Pyhton网络爬虫实例_豆瓣电影排行榜_BeautifulSoup4方法爬取
-----------------------------------------------------------学无止境------------------------------------------------------
前言:大家好,欢迎来到誉雪飞舞的博客园,我的每篇文章都是自己用心编写,
算不上精心但是足够用心分享我的自学知识,希望大家能够指正我,互相学习成长。
转载请注明:https://www.cnblogs.com/wyl-pi/p/10510397.html
很多小伙伴可定都是喜欢看电影的,比如特效炫酷逼真的好莱坞大片,情节感人真挚的爱情电影,打斗激情四射的动作电影,,,,
所以我相信大家都有一个通问,我想看电影,但是呢到底什么电影好看啊!!有没有什么推荐之类的,比如排行榜之类的还不是很多的,
10个左右的(多了看不完还挺难受,但太多的话根本没时间看完啊,有木有....)
So,我们找一个大家都耳熟能详的豆瓣影评,其在业内还是较有权威的,嗯,,
For example:
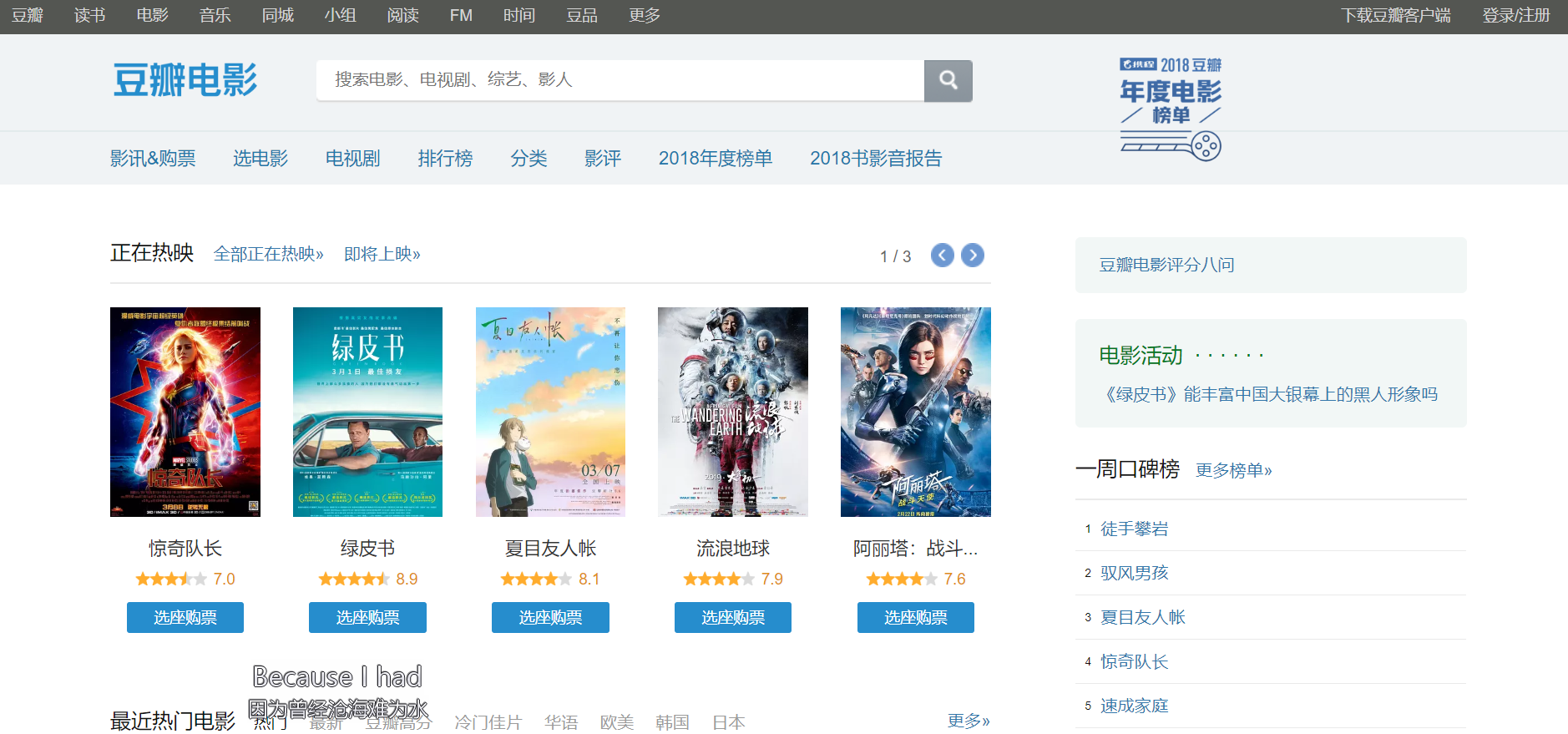
大家应该看到了右下角的 "一周口碑榜 " 没错这个小排名我喜欢,就是说我们想要找的,管你网页其他地方做得再华丽,宣传的多么天花乱坠还是没有咱这个口碑榜实在啊!!!
So,我们的活来了,盘它,哦不,是爬它。
玩笑归玩笑,言归正传,可能有的同志会说为什么你要爬虫直接看不就好了?!我会微微一笑:“这么没技术含量的操作,请问有意思么?”(虽说我承认我这篇随笔的技术水平也不高,
可以毫不忌讳地说,很低,But!我相信自己的水平和技术含量会越爱越高的,毕竟我绝不甘心与此。再者说就是他这个更新一周一周的,自己每次上网也去查我是觉得挺麻烦的,不如
做个爬虫直接代码运行,麻烦一次方便以后,好吧如果你说我强词夺理那就是吧,随便喽。)
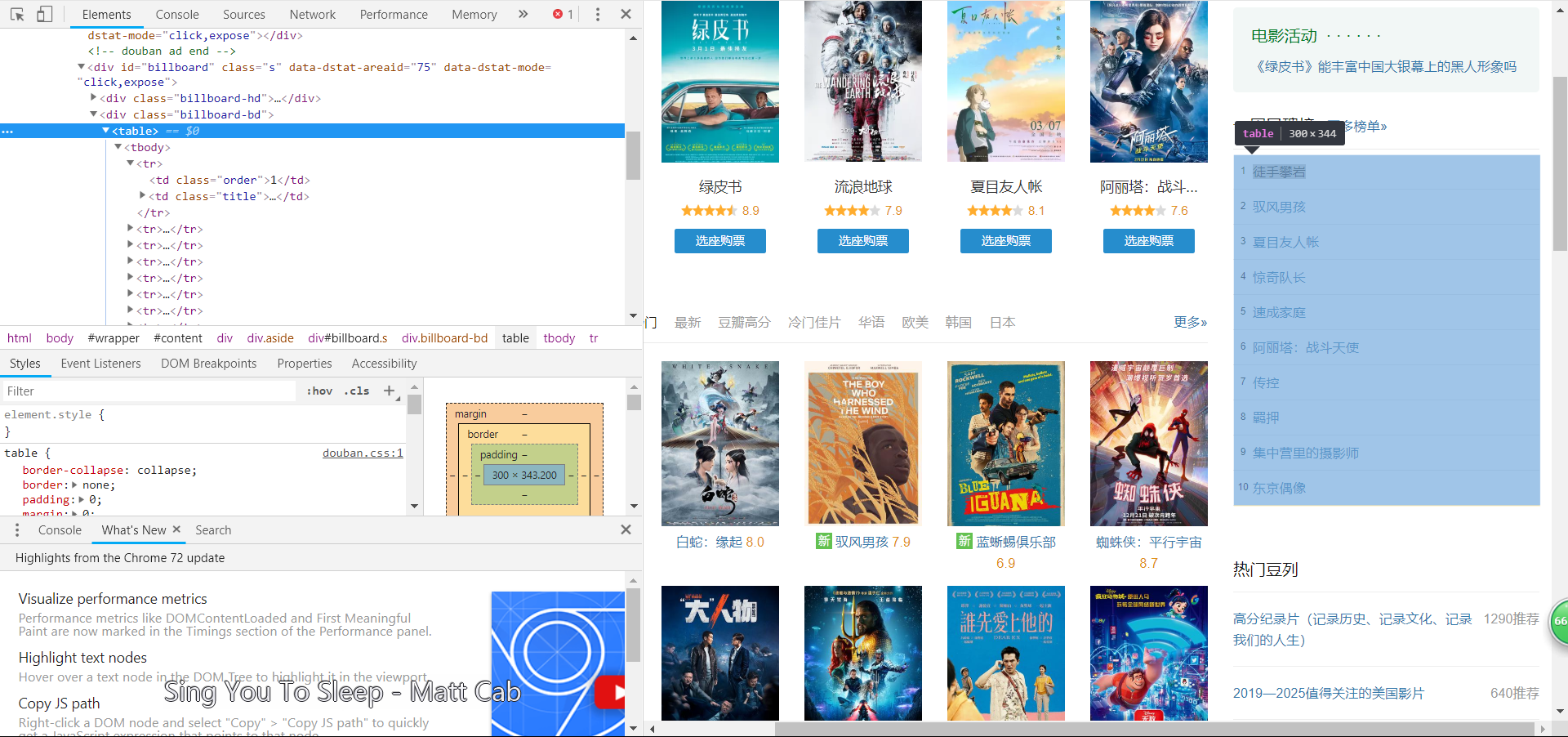
 打开网页后,F12,点击这个按钮,然后定位到下图这个框找到它属于<table>标签下的<tbody>标签;这位后面我们的爬取打下了铺垫。(当然这是方法之一)
打开网页后,F12,点击这个按钮,然后定位到下图这个框找到它属于<table>标签下的<tbody>标签;这位后面我们的爬取打下了铺垫。(当然这是方法之一)
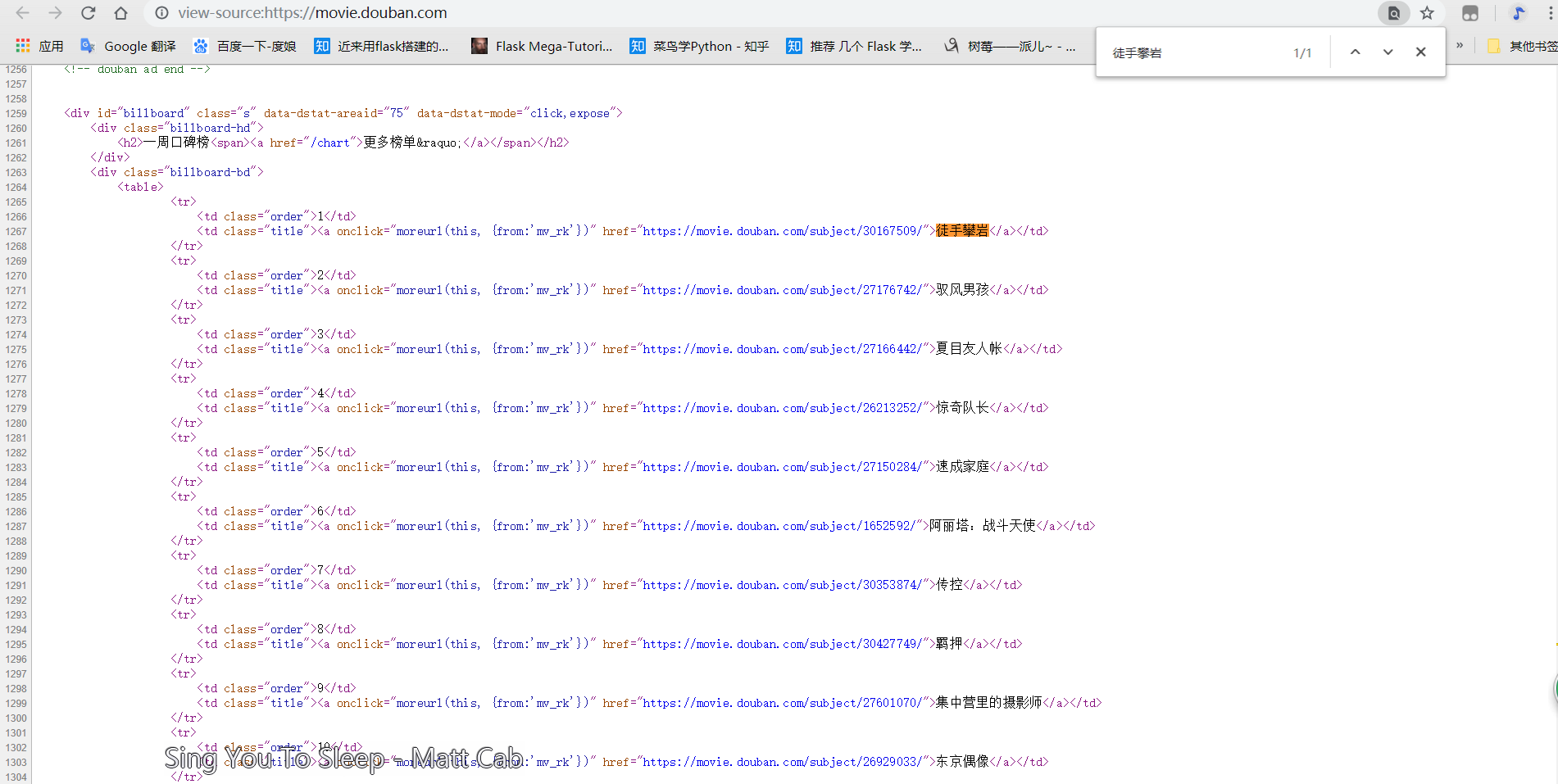
方法之二:
直接快捷键Ctrl+U或者右键 “ 查看网页源代码 ” ,然后Ctrl+F查找 “ 徒手攀岩 ” ;
这下我们就知道了我们所要爬取网页的基本框架是什么样的了,从而进行后续的操作。
代码如下:
import requests
from bs4 import BeautifulSoup
import bs4 def getHtmlText(url):
try:
r = requests.get(url,timeout = 30)
print("raise_stsus = {}".format(r.raise_for_status()))
print("获取状态完毕")
r.encoding = r.apparent_encoding
return r.text
except:
print("get information with error!") def movieSoupList(movielist,demo):
try:
soup = BeautifulSoup(demo,"html.parser")
tables = soup.find_all("table")
#print("tables is {}\n\n".format(tables))
tab = tables[1]
#if isinstance(tab,bs4.element.Tag):
# print("yaoxi!!!!!!!!")
#print("tab is {}\n\n".format(tab)) #tags = tab.find("tr")
#print(type(tags)) #print("tags = {}\n".format(tags))
tags = tab.contents #print("tages {} ".format(tab.contents)) # ***** .contents 方法 ***** #print(type(tab.contents)) #//<class'list'> #i = 0
for tr in tags:
#i = i+1 #print("i = {}\n".format(i))
#print("transfor finished")
if isinstance(tr,bs4.element.Tag):
tds = tr("td") # ***** tr("td")这步也很关键 ***** #print("tds {}".format(tds))#print("list is ok")
movielist.append([tds[0].string,tds[1].string])
#print("transfor finished")
#print("movielist is {}".format(movielist))
except:
print("transfor error") def printMovieList(movielist,num):
model = "{0:^10}\t{1:^20}"
print(model.format("排名","影片名",chr(12288)))
try:
for i in range(num):
m = movielist[i]
print(model.format(m[0],m[1],chr(12288)))
except:
print("printMovieList error\n") def main():
num = 10
url = 'https://movie.douban.com/'
movielist = []
demo = getHtmlText(url)
movieSoupList(movielist,demo)
#print("movielist is \n{}\n\n".format(movielist))
printMovieList(movielist,num) main()
我在代码里的注释也很清楚了,如果还不懂可以评论或私信我,里面有我当时调试的测试代码
删除了一部分,剩下的大部分都注释掉了。如果有的童鞋们想试试可以像我这样测试,然后一步
步接近自己想要的样子,直至完成项目。
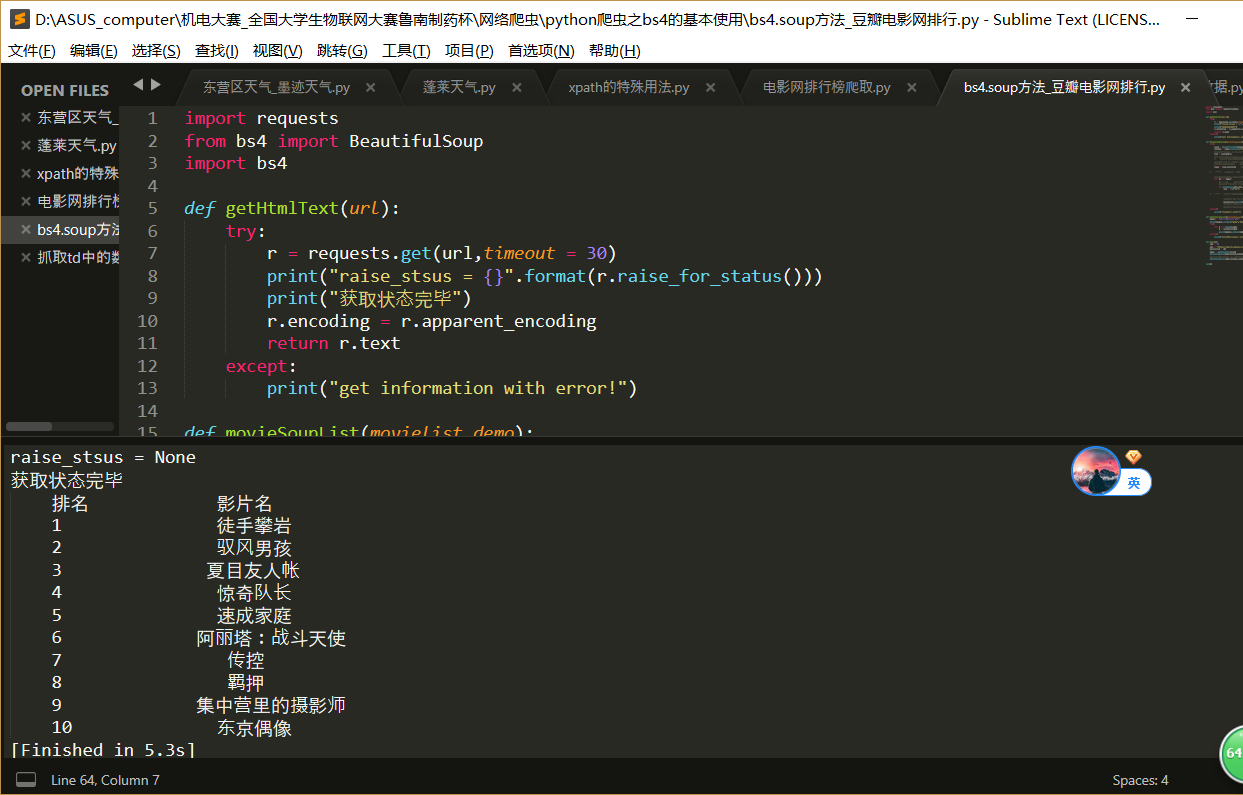
运行结果就是这样:
总结:
这个方法的可编辑性较高容易理解很简单,但相对应的短板就是代码冗长编写麻烦费时如果出错不好修改,
总之中规中矩,下一篇文章我将带您欣赏一下Python的Xpath方法的魅力所在。
如果觉得我的文章还不错,关注一下,顶一下 ,我将会用心去创作更好的文章,敬请期待。
Pyhton网络爬虫实例_豆瓣电影排行榜_BeautifulSoup4方法爬取的更多相关文章
- Pyhton网络爬虫实例_豆瓣电影排行榜_Xpath方法爬取
-----------------------------------------------------------学无止境------------------------------------- ...
- selenium和phantomjs,完成豆瓣音乐排行榜的内容爬取
代码要多敲 注释要清晰 哪怕再简单 #使用selenium和phantomjs,完成豆瓣音乐排行榜的内容爬取 #地址:https://music.douban.com/chart #导入需要的模块 f ...
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
爬取目标站点里所有的网页 使用的系统:Windows 10 64位 Python语言版本:Python 3.5.0 V 使用的编程Python的集成开发环境:PyCharm 2016 04 一 . 首 ...
- 转:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程 上述安装教程已实践,可行.(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所 ...
- Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程 上述安装教程已实践,可行.(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 豆瓣电影排行简单数据爬取_pyhton
先安装一下requests和bs4库: cmd下面:python -m pip install bs4 -i https://pypi.douban.com/simple 代码: import req ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
随机推荐
- LwIP协议栈开发嵌入式网络的三种方法分析
LwIP协议栈开发嵌入式网络的三种方法分析 摘要 轻量级的TCP/IP协议栈LwIP,提供了三种应用程序设计方法,且很容易被移植到多任务的操作系统中.本文结合μC/OS-II这一实时操作系统,以 ...
- MySQL中的事件/定时任务
转载自:http://www.cnblogs.com/chenpi/p/5137310.html 什么是事件 一组SQL集,用来执行定时任务,跟触发器很像,都是被动执行的,事件是因为时间到了触发执行, ...
- stl学习之namespace
一.为什么需要命名空间(问题提出) 命名空间是ANSIC++引入的可以由用户命名的作用域,用来处理程序中常见的同名冲突. 在 C语言中定义了3个层次的作用域,即文件(编译单元).函数和复合语句.C++ ...
- Oracle批量删除表格数据
在开发阶段往Oracle数据库中多个表格中导入了许多测试数据,倘若一张张表执行"truncate table tablename"语句显得十分繁琐.在PL/SQL中可以用代码进行批 ...
- 微信小程序车牌号码模拟键盘输入
微信小程序车牌号码模拟键盘输入练习, 未经允许,禁止转载,抄袭,如需借鉴参考等,请附上该文章连接. 相关资料参考:https://blog.csdn.net/littlerboss/article/d ...
- Spring security学习笔记(二)
对比两种承载认证信息的方式: session vs token token验证方案: session验证方案: session即会话是将用户信息保存在服务端,根据请求携带的session_id,从服务 ...
- EFI分区删除的有效方法
用Diskpart命令,可以方便的删除EFI系统分区. 一,win + R, 输入cmd,回车. 二,输入 Diskpart ,回车,得到 三,再输入 list disk , 回车,查看磁盘信息 四, ...
- Arduino UNO仿真开发环境设置和仿真运行
一. Proteus仿真平台简介 Proteus软件是英国Labcenter electronics公司出版的EDA工具软件(该软件中国总代理为广州风标电子技术有限公司).它不仅具有其它EDA工具软件 ...
- Linux内核调用I2C驱动_驱动嵌套驱动方法
禁止转载!!!! Linux内核调用I2C驱动_以MPU6050为例 0. 导语 最近一段时间都在恶补数据结构和C++,加上导师的事情比较多,Linux内核驱动的学习进程总是被阻碍.不过,十一假期终于 ...
- Python 爬虫 (五)
# 头条街拍图片爬取 1 import re import requests from urllib import request import json import os i = 0 header ...