Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影)
ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互
对于ajax:
- 1.一定会有 url,请求方法(get, post),可能有数据
- 2.一般使用 json 格式
爬取豆瓣电影
- 网站分析:
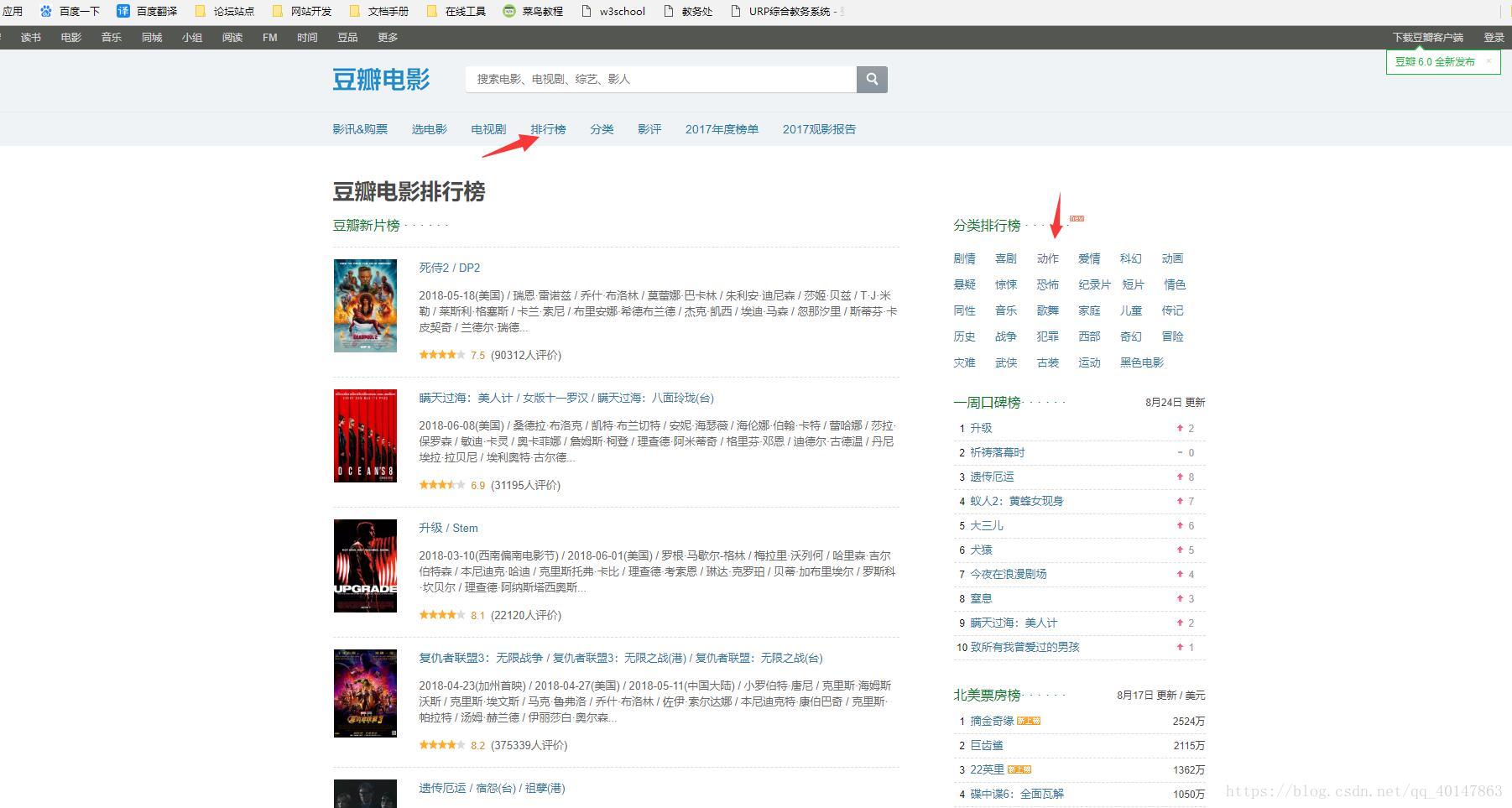
- 打开豆瓣电影网站:https://movie.douban.com/,选择【排行榜】,点击【动作】分类
- 一直往下滑,可以看到这样的效果:快到低的时候又有了新的内容,也就是往下没完
- 基本可以判定使用了 ajax 请求,进行异步的加载
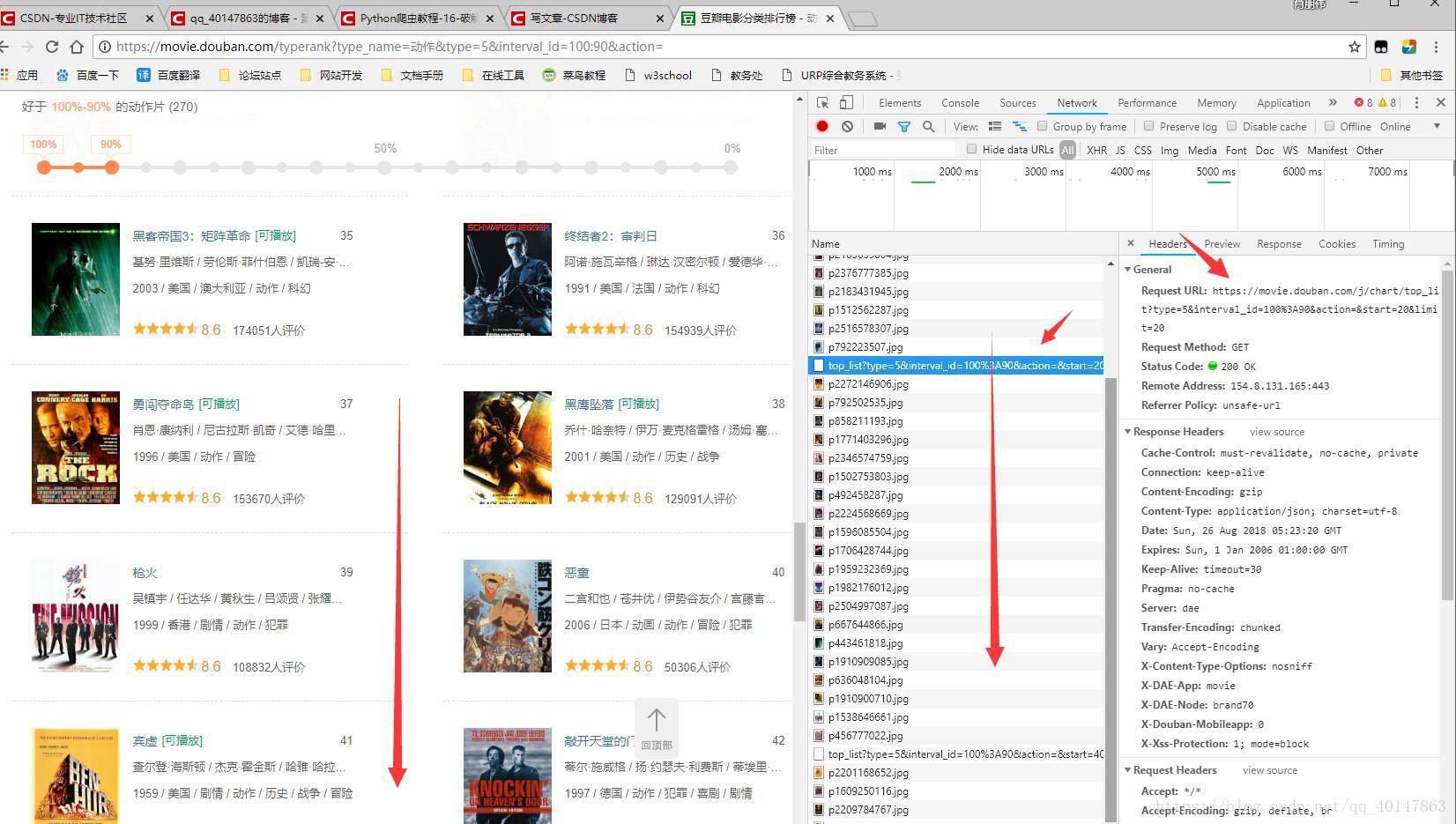
- 然后进去检查请求的信息:
- 1.右键【检查】>【Network】
- 2.向下滚动页面
- 3.可以看到请求在不断不更新,点击一个请求,就可以看到请求的信息
- 代码文件:https://xpwi.github.io/py/py爬虫/py19db.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
print(data)
运行结果
可以看到结果在一行显示

修改输出格式
- 对于返回的json数据,我们选择想要的内容,想要的格式输出
- 代码文件:https://xpwi.github.io/py/py爬虫/py19db2.py
# 爬取豆瓣电影数据
# 了解ajax的爬取方式
# https://movie.douban.com/
from urllib import request
import json
# url信息:interval_id表示排名段(可自行修改),limit限制20个
url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20"
rsp = request.urlopen(url)
data = rsp.read().decode()
data = json.loads(data)
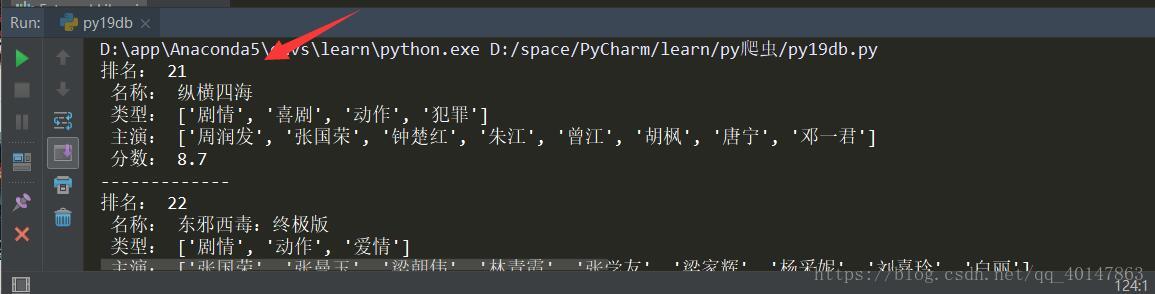
# 遍历输出每个'k'和'v'的值
for item in data:
print("排名:", item['rank'], "\n",
"名称:", item['title'], "\n",
"类型:", item['types'], "\n",
"主演:", item['actors'], "\n",
"分数:", item['score'],"\n-------------",)
运行结果
这里结果就比较顺眼了,如果需要更改排名段,因为是get请求,修改需要在url参数即可
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-17-ajax爬取实例(豆瓣电影)的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
python爬虫教程-16-破解js加密实例(有道在线翻译) 在爬虫爬取网站的时候,经常遇到一些反爬虫技术,比如: 加cookie,身份验证UserAgent 图形验证,还有很难破解的滑动验证 js签 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
随机推荐
- 高阶篇:4.2.2)DFMEA层级分明的失效模式、失效后果、失效原因
本章目的:明确失效模式.失效后果.失效原因的定义,分清楚层次关系,完成DFMEA这部分的填写. 1.失效模式,失效后果,失效原因的定义: 这是FEMEA手册第四册中的定义. 1.1 潜在失效模式 (b ...
- 【算法笔记】B1051 复数乘法
题目链接:https://pintia.cn/problem-sets/994805260223102976/problems/994805274496319488 思路: 难点在于对复数其他形式的认 ...
- 123th LeetCode Weekly Contest Broken Calculator
On a broken calculator that has a number showing on its display, we can perform two operations: Doub ...
- redis实现 msetex和 getdel命令
1.redis本身不提供 msetex命令(批量增加key并设置过期时间) class RedisExtend { private static final Logger logger = Logge ...
- cordova 更改app的图标
写在前面:cordova 使一个前端开发者成为一个“假”的android开发人员,不得不说提供给我们巨大的方便~,cordova打包生成的apk的默认样式和启动的名字真的是需要我们字更改的:本文将记录 ...
- 基于python实现Oracle数据库连接查询操作
使用python语言连接Oracle数据库配置 #coding:utf-8 import cx_Oracle as oracle db=oracle.connect('root/123456@192. ...
- Net操作Excel,不依赖服务器端环境配置(终极方法NPOI)转。
这是起因,为什么会需要用到这个,主要是分析了一下为什么从oledb那个方式换成这个方式.文章见链接 http://www.cnblogs.com/Jerseyblog/p/6410703.html 前 ...
- KOA 与 CO 实现浅析
KOA 与 CO 的实现都非常的短小精悍,只需要花费很短的时间就可以将源代码通读一遍.以下是一些浅要的分析. 如何用 node 实现一个 web 服务器 既然 KOA 实现了 web 服务器,那我们就 ...
- jsp模板添加URL定位语句
html的head头中加入以下语句,方便url链接诶编写定位 <base href="${pageContext.request.scheme}://${pageContext.req ...
- unity接入安卓sdk (unity调用安卓工程)
1.安装jdk 并且配置环境,这个网上资料很多,这里不说了 2.安卓开发软件eclipse集成环境版 下载地址 http://tools.android-studio.org/index.php/ad ...