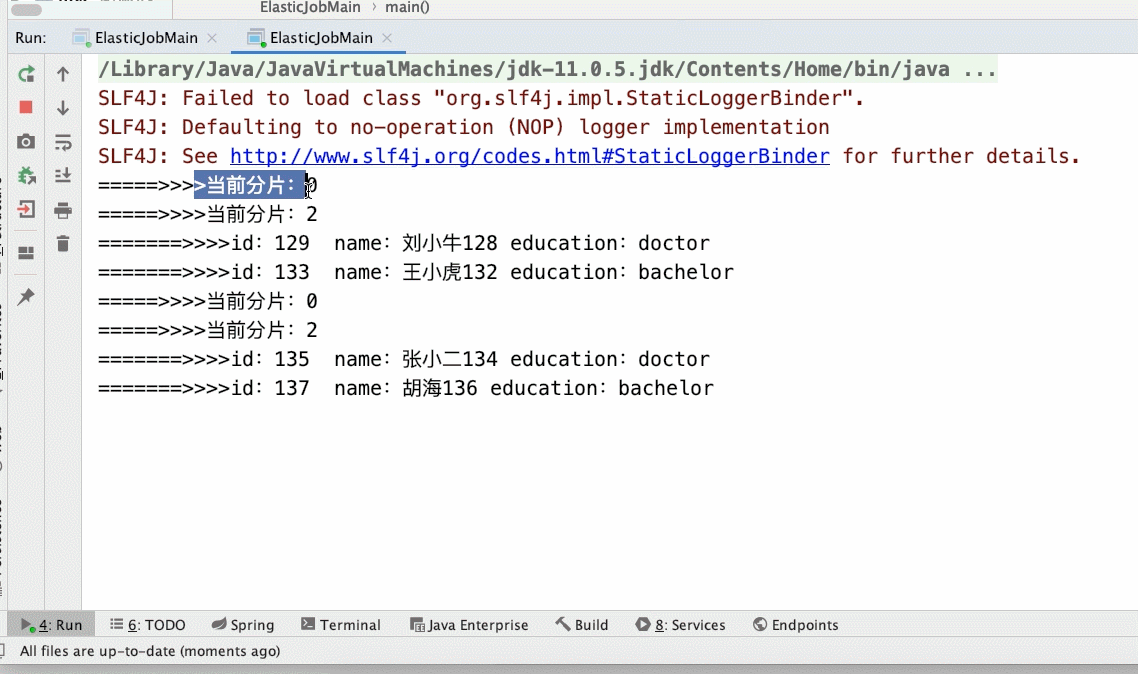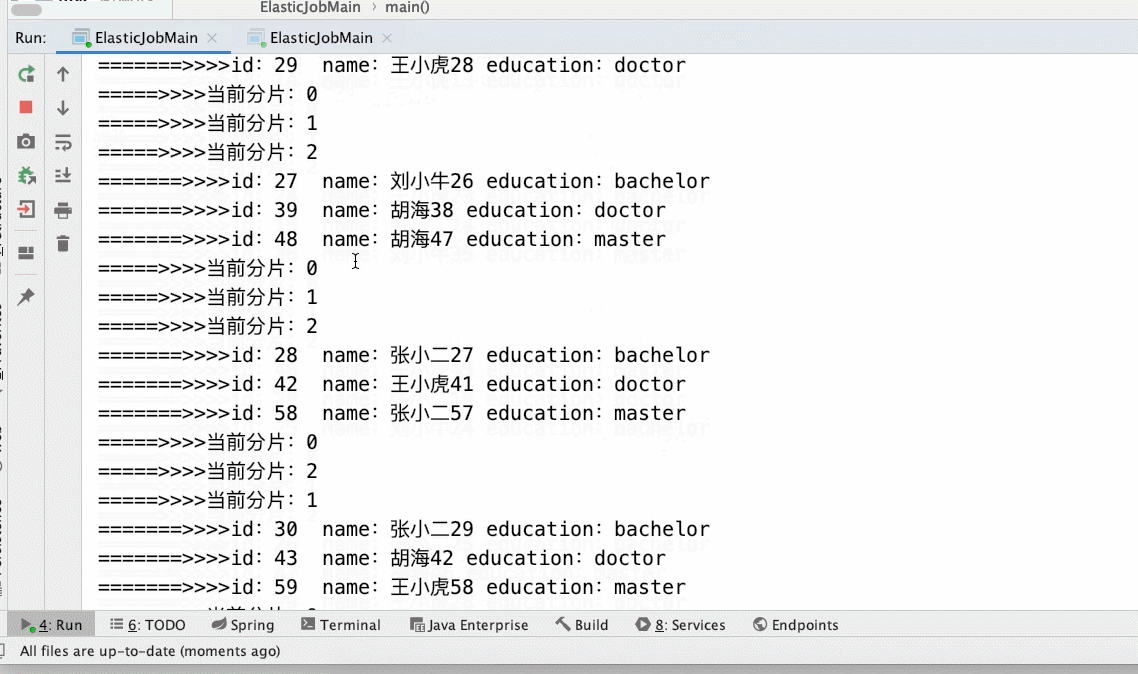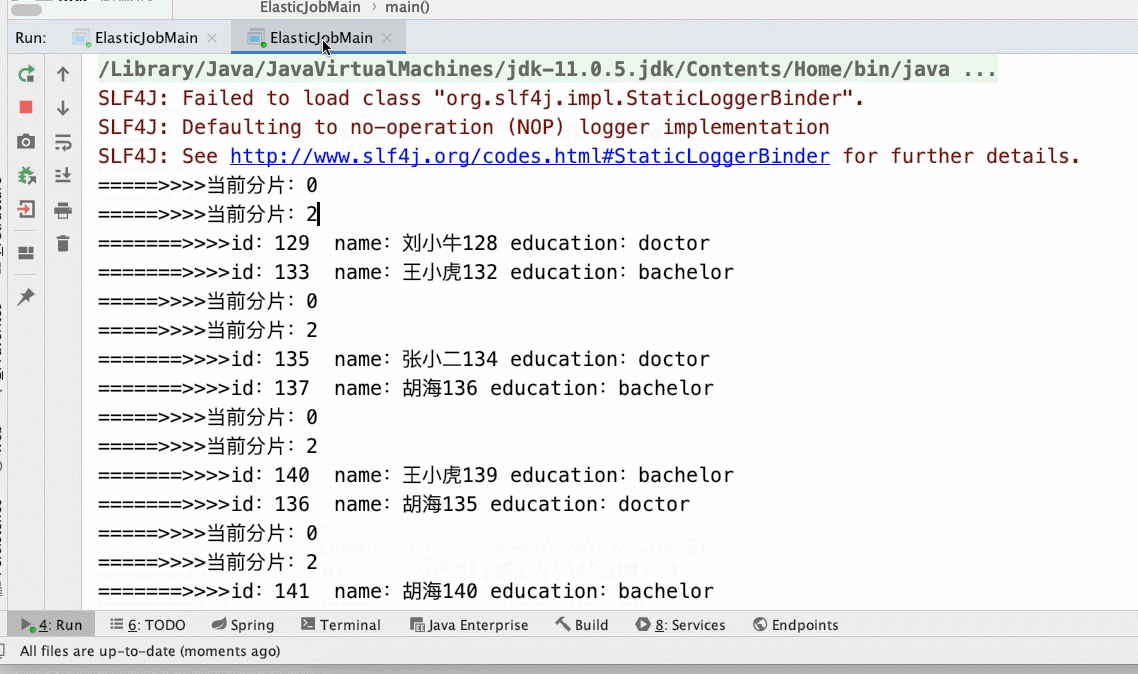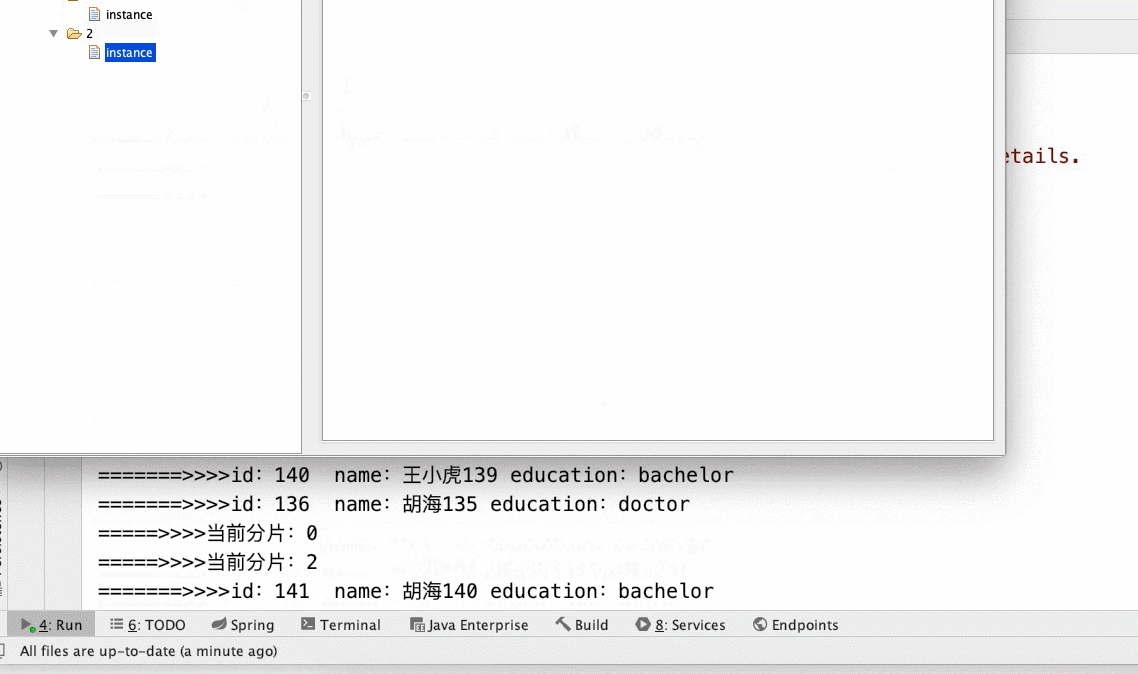
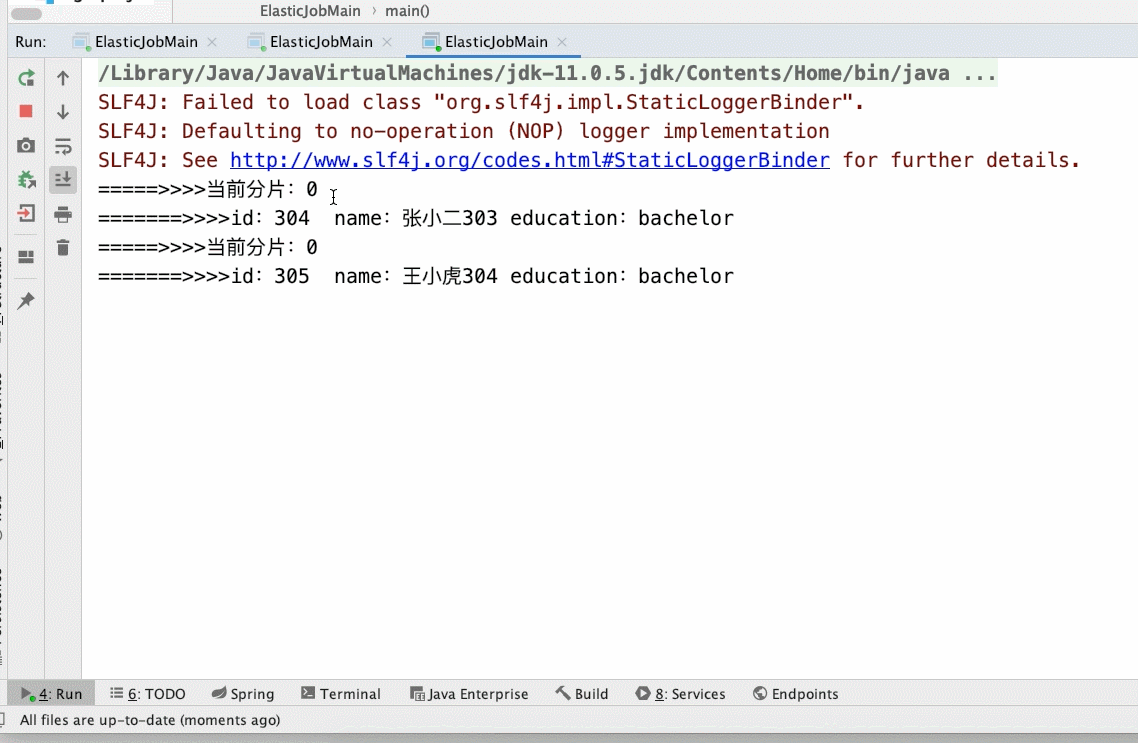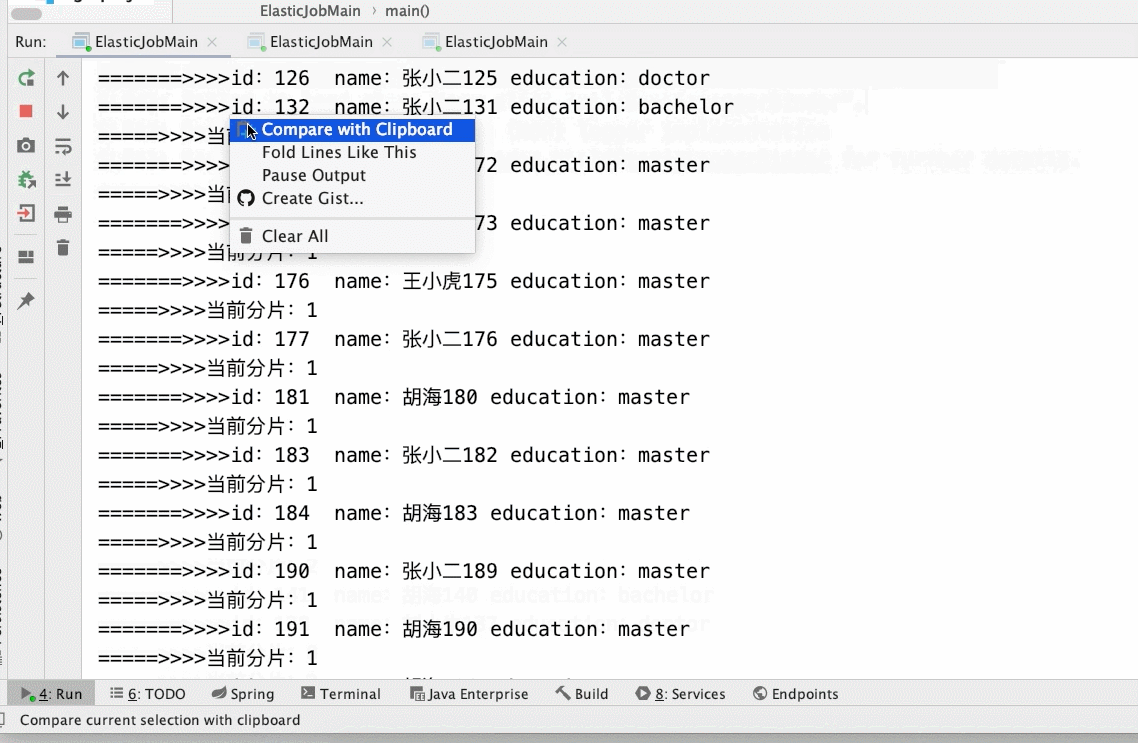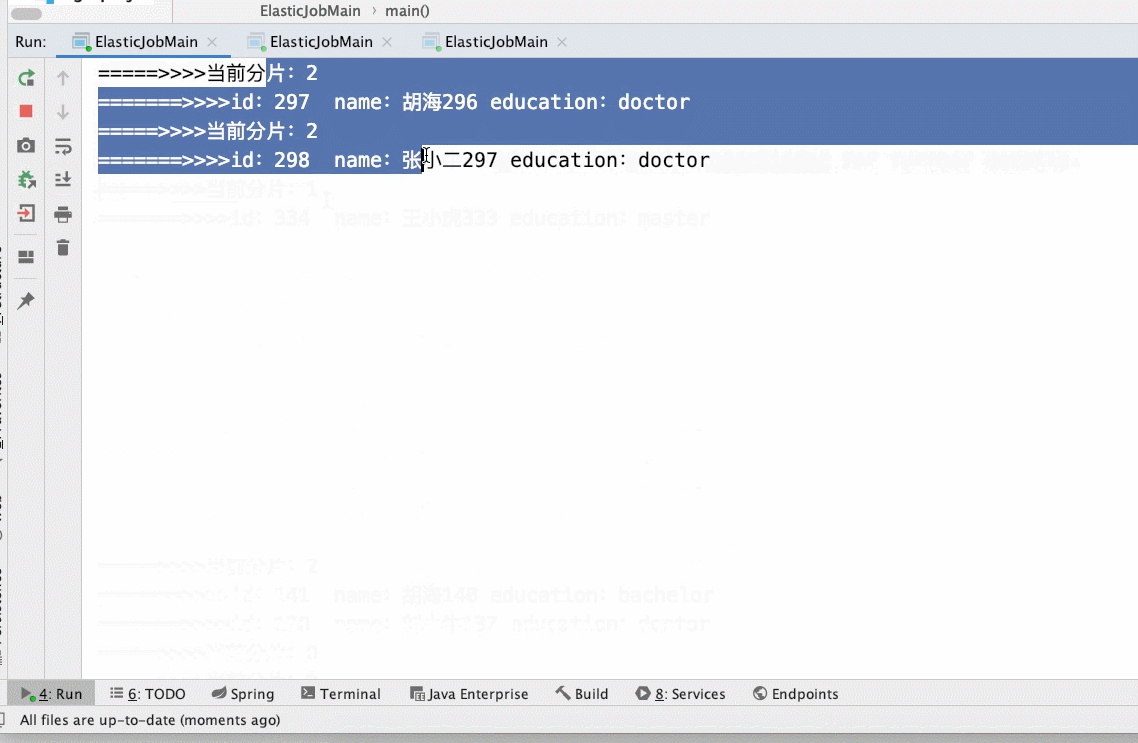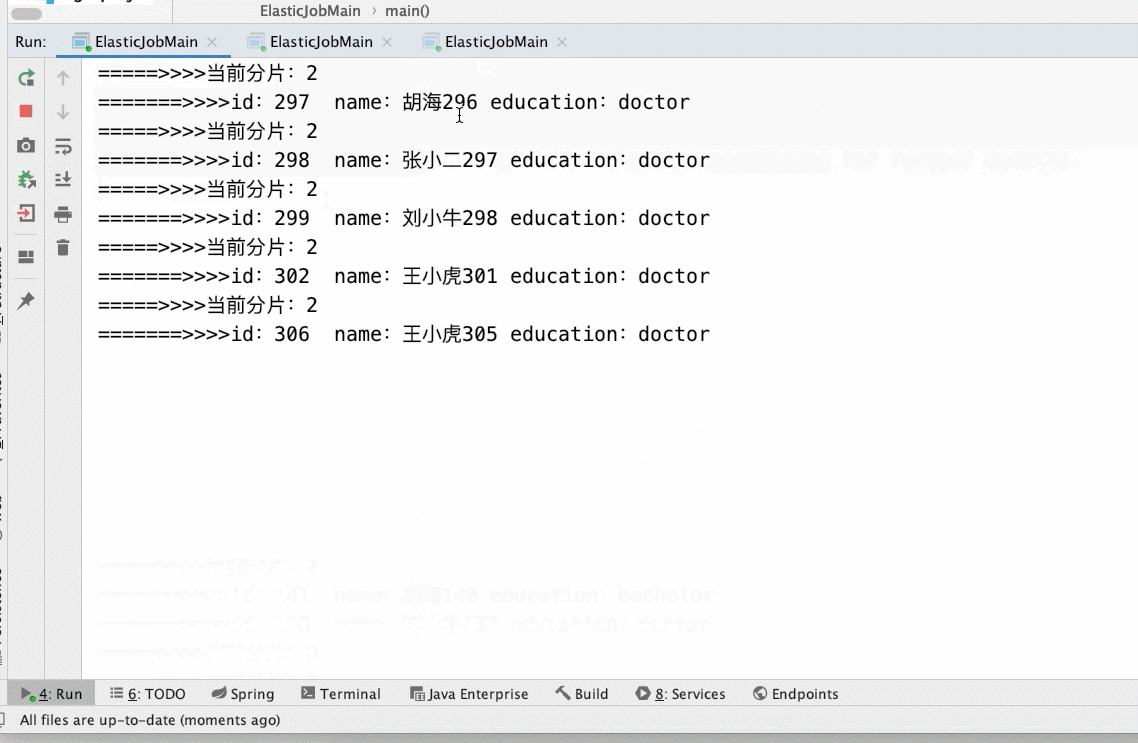
- 3个分片3个main()实列
elastic-job分布式调度与zookeeper的简单应用的更多相关文章
- Python 基于Python及zookeeper实现简单分布式任务调度系统设计思路及核心代码实现
基于Python及zookeeper实现简单分布式任务调度系统设计思路及核心代码实现 by:授客 QQ:1033553122 测试环境 功能需求 实现思路 代码实践(关键技术点实现) 代码模块组织 ...
- SpringBoot + Dubbo + zookeeper 搭建简单分布式服务
SpringBoot + Dubbo + zookeeper 搭建简单分布式服务 详细操作及源码见: https://github.com/BillyYangOne/dubbo-springboot
- 最火的分布式调度系统 XXL-JOB 安装和简单使用
唉,在谈文章之前先说一下自己的情况.原计划是在上周六写完这篇文章的,然而周六的时候打开电脑的,按照平常"惯例",先补一些 "黑色五叶草"/"进巨&qu ...
- 基于Quartz编写一个可复用的分布式调度任务管理WebUI组件
前提 创业小团队,无论选择任何方案,都优先考虑节省成本.关于分布式定时调度框架,成熟的候选方案有XXL-JOB.Easy Scheduler.Light Task Scheduler和Elastic ...
- 分布式调度任务-ElasticJob
一:问题的引出与复现 在一个风和日丽的工作日,公司运营发现系统的任务数据没有推送执行,整个流程因此停住了.我立马远程登陆服务器,查看日志,好家伙,系统在疯狂的打印相同的一段日志:c.d.d.j.i.e ...
- 分布式协调服务Zookeeper扫盲篇
分布式协调服务Zookeeper扫盲篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 身为运维工程师对kubernetes(k8s)可能比较熟,那么etcd(go语言实现)分布式协 ...
- Dubbo+Zookeeper的简单入门案例
1.1 Dubbo简介 Apache Dubbo是一款高性能的Java RPC框架.其前身是阿里巴巴公司开源的一个高性能.轻量级的开源Java RPC框架,可以和Spring框架无缝集成. 什么是R ...
- 分布式调度框架TBSchedule使用方法
一.TBSchedule简介 TBSchedule是来自淘宝的分布式调度开源框架,基于Zookeeper纯Java实现,其目的是让一种批量任务或者不断变化的任务,能够被动态的分配到多个主机的JVM中的 ...
- 分布式服务框架 Zookeeper(转)
分布式服务框架 Zookeeper -- 管理分布式环境中的数据 Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题 ...
随机推荐
- 还不懂Docker?一个故事安排的明明白白!
程序员受苦久矣 多年前的一个夜晚,风雨大作,一个名叫Docker的年轻人来到Linux帝国拜见帝国的长老. "Linux长老,天下程序员苦于应用部署久矣,我要改变这一现状,希望长老你能帮帮我 ...
- 解决NUC972使用800*480屏幕时,tslib触摸屏校准时,坐标不对称问题
1.ADC_CONF寄存器中的ADCSAMPCNT的值,设置计数器值以延长ADC起始信号周期以获得更多采样精确转换的时间 2.内核驱动配置好触摸屏ADC的驱动后,调整autoconfig.h中的CON ...
- webug第四关:告诉你了flang是5位数
第四关:告诉你了flang是5位数 开始看到有点懵 于是不要脸的看源码 burp跑弱口令
- Hadoop大数据平台搭建之前期配置(2)
环境:CentOS 7.4 (1708 DVD) 工具:VMware.MobaXterm 一. 克隆大数据集群 1. 选中已经进行了基本配置的虚拟机,进行克隆. 2. 此处改为"创建完整克 ...
- java开发两年,连Spring中bean的装配都不知道?你怎么涨薪啊
Spring 1.1.1.1 创建一个bean package com.zt.spring; public class MyBean { private String userName; privat ...
- 《图解TCP/IP》第四章
<图解TCP/IP>第四章 4.1 IP 即网际协议 4.1.1 IP(IPv4.IPv6)相当于OSI参考模型中的第3层-网络层 4.1.2 数据链路层和网络层的关系: 数据链路层的主要 ...
- Docker基础知识及入门
什么是Docker? Docker是由dotcloud公司使用golang语言进行开发的,基于Linux内核的 cgroup,namespace,以及OverlayFS类的Union FS等技术,对进 ...
- python应用(6):函数
在流程很简单的时候,或者流程不简单但我们不需要考虑开发维护成本的时候,平面地组织你的代码就够了,不用费脑子,不需要考虑层次或重用的东西.当事情变得越来越复杂时,当同行对代码质量要求越来越高时,有一些重 ...
- 小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复'CRR-FMM',即可获得电子资源. 1 Introduction In this short communication, we prese ...
- MSSQL 2014数据库Alwayson下日志过大,压缩日志的处理方法
USE [{数据库名称}] DECLARE @bakfile nvarchar(100) SET @bakfile='E:\DbLogs\log_bak_'+CONVERT(nvarchar(8),G ...