Node.js 4493图片批量下载爬虫1.00
这个爬虫依然需要iconv转码,想不到如今非utf8的网页还这么多。另外此网页找下一页的方式比较异常,又再次借助了正则表达式。
代码如下:
//======================================================
// 4493图片批量下载爬虫1.00
// 2017年11月19日
//======================================================
// 内置https模块
var https=require("https");
// 内置http模块
var http=require("http");
// 内置文件处理模块,用于创建目录和图片文件
var fs=require('fs');
// 用于转码。非Utf8的网页如gb2132会有乱码问题,需要iconv将其转码
var iconv = require('iconv-lite');
// cheerio模块,提供了类似jQuery的功能,用于从HTML code中查找图片地址和下一页
var cheerio = require("cheerio");
// 请求参数JSON。http和https都有使用
var options;
// request请求
var req;
// 图片数组,找到的图片地址会放到这里
var pictures=[];
// 存放图片的目录
var folder="";
//--------------------------------------
// 爬取网页,找图片地址,再爬
// pageUrl sample:https://www.4493.com/xingganmote/136346/1.htm
// pageUrl sample:
//--------------------------------------
function crawl(pageUrl){
console.log("Current page="+pageUrl);
// 得到hostname和path
var currUrl=pageUrl.replace("https://","");
var pos=currUrl.indexOf("/");
var hostname=currUrl.slice(0,pos);
var path=currUrl.slice(pos);
//console.log("hostname="+hostname);
//console.log("path="+path);
// 初始化options
options={
hostname:hostname,
port:443,
path:path,// 子路径
method:'GET',
};
req=https.request(options,function(resp){
var html = [];
resp.on("data", function(data) {
html.push(data);
})
resp.on("end", function() {
var buffer = Buffer.concat(html);
var body = iconv.decode(buffer,'gb2312'); // header里面有<meta http-equiv="Content-Type" content="text/html; charset=gb2312">字样都需要iconv帮忙转码
//console.log(body);
var $ = cheerio.load(body);
var picCount=0;
// 找图片放入数组
$(".picsbox p img").each(function(index,element){
var picUrl=$(element).attr("src");
console.log(picUrl);
if(picUrl.indexOf('.jpg')!=-1){
pictures.push(picUrl);
picCount++;
}
})
console.log("找到图片"+picCount+"张.");
var curr=0;
$(".page a.current").each(function(index,element){
var text=$(element).text();
curr=parseInt(text);
//console.log("curr="+curr);
})
var next=0;
$("#nextpage").each(function(index,element){
var text=$(element).attr("href");
var reg=/javascript:gotourl[(]'(\d+).htm'[)]/g;
var res;
while((res = reg.exec(text)) != null){
next=parseInt(res[1]);
//console.log("next="+next);
}
})
var nextPageUrl=null;
if(curr!=next){
var pos=pageUrl.lastIndexOf("/");
nextPageUrl= pageUrl.slice(0,pos+1)+next+".htm";
//console.log("nextPageUrl="+nextPageUrl);
}
// 找下一页
if(nextPageUrl==null){
console.log(pageUrl+"已经是最后一页了.\n");
saveFile(pageUrl,pictures);// 保存
download(pictures);
}else{
console.log("继续下一页");
crawl(nextPageUrl);
}
}).on("error", function() {
saveFile(pageUrl,pictures);// 保存
console.log("crawl函数失败,请进入断点续传模式继续进行");
})
});
// 超时处理
req.setTimeout(7500,function(){
req.abort();
});
// 出错处理
req.on('error',function(err){
console.log('请求发生错误'+err);
saveFile(pageUrl,pictures);// 保存
console.log("crawl函数失败,请进入断点续传模式继续进行");
});
// 请求结束
req.end();
}
//--------------------------------------
// 下载图片
//--------------------------------------
function download(pictures){
var total=0;
total=pictures.length;
console.log("总计有"+total+"张图片将被下载.");
appendToLogfile(folder,"总计有"+total+"张图片将被下载.\n");
for(var i=0;i<pictures.length;i++){
var picUrl=pictures[i];
downloadPic(picUrl,folder);
}
}
//--------------------------------------
// 写log文件
//--------------------------------------
function appendToLogfile(folder,text){
fs.appendFile('./'+folder+'/log.txt', text, function (err) {
if(err){
console.log("不能书写log文件");
console.log(err);
}
});
}
//--------------------------------------
// 取得当前时间
//--------------------------------------
function getNowFormatDate() {
var date = new Date();
var seperator1 = "-";
var seperator2 = "_";
var month = date.getMonth() + 1;
var strDate = date.getDate();
if (month >= 1 && month <= 9) {
month = "0" + month;
}
if (strDate >= 0 && strDate <= 9) {
strDate = "0" + strDate;
}
var currentdate =date.getFullYear() + seperator1 + month + seperator1 + strDate
+ " " + date.getHours() + seperator2 + date.getMinutes()
+ seperator2 + date.getSeconds();
return currentdate;
}
//--------------------------------------
// 下载单张图片
// picUrl sample:http://img.1985t.com/uploads/attaches/2017/11/136398-mrani71.jpg
//--------------------------------------
function downloadPic(picUrl,folder){
console.log("图片:"+picUrl+"下载开始");
// 得到hostname,path和port
var currUrl=picUrl.replace("http://","");
var pos=currUrl.indexOf("/");
var hostname=currUrl.slice(0,pos);
var path=currUrl.slice(pos);
// 有端口加端口,没有端口默认80
var port=80;
//console.log("hostname="+hostname);
//console.log("path="+path);
//console.log("port="+port);
var picName=currUrl.slice(currUrl.lastIndexOf("/"));
// 初始化options
options={
hostname:hostname,
port:port,
path:path,
method:'GET',
};
req=http.request(options,function(resp){
var imgData = "";
resp.setEncoding("binary");
resp.on('data',function(chunk){
imgData+=chunk;
});
resp.on('end',function(){
// 创建文件
var fileName="./"+folder+picName;
fs.writeFile(fileName, imgData, "binary", function(err){
if(err){
console.log("[downloadPic]文件 "+fileName+" 下载失败.");
console.log(err);
appendToLogfile(folder,"文件 "+picUrl+" 下载失败.\n");
}else{
appendToLogfile(folder,"文件 "+picUrl+" 下载成功.\n");
console.log("文件"+fileName+"下载成功");
}
});
});
});
// 超时处理
req.setTimeout(7500,function(){
req.abort();
});
// 出错处理
req.on('error',function(err){
if(err){
console.log('[downloadPic]文件 '+picUrl+" 下载失败,"+'因为'+err);
appendToLogfile(folder,"文件"+picUrl+"下载失败.\n");
}
});
// 请求结束
req.end();
}
//--------------------------------------
// 程序入口
//--------------------------------------
function getInput(){
process.stdin.resume();
process.stdout.write("\033[33m 新建模式输入第一页URL,断点续传模式输入0,请输入: \033[39m");// 草黄色
process.stdin.setEncoding('utf8');
process.stdin.on('data',function(text){
var input=text.trim();
process.stdin.end();// 退出输入状态
if(text.trim()=='0'){
process.stdout.write("\033[36m 进入断点续传模式. \033[39m"); // 蓝绿色
// Read File
fs.readFile('./save.dat','utf8',function(err,data){
if(err){
console.log('读取文件save.dat失败,因为'+err);
}else{
//console.log(data);
var obj=JSON.parse(data);
pictures=obj.pictures;
console.log('提取图片'+pictures.length+'张');
folder=obj.folder;
// 创建目录
fs.mkdir('./'+folder,function(err){
if(err){
console.log("目录"+folder+"已经存在");
}
});
crawl(obj.url);
}
});
// Resume crawl
}else{
process.stdout.write("\033[35m 进入新建模式. \033[039m"); //紫色
folder='pictures('+getNowFormatDate()+")";
// 创建目录
fs.mkdir('./'+folder,function(err){
if(err){
console.log("目录"+folder+"已经存在");
}
});
crawl(input);
}
});
}
//--------------------------------------
// 将爬行中信息存入数据文件
//--------------------------------------
function saveFile(url,pictures){
var obj=new Object;
obj.url=url;
obj.pictures=pictures;
obj.folder=folder;
var text=JSON.stringify(obj);
fs.writeFile('./save.dat',text,function(err){
if(err){
console.log('写入文件save.dat失败,因为'+err);
}
});
}
// 调用getInput函数,程序开始
getInput();
附个运行时控制台贴图:
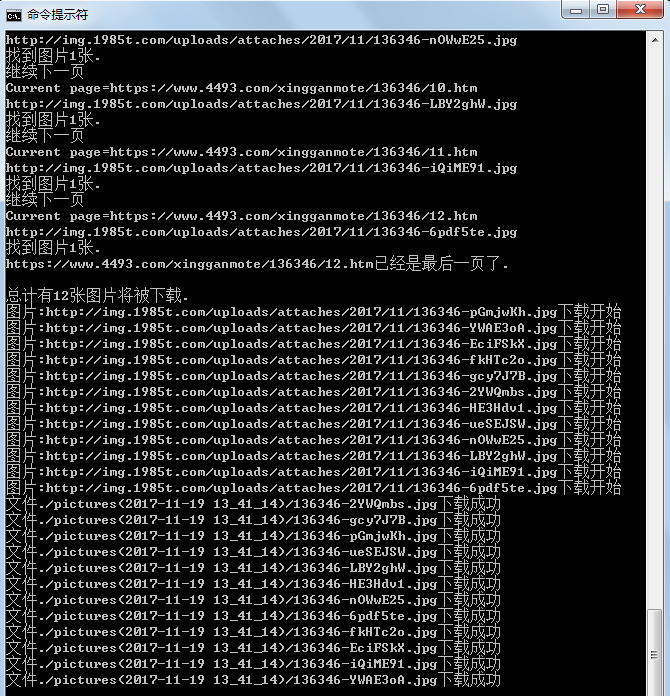
Node.js 4493图片批量下载爬虫1.00的更多相关文章
- Node.js mzitu图片批量下载爬虫1.00
又攻下一座山头. //====================================================== // mzitu图片批量下载爬虫1.00 // 2017年11月19 ...
- Node.js monly图片批量下载爬虫1.00
此爬虫又用到了iconv转码,代码如下: //====================================================== // mmonly图片批量下载爬虫1.00 ...
- Node.js m03122图片批量下载爬虫1.00
//====================================================== // m03122图片批量下载爬虫1.00 // 2017年11月18日 //==== ...
- Node.js mm131图片批量下载爬虫1.00 iconv协助转码
//====================================================== // mm131图片批量下载爬虫1.00 // 2017年11月15日 //===== ...
- Node.js mimimn图片批量下载爬虫 1.00
这个爬虫在Referer设置上和其它爬虫相比有特殊性.代码: //====================================================== // mimimn图片批 ...
- Node.js nvshens图片批量下载爬虫 1.00
//====================================================== // www.nvshens.com图片批量下载Node.js爬虫1.00 // 此程 ...
- Node.js mm131图片批量下载爬虫1.01 增加断点续传功能
这里的断点续传不是文件下载时的断点续传,而是指在爬行页面时有时会遇到各种网络中断而从中断前的页面及其数据继续爬行的过程,这个过程和断点续传原理上相似故以此命名.我的具体做法是:在下载出现故障或是图片已 ...
- Node.js abaike图片批量下载爬虫1.02
//====================================================== // abaike图片批量下载爬虫1.02 // 用最近的断点续传框架改写原有1.01 ...
- Node.js nvshens图片批量下载爬虫1.01
//====================================================== // nvshens图片批量下载爬虫1.01 // 用最近的断点续传框架改写原有1.0 ...
随机推荐
- 【剑指offer】面试题 64. 求 1+2+3+...+n
面试题 64. 求 1+2+3+...+n 题目:求1+2+3+...+n,要求不能使用乘除法.for.while.if.else.switch.case等关键字及条件判断语句(A?B:C). 1.采 ...
- (4) go 运算符
1. (1) 整数相除,结果是小数,会舍去小数部分 (2) 使用自增自减时, ++ -- 必须单独一行 (3)只有后 a++,没有前 ++a 2. 3. 4. 5 6. 7. 8.
- Keras 训练时出现 CUDA_ERROR_OUT_OF_MEMORY 错误
不用惊慌,再试一次.估计当时GPU内存可分配不足,可手动结束所有python程序后释放相关GPU内存,或者重新运行一次终端
- 洛谷——P1994 有机物燃烧
P1994 有机物燃烧 题目背景 本来准备弄难点的,还是算了吧 题目描述 输入一种有机物,输出与氧气反应化学方程式中CO2和H2O的系数 输入输出格式 输入格式: 一行,一个字符串,表示有机物 输出格 ...
- Section One
1.1.1 #include <iostream> using namespace std; int main() { int a,b,N; cin >> N; while ( ...
- Python标准库:内置函数divmod(a, b)
本函数是实现a除以b,然后返回商与余数的元组. 如果两个参数a,b都是整数,那么会采用整数除法,结果相当于(a//b, a % b).如果a或b是浮点数,相当于(math.floor(a/b), a% ...
- python基础之带参数装饰器和迭代器
带参数的装饰器:就是在原装饰器外再包一层函数 def auth(driver='file'): def auth2(func): def wrapper(*args,**kwargs): name=i ...
- Codeforces Round #345 (Div. 2) D. Image Preview 暴力 二分
D. Image Preview 题目连接: http://www.codeforces.com/contest/651/problem/D Description Vasya's telephone ...
- svn安装和配置
安装svn 参考http://blog.csdn.net/dl425134845/article/details/41978541 系统版本 uname -a # 查看内核/操作系统/CPU信息 he ...
- nginx实现简单负载均衡
配置文件 主文件: /etc/nginx/nginx.config 例当前在22.22.22.4服务器 //同时开另外三个服务器 可以在http{} 里添加 include /etc/nginx/si ...