【7】Manacher算法学习笔记
前言
Manacher 算法是最好写的字符串算法。——教练
暴力求法
给出一个只由小写英文字符 \(\texttt a,\texttt b,\texttt c,\ldots\texttt y,\texttt z\) 组成的字符串 \(S\),求 \(S\) 中最长回文串的长度 。
暴力算法 \(1\):
枚举左右端点,\(O(n)\) 判断是否为回文串,时间复杂度 \(O(n^3)\)。
暴力算法 \(2\):
枚举中间点(包括字符与字符之间的空隙),根据回文串的性质,向左右两边扩展。如果左右并不相等,立即结束并更新答案;否则将左右各推一个字符,当前答案自增。时间复杂度 \(O(n^2)\)。
但是,此题的数据范围是 \(1\le |S|\le 1.1\times 10^7\)。
Manacher 算法
预处理
Manacher 算法是基于暴力算法 \(2\) 的再优化,由于回文串的对称中心有可能会在两个字符之间的空隙处,所以我们可以插入一些特殊字符,例如 #。为了避免越界,我在字符串开头也插入了一个特殊字符 !。
下标从 \(1\) 开始。
由于格式影响,代码中与 \(\LaTeX\) 公式相冲突的字符改为了 !。
scanf("%s",stri);
int l=strlen(stri);
str[0]='!';
for(int i=0;i<l;i++)
{
str[i*2+1]='#';
str[i*2+2]=stri[i];
}
str[l*2+1]='#';
l=l*2+1;
最长回文延伸长度
以 \(i\) 为中心的最长回文延伸长度,记作 \(p[i]\)。
例如,字符串 abaaabaa 的 p 数组:
| a | b | a | a | a | a | b | a | a | |
|---|---|---|---|---|---|---|---|---|---|
| \(p[i]\) | \(1\) | \(2\) | \(1\) | \(2\) | \(2\) | \(1\) | \(3\) | \(1\) | \(1\) |
注意一个字符也算回文串,所以 \(p[i]\) 的最小值为 \(1\)。
可以知道,对于每个位置 \(i\),以 \(i\) 为中心的最长回文串的起始位置为 \(i-p[i]+1\),结束位置为 \(i+p[i]-1\)。
算法流程
由于回文串在回文中心左右的部分完全对称,我们可以考虑从这一点来优化算法,进行递推。Manacher 算法的递推方向就是从左到右。(下标从 \(1\) 开始)
\(1\):最理想的情况
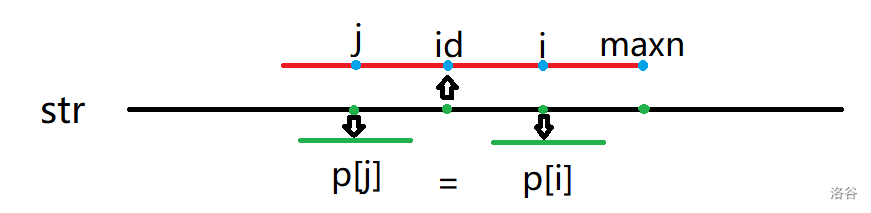
(自绘插图,略显粗糙)
如图,\(maxn\) 表示目前求出的回文串中最远延伸的点,而 \(id\) 表示这个字符串的对称中心。点 \(i\) 是我们正在求的点,点 \(j\) 是关于 \(mid\) 的对称点。由回文串的对称性可以得出 \([id-p[id]+1,id]\) 和 \([id,id+p[id]-1]\) 两段一定完全相等,进一步推出以 \(j\) 为回文中心的串一定与以 \(i\) 为回文中心的串完全相等,所以 \(p[i]=p[j]\)。
因为 \(j\) 一定在 \(i\) 之前,符合递推的条件。\(j\) 的坐标可以 \(O(1)\) 求出,由坐标中点公式得出 \(j=id\times 2-i\),整个这种情况下的转移就可以 \(O(1)\) 实现了。
\(2\):不是很理想的情况
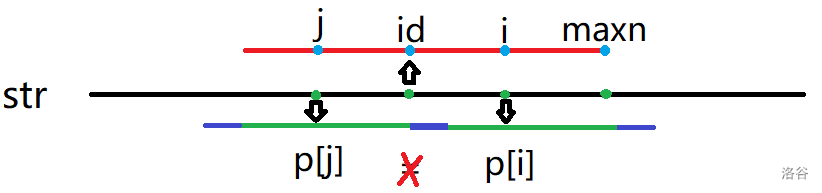
\(p[j]\) 出界的部分不能保证与 \(p[i]\) 出界的部分完全相同,此时 \(p[i]\) 不一定等于 \(p[j]\)。但是我们可以知道在 \([id-p[id]+1,id+p[id]-1]\) 这个范围内的部分完全相等,也就是说,在不超过这个范围的部分,以 \(j\) 为回文中心的串一定与以 \(i\) 为回文中心的串完全相等,观察以下图,其实就是 \(maxn-i+1\)。剩下的,就朴素吧。
由于每次朴素之后会把 \(maxn\) 往后推,所以时间复杂度还是 \(O(n)\)。
\(3\):很不理想的情况

无能为力了,只能朴素了。由于每次朴素之后会把 \(maxn\) 往后推,所以时间复杂度还是 \(O(n)\)。
具体实现的时候,可以首先判定是否为情况 \(3\),然后可以直接用一个 \(min\) 函数处理出情况 \(1\) 和情况 \(2\)。因为当处于情况 \(2\) 时,情况 \(2\) 的数值小于情况 \(1\);而处于情况 \(1\) 时,情况 \(1\) 的数值小于情况 \(2\)。最后在结合插入字符,朴素比较即可,注意更新 \(maxn\) 和 \(id\)。
这里实现时,\(maxn\) 的值是 \(i+p[i]\),是可以取到的最后一个位置的后一个位置,是不能取到的。所以代码中才写 \(maxn>i\),\(maxn-i\),这样写是为了节约一点点码量,但实际中不建议这么写,容易被误解。
p[1]=1;maxn=0;id=0;
for(int i=1;i<=l;i++)
{
if(maxn>i)p[i]=min(p[id*2-i],maxn-i);
else p[i]=1;
while(str[i-p[i]]==str[i+p[i]])p[i]++;
if(i+p[i]>maxn)maxn=i+p[i],id=i;
}
由于插入字符的影响,我们注意到 \(p[i]-1\) 就是以 \(i\) 为中心的最长回文子串的长度,直接遍历一遍求最大值,就在 \(O(n)\) 的时间内解决了问题。
例题
例题 \(1\) :
Manacher 模板题,不多赘述。
#include <bits/stdc++.h>
using namespace std;
int p[22000010],maxn=0,id=0,ans=0;
char stri[11000010],str[22000010];
int main()
{
scanf("%s",stri);
int l=strlen(stri);
str[0]='!';
for(int i=0;i<l;i++)
{
str[i*2+1]='#';
str[i*2+2]=stri[i];
}
str[l*2+1]='#';
l=l*2+1;
p[1]=1;maxn=0;id=0;
for(int i=1;i<=l;i++)
{
if(maxn>i)p[i]=min(p[id*2-i],maxn-i);
else p[i]=1;
while(str[i-p[i]]==str[i+p[i]])p[i]++;
if(i+p[i]>maxn)maxn=i+p[i],id=i;
}
for(int i=1;i<=l;i++)
ans=max(p[i]-1,ans);
printf("%d",ans);
return 0;
}
例题 \(2\) :
看到题目中提到了回文串,自然联想到 Manacher 算法。
首先,如果一个回文串的长度为 \(n\)(\(n\) 为奇数且 \(n\ge1\)),则这个串同样也可以算作一个长度为 \(n-2\) 的回文串。因为这个回文串可以删去其最左右两边的两个字符,变成长度为 \(n-2\) 的串。由于原串是回文串,所以删去的字符相同,新串依旧是回文串。
有了这点,我们很容易得到一个思路:首先求出每个位置的最长回文子串,用一个桶记录下来。然后降序枚举(保证从高到低)最长回文子串长度,并进行数量累加,结果累乘,然后用快速幂求出值即可。
#include <bits/stdc++.h>
using namespace std;
long long p[2000020],t[2000020],maxn=0,id=0,ans=1,l=0,k=0,tj=0,tu=0,now=0,mod=19930726;
char stri[1000010],str[2000020];
long long power(long long a,long long p,long long m)
{
long long x=a,ans=1;
while(p)
{
if(p%2==1)ans=ans*x%m;
p/=2;
x=x*x%m;
}
return ans;
}
int main()
{
scanf("%lld%lld",&l,&k);
scanf("%s",stri);
str[0]='!';
for(int i=0;i<l;i++)
{
str[i*2+1]='#';
str[i*2+2]=stri[i];
}
str[l*2+1]='#';
l=l*2+1;
p[1]=1;maxn=0;id=0;
for(int i=1;i<=l;i++)
{
if(maxn>=i)p[i]=min(p[id*2-i],maxn-i);
else p[i]=1;
while(str[i-p[i]]==str[i+p[i]])p[i]++;
if(i+p[i]>maxn)maxn=i+p[i],id=i;
}
for(int i=1;i<=l;i++)p[i]--;
for(int i=1;i<=l;i++)t[p[i]]++;
for(int i=1000020;i>0;i--)
{
if(i%2==1)
{
tj+=t[i];
if(tj==0)continue;
if(now+tj<=k)ans=ans*power(i,tj,mod)%mod,now+=tj;
else
{
ans=ans*power(i,k-now,mod)%mod;
printf("%lld",ans);
return 0;
}
}
}
return 0;
}
例题 \(3\) :
由翻转操作的定义,得知翻转后的字符串一定是长度为奇数的回文串,再次联想到 Manacher。由于回文串长度为奇数,所以不用在空隙处插入字符。
性质 \(1\):如果一个位置 \(i\),其最长回文串延伸到字符串末尾,那么这个位置一定可以取到。
证明:
设字符串为 \(S\),如果这个位置可以取到,最终翻转形成的串一定为 \(Q+S_i+Q\)(\(Q\) 为 \(i\) 前所有字符组成的字符串)。因为其最长回文串延伸到字符串末尾,设不算位置 \(i\) 的单边的回文部分为 \(H\),则原字符串可以写作:(\(Q_0=Q-H\))
\]
最终翻转形成的串可以写作:
\]
因为给出的字符串可以是最终翻转形成的字符串的前缀,对比二式发现给出的字符串一定为最终翻转形成的字符串的前缀,所以这个位置可以取到,结论得证。
性质 \(2\):在不属于性质 \(1\) 的前提下,如果一个位置 \(i\),其最长回文串向左延伸到字符串第一个字符,向右延伸到可以取到的位置,那么这个位置一定可以取到。
证明:
由于不属于性质 \(1\),所以必须回文串从头开始,否则无法保证回文部分之前的字符与之后的字符完全相等,所以要求最长回文串向左延伸到字符串第一个字符。
如果最长回文串向右延伸到可以取到的位置,那么相当于再翻转后的字符串是符合要求的,所以这个能翻转出符合要求的字符串的位置也是符合要求的。又因为最长回文串向左延伸到字符串第一个字符,所以不会对再翻出的符合要求的字符串造成影响,结论得证。
因此,我们可以结合上面两条性质,从右往左进行递推。对于每一个点,首先判断其是否符合性质 \(1\),然后判断其是否符合性质 \(2\)。同时为了方便计算性质 \(2\),可以用一个数组记录每个位置是否可行。最后遍历一遍,输出可行的位置即可。
upd on 2024/8/9:更新了代码,原本的代码会被 hack。
#include <bits/stdc++.h>
using namespace std;
long long t,p[6000000],maxn=0,id=0,ans=0,book[6000000];
char s[6000000];
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%s",s+1);
s[0]='$';
long long l=strlen(s);
for(int i=1;i<=l;i++)p[i]=book[i]=0;
s[l+1]='#',l--,p[1]=1,maxn=0,id=0;
for(int i=1;i<=l;i++)
{
if(maxn>i)p[i]=min(p[id*2-i],maxn-i);
else p[i]=1;
while(s[i-p[i]]==s[i+p[i]])p[i]++;
if(i+p[i]>maxn)maxn=i+p[i],id=i;
}
for(int i=l;i>0;i--)
if(i+p[i]==l+1)book[i]=1;
else if(i==p[i])book[i]=book[i+p[i]-1];
for(int i=1;i<=l;i++)
if(book[i])printf("%d ",i);
printf("\n");
}
return 0;
}
后记
算法只是工具,现在很少直接考单纯的算法。Manacher 的题目重要的不是 Manacher 算法本身,而是其后的思维难度。——教练
【7】Manacher算法学习笔记的更多相关文章
- Manacher算法学习笔记 | LeetCode#5
Manacher算法学习笔记 DECLARATION 引用来源:https://www.cnblogs.com/grandyang/p/4475985.html CONTENT 用途:寻找一个字符串的 ...
- Manacher算法学习笔记
前言 Manacher(也叫马拉车)是一种用于在线性时间内找出字符串中最长回文子串的算法 算法 一般的查找回文串的算法是枚举中心,然后往两侧拓展,看最多拓展出多远.最坏情况下$O(n^2)$ 然而Ma ...
- Manacher 算法学习笔记
算法用处: 解决最长回文子串的问题(朴素型). 算法复杂度 我们不妨先看看其他暴力解法的复杂度: \(O(n^3)\) 枚举子串的左右边界,然后再暴力判断是否回文,对答案取 \(max\) . \(O ...
- C / C++算法学习笔记(8)-SHELL排序
原始地址:C / C++算法学习笔记(8)-SHELL排序 基本思想 先取一个小于n的整数d1作为第一个增量(gap),把文件的全部记录分成d1个组.所有距离为dl的倍数的记录放在同一个组中.先在各组 ...
- Johnson算法学习笔记
\(Johnson\)算法学习笔记. 在最短路的学习中,我们曾学习了三种最短路的算法,\(Bellman-Ford\)算法及其队列优化\(SPFA\)算法,\(Dijkstra\)算法.这些算法可以快 ...
- 某科学的PID算法学习笔记
最近,在某社团的要求下,自学了PID算法.学完后,深切地感受到PID算法之强大.PID算法应用广泛,比如加热器.平衡车.无人机等等,是自动控制理论中比较容易理解但十分重要的算法. 下面是博主学习过程中 ...
- Johnson 全源最短路径算法学习笔记
Johnson 全源最短路径算法学习笔记 如果你希望得到带互动的极简文字体验,请点这里 我们来学习johnson Johnson 算法是一种在边加权有向图中找到所有顶点对之间最短路径的方法.它允许一些 ...
- 算法学习笔记(5): 最近公共祖先(LCA)
最近公共祖先(LCA) 目录 最近公共祖先(LCA) 定义 求法 方法一:树上倍增 朴素算法 复杂度分析 方法二:dfs序与ST表 初始化与查询 复杂度分析 方法三:树链剖分 DFS序 性质 重链 重 ...
- 算法学习笔记(3): 倍增与ST算法
倍增 目录 倍增 查找 洛谷P2249 重点 变式练习 快速幂 ST表 扩展 - 运算 扩展 - 区间 变式答案 倍增,字面意思即"成倍增长" 他与二分十分类似,都是基于" ...
- Miller-Rabin 与 Pollard-Rho 算法学习笔记
前言 Miller-Rabin 算法用于判断一个数 \(p\) 是否是质数,若选定 \(w\) 个数进行判断,那么正确率约是 \(1-\frac{1}{4^w}\) ,时间复杂度为 \(O(\log ...
随机推荐
- 大模型微调实战:通过 LoRA 微调修改模型自我认知
本文主要分享如何使用 LLaMAFactory 实现大模型微调,基于 Qwen1.5-1.8B-Chat 模型进行 LoRA 微调,修改模型自我认知. 本文的一个目的:基于 Qwen1.5-1.8B- ...
- ESP-IDF教程2 GPIO - 输入、输出和中断
1.前提 1.1.基础知识 1.1.1.GPIO 分类 ESP32 系列芯片按照 GPIO 特殊的使用限制分类,可以将其分为如下几类: GPIO PIN GPI PIN Strapping PIN S ...
- element-ui $prompt输入弹框和$confirm确认弹框用法--输入框默认值、校验、阻止关闭等问题
可输入弹框 $prompt 1.默认值.校验 this.$prompt( '请输入文件夹名称:', '提示', { confirmButtonText: '确定', cancelButtonText: ...
- java 单链表实现栈
package com.company;public class Main { //用链表模拟栈 public static void main(String[] args) { // write y ...
- Qt 官网开源最新版下载安装保姆级教程【2024-8-4 更新】
➤ 什么是Qt(了解请跳过) ➥ Qt 基本介绍 时至今日,Qt 已经经历了诸多变化.并且在未来,它也会不断地更新迭代.所以如果你想要更准确地了解 Qt,应该通过以下几种方法: ① 官方介绍 根据官方 ...
- SpringBoot静态资源访问--转载
转载地址:https://www.jianshu.com/p/d40ee98b84b5
- HarmonyOS NEXT开发实战案例--圆盘
这是之前写过的一个项目,后来删掉了,现在适配到api12重新发布,友友们按需查阅. 本文主要通过抽奖转盘小项目讲解在鸿蒙开发中如何使用画布组件Canvas绘制图形和文字,以及转圈动画的实现.效果图如下 ...
- 神经网络-反向传播BP算法推导
还是用前向算法的图, 然后仔细一看分类输出, 发现好像错了, 这该如何去反向修改权值呢? 因其是网络结构, 改变一点, 必然会引起一连串的改动, 这个过程, 如何来描述呢? 数学推导 声明变量 首先, ...
- 使用HuggingFace 模型并预测
下载HuggingFace 模型 首先打开网址:https://huggingface.co/models 这个网址是huggingface/transformers支持的所有模型,目前大约一千多个. ...
- ✨生物大语言模型Evo2——解码基因密码的AI革命🚀
2025:生物AI的"DeepSeek时刻" 当整个中文互联网为国产大语言模型DeepSeek欢呼时,生命科学界正悄然掀起一场静默革命--由Arc Institute领衔,斯坦福. ...